成为VIP会员查看完整内容
VIP会员码认证
首页
主题
发现
会员
服务
注册
·
登录
信息抽取
关注
350
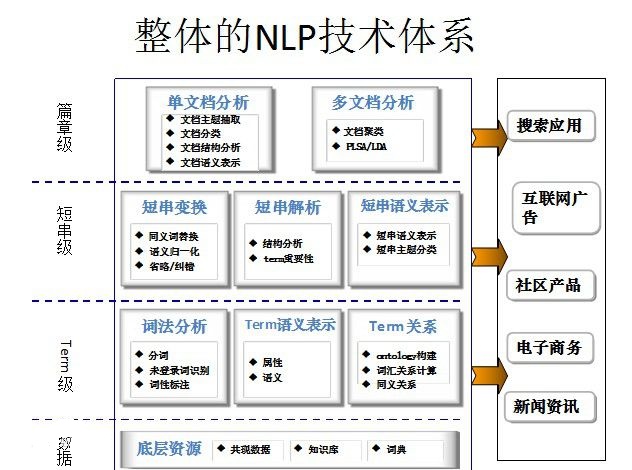
信息抽取 (Information Extraction: IE)是把文本里包含的信息进行结构化处理,变成表格一样的组织形式。输入信息抽取系统的是原始文本,输出的是固定格式的信息点。信息点从各种各样的文档中被抽取出来,然后以统一的形式集成在一起。这就是信息抽取的主要任务。信息以统一的形式集成在一起的好处是方便检查和比较。 信息抽取技术并不试图全面理解整篇文档,只是对文档中包含相关信息的部分进行分析。至于哪些信息是相关的,那将由系统设计时定下的领域范围而定。
综合
百科
VIP
热门
动态
论文
精华
TEXT2DB: Integration-Aware Information Extraction with Large Language Model Agents
Arxiv
0+阅读 · 10月30日
AgenticIE: An Adaptive Agent for Information Extraction from Complex Regulatory Documents
Arxiv
0+阅读 · 10月7日
LLM-Based Information Extraction to Support Scientific Literature Research and Publication Workflows
Arxiv
0+阅读 · 10月6日
RealKIE: Five Novel Datasets for Enterprise Key Information Extraction
Arxiv
0+阅读 · 10月6日
Unveiling the Deficiencies of Pre-trained Text-and-Layout Models in Real-world Visually-rich Document Information Extraction
Arxiv
0+阅读 · 4月14日
Deep Learning based Key Information Extraction from Business Documents: Systematic Literature Review
Arxiv
0+阅读 · 7月18日
BI-RADS prediction of mammographic masses using uncertainty information extracted from a Bayesian Deep Learning model
Arxiv
0+阅读 · 3月24日
Joint Extraction Matters: Prompt-Based Visual Question Answering for Multi-Field Document Information Extraction
Arxiv
0+阅读 · 3月21日
Low-resource Information Extraction with the European Clinical Case Corpus
Arxiv
0+阅读 · 3月26日
KIEval: Evaluation Metric for Document Key Information Extraction
Arxiv
0+阅读 · 3月7日
KIEval: Evaluation Metric for Document Key Information Extraction
Arxiv
0+阅读 · 3月26日
Achievable Rates for Information Extraction from a Strategic Sender
Arxiv
0+阅读 · 2月28日
Problem Solved? Information Extraction Design Space for Layout-Rich Documents using LLMs
Arxiv
0+阅读 · 2月25日
Evaluating LLM-based Personal Information Extraction and Countermeasures
Arxiv
0+阅读 · 1月31日
Evaluating LLM-based Personal Information Extraction and Countermeasures
Arxiv
0+阅读 · 1月30日
参考链接
父主题
自然语言处理应用研究
子主题
命名实体识别
实体消岐
事件抽取
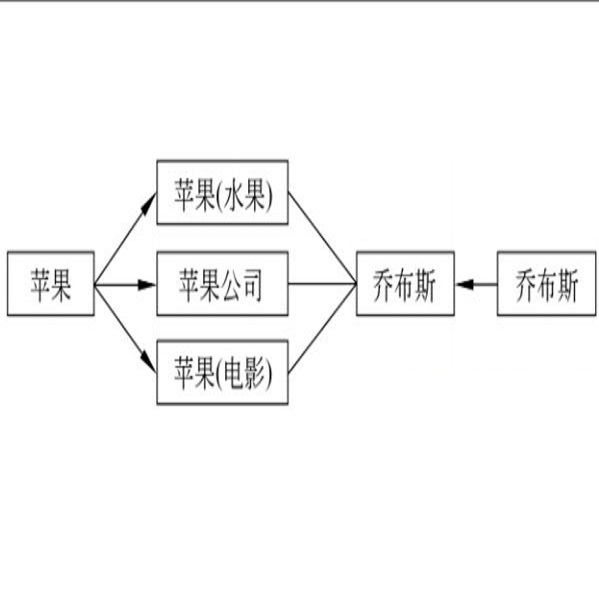
命名实体消歧
命名实体链接
关系抽取
提示
微信扫码
咨询专知VIP会员与技术项目合作
(加微信请备注: "专知")
微信扫码咨询专知VIP会员
Top