我在谷歌大脑见习机器学习的一年:Node.js创始人的尝试笔记

大数据文摘作品
编译:王一丁、于乐源、Aileen
本文作者Ryan Daul是Node.js的创始人,应该算是软件工程领域当之无愧的大犇了。他和我们分享了自己在谷歌大脑见习项目一年中的工作,成果,失败和思考。
去年,在通过对TensorFlow的研究得出一点点心得之后,我申请并入选了谷歌大脑举办的的首届见习项目(Google Brain Residency Program)。该项目共邀请了24名在机器学习领域有着不同背景的人士,受邀者将在为期一年的时间里和Google的科学家及工程师们在位于山景城的Google深度学习研究实验室中共同探索最前沿的深度学习科技。
这个为期一年的项目已经结束了,在此我将就这一年的经历作一个总结与分享。
最初拟定的目标是“修正”老电影或电视剧的画面。想象一下,上世纪90年代电视剧的粗糙画面或60年代的黑白电影,在色彩华丽的4K屏幕上播放的情景。
这应该是完全可行的:把4K视频转换成满是颗粒感的、低分辨率的、甚至是只有黑白两色的视频并不难,之后再通过某个训练出的监督模型来反转这个过程就可以“修正”了。而且,有数不尽的数据训练集,很棒不是吗!
先别急着兴奋——因为能做这事儿的技术还没有出现......不过我们确实离目标越来越近了。
为了更好地实现这个目标,以科技之名,我再一次搬离了布鲁克林来到了湾区。几天后我的日常生活就变成了与Google的机器学习专家进行讨论以及在庞大的软件架构中四处探索。
如果你想跳过技术细节,可以直接跳到总结部分。

本文作者Ryan Daul开发了Node.js,一个流行的前端框架
超分辨率的像素递归
众所周知,在美剧《CSI犯罪现场》中使用的缩放技术在现实中并不存在,你无法将照片放大到任意倍数。但可行的是,在放大照片的同时将像素可能构成的合理图形进行推测并呈现,这也是实现我目标的第一步–逆向提高图片的分辨率。
在文献中,这一问题被称之为“超分辨率”问题,是一个科学家们尝试了很久都没有解决的难题。
根据以往的经验,我们认识到只是训练一个卷积模型最小化低分辨率图像与高分辨率图像的平均像素差值无法彻底地解决这一问题。因为这一类模型训练的目的是平均化输入图像和目标图像的整体差值,这就导致了生成的图片非常模糊。
对我们而言,理想模型应该针对不同区域做出一个最佳的选择,尽可能的对细节做出全方位的优化。比如说,输入一张模糊的树的图片,我们希望我们的模型能分别对树的躯干、树枝、树叶进行优化,哪怕原图中没有相应的细节也没有关系。
起初,我们打算用条件型生成对抗网络(conditional GAN)来解决这个问题,但经过几次失败的尝试后,我们换成了另一种有望解决该问题的新型生产式模型——PixelCNN。(换成PixelCNN不久,SRGAN就发布了,它用GAN来解决超分辨率问题并能输出相当不错的结果。)
PixelCNN和传统的卷积神经网络十分不同,它将图像生成问题转化成了一个像素序列选择问题。核心思想借鉴与于LSTM(长短时记忆网络)这样的门控递归网络,尽管他们通常被应用于单词或字符序列的生成上,但无可否认效果是非常好的。PixelCNN巧妙地构建出一个卷积神经网络(CNN),它能基于先前的像素的概率分布来生成下一个像素,也就是说同时具备了序列模型和卷积神经网络的特点。
van den Oord 等人所绘
让我没想到的是,通过PixelCNN生成的图像看起来非常自然。与对抗网络试图在生成与鉴别中找到一个精确的平衡不同,PixelCNN的目标只有一个,所以面对超参数的变化,它有更好的稳健性,也更容易被优化。
对于用PixelCNN解决超分辨率问题的首次尝试,我试图用ImageNet提供的图片进行训练,但事实证明这个目标还是有些太高了。(相较于很多生成式模型使用的CIFAR-10、CelebA或LSUN数据集,ImageNet更加的复杂)我很快地就发现——像素来序列生成图像的过程极其缓慢。
当输出图像的尺寸大于64x64时,生成一张图片的耗时超过数个小时!但当我降低了输出图像的尺寸并使用脸部或卧室类的小型数据集后,就开始慢慢得到了一些振奋人心的结果了。

用名人脸部图像数据集训练出来的超分辨率像素递归模型所生成的高分辨率图像。
左侧为测试数据集所用的8x8低分辨率输入图像。中间为PixelCNN模型所输出的32x32高分辨率图像,右侧是原始的32x32分辨率图像。我们的模型优先整合脸部特征,而后去合成较为逼真的头发与皮肤方面的细节。
就计算资源而言,在Google不会因GPU或CPU的数量而受限,所以如何扩大训练的规模便成为该项目的另一个目标——因为即便采用这些小型的数据集,在单个GPU上完成训练也要花上数周的时间。
异步随机梯度下降(Asynchronous SGD)是最理想的分布式训练方法。使用这种方法,你可以用N台机器,每一台都独立训练同一模型,并在每个时间步长共享一次权重参数。
权重参数被托管在一台单独的“参数服务器”上,该服务器在每个时间步长内都进行“远程过程调用(RPC)”,以获得最新数值并发送梯度更新。
如果整个数据流非常顺畅,就可以通过增加线程的方式线性增加模型每秒内的训练次数。但因为每个线程都是独立训练的,随着线程数的增加会越来越容易导致在当前线程还没有完成一次训练或更新时,它所使用的权重就已经过期了。
如果是为了解决分类问题,这对神经网络的影响不大,把训练的规模扩增到几十台机器不难。但PixelCNN却对过时的梯度极其敏感,这就导致了通过增加硬件的数量来使用异步随机梯度下降算法所带来收益微乎其微。
另一个方法,是用同步随机梯度下降算法(Synchronous SGD)。使用这一方法,所有线程在每个时间步长内进行同步,每次下降的梯度会被平均,这保证不会出现权重过期的问题。
从数学的角度看,它与随机梯度下降算法是一样的,既机器越多,批处理能力越强。但同步随机梯度下降算法(Sync SGD)的优势是,它允许各线程使用更小、更快的批尺寸,从而来增加每秒训练的次数。
但同步随机梯度下降算法也有自己的问题:首先,它需要大量的机器经常进行同步,这就无可避免的会导致停机时间的增加;其次,除非将每台机器的批尺寸设为1,否则它无法通过增加机器的数量来增加每秒训练的次数。最终,我发现对我而言最简单有效的设置是用一台8GPU的机器使用同步随机梯度下降算法进行训练,即便如此每次训练仍需花上数天的时间。
拥有大量计算能力的另一好处是可以对超参数的优化进行大规模的暴力搜索。不确定该使用什么样的批尺寸进行训练?挨个试一遍!在找到论文中所用的配置前,我曾尝试过数百种配置。
另一个难题是如何量化评估结果。如何才能证明我们的图像比基准模型更好?衡量超分辨率效果的传统方法,是对比输出图像与原始图像在对应像素点之间的距离(峰值信噪比,PSNR)。
虽说我们的模型输出的脸部图像在质量上明显更好,但在像素对比上,平均看来还不如基准模型所输出的模糊图像。我们还尝试用PixelCNN本身的相似度测量来证明我们的样本比基准版本有着更佳的像素分布,但同样失败了。最后,我们把这项任务交给了大众——询问参与调查的人哪些图像看上去更真实,这才证明了我们模型的价值。
超分辨率的像素递归论文:
https://arxiv.org/abs/1702.00783
PixColor:着色问题的另一次尝试

PixColor输出的双色模式
Slim的创造者Sergio Guadarrama一直在研究图像着色问题,他曾和我描述过这样一个试验:获取一张224×224×3的图像,将其置于YPbPr色彩空间中(该空间图像的灰度、颜色相互分离),首先将颜色通道降至28×28×2的超低分辨率,再用双线性插值法再把颜色通道放大,所得图像与高色彩分辨率的原始图像相比几乎没有差别。

你需要的只是几种颜色。顶行是原始彩色图像;中间是降低并采样后的色度图像,尺寸缩小至28像素;底行是双线性提高中间行的采样率并结合原始灰度图像的结果。
这一现象表明,着色问题可以简化成低分辨率颜色预测问题。我原本已准备好彻底放弃PixelCNN了,因为显然它无法输出大尺寸的图像,但转念一想其用来生成28×28×2的图像还是很可行的,并最终通过使用4位颜色数值而非8位,进一步的简化了着色问题。
Sergio构建了一个“美化”神经网络,它能美化低分辨率颜色的图像,并将溢出边界的颜色推回至正确位置–构造仅仅是使用L2损失函数将图片与图片进行比较。我们还用一个预训练好的ResNet作为辅助神经网络,以避免需要额外添加一个新的损失函数的需求,这中做法我们在超分辨率项目中就使用过。
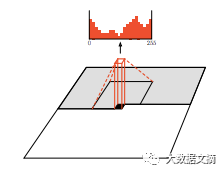
通过以上所有技巧,不论是通过大众评估还是颜色直方图交叉测量,我们能够在ImageNet的训练集上实现最佳的结果。事实证明,一个训练好的PixelCNN模型产生的图像具有良好的数据分布性,而且没有发生过任何模型崩溃的问题。
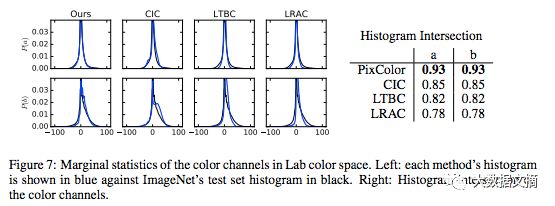
Lab颜色空间中的颜色通道的边缘统计数据。左:每种测试方法的直方图以蓝色显示,ImageNet的测试数据集直方图以黑色显示。右图:左图颜色通道的相交比例
由于模型为每个灰度输入的可能着色声明了一个概率分布,我们可以对该分布进行多次取样,以获取同一输入的不同着色。下图用结构相似度(SSIM)很好地展示了分布的多样性:
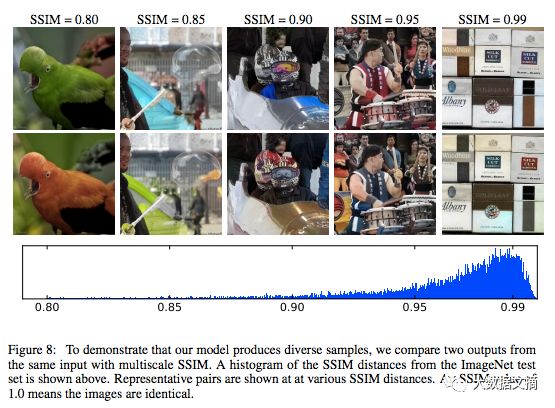
为证明我们的模型可生成不同的样本,我们用多尺度SSIM对比了同一输入的两种输出。上图显示了ImageNet测试数据集的SSIM距离直方图。图中在多个SSIM间距上分别显示了每对图像。SSIM值为1表示两张图像完全相同。
该模型还远称不上“完美”,因为ImageNet尽管庞大,但不能代表所有的图像。我们的模型在处理非ImageNet图像时并不理想。真实的黑白照片(不同于彩色照片转化出的黑白照片)会得出许多不同的分布数据,也会出现很多彩色照片中所没有的物体。比如,Model T汽车的彩色照片不多,ImageNet图像集中可能一张都没有。或许采用更大的数据集和更好的数据扩增方法可以改善这些问题。
如果想了解输出图像的质量,可以来看看这些图:
当我们模型处于训练中期时处理的一小组非常难处理的图像:
http://tinyclouds.org/residency/step1326412_t100/index.html
用我们的模型处理ImageNet上的随机数据集:
http://tinyclouds.org/residency/rld_28px3_t100_500_center_crop_224/
作为对比,下面是用其他算法来处理同一ImageNet测试数据集的结果:
http://hi.cs.waseda.ac.jp/~iizuka/projects/colorization/en/
http://richzhang.github.io/colorization/
http://people.cs.uchicago.edu/~larsson/colorization/
所有完整的细节都可以在我们的论文中找到:
https://arxiv.org/abs/1705.07208
失败与未报告的实验结果
这一年期间,我曾间歇性地投入过许多业余的小项目,尽管它们都没成功,但其中有几个值得一提的项目:
大数的素因数分解
素因数分解一向都是个难题,尽管近期在素数分布领域又有了突破,也依旧很有挑战性。我们的想法是,如果为神经网络提供足够多的训练样本,看看它能否找出一些新的东西?
Mohammad和我尝试过两种方法:他修改了Google机器翻译的seq2seq模型,该模型把一个半素大数的整数序列作为输入,并以预测其素因数中的一个做为输出;我则使用一个较为简单的模型,它将定长整数作为输入,并用几个全连接层来预测输入的分类:素数或合数。
但这两种方法最后都只学到了最为明显的规律(如果尾数为0,那它就不是素数!),最后我们只能抛弃这个想法。
对抗做梦
受Michael Gygli的项目启发,我想看看能否用一个鉴别器充当它自己的生成器。为此,我构建出一个简单的二元分类卷积神经网络来判断输入的真假。
Michael Gygli的项目:
https://arxiv.org/abs/1703.04363
既给出一张噪点图片并让它使用梯度自我更新来生成图像(也称为deep dreaming),训练的目标是令该网络把“真实”类别的输出达到最大化。该模型通过交替生成“假”实例来进行训练,跟典型的GAN中的鉴别器一样,通过升级权重来区分真假实例。
起初我的想法是,因为这个模型不需要像GAN那么复杂的架构设计,所以应该会极大地降低训练的难度。而事实上,这个模型在MNIST数据集上的确输出了不错的结果,如下栏所示:每一纵列都是由噪音图片一步步推进成为红色的MNIST数值。

但我没法在CIFAR-10 数据集上达到同样的效果,并且它的实用性也极为有限。很遗憾,因为我觉得“对抗做梦(Adversarial Dreaming )”将会是一个很酷的论文标题。
使用PixelCNN来训练生成器
鉴于PixelCNN训练一次需要很长的时间,我便想试试能不能用一个训练好的PixelCNN模型训练出前馈式、图像对图像卷积神经网络生成器(8x8至32x32尺寸的LSUN卧室图片集)。我所设置的训练方法是:在前馈式网络的输出上进行自动回归,在PixelCNN下更新权重以便将两张图片的相似率最大化。但这个设计失败了,它生成了非常奇怪的图像:

探索“异步随机梯度下降”的改进方法
如前所述,很多模型都不适用于异步随机梯度下降算法。最近,一篇名为DCASGD的论文提出了一种解决过时梯度问题的可能方法——在每一个线程更新自己的权重时使用差分向量。如果可以实现,这种方法可以大大减少每次需要的训练时间。不幸的是,我没能在TensorFlow上复原他们的结果,也就无法尝试我基于此方法的几个设想,可能还是哪里有Bug。
DCASGD的论文:
https://arxiv.org/abs/1609.08326
思考,结论

作为软件工程师,我在机器学习方面并没有什么经验。但基于过去一年对深度学习的研究,我想说一下对该领域的总体看法,以及与范围更广的软件领域之间的关系。
我坚信,机器学习将改变所有行业,并最终改善每个人的生活,许多行业都会因机器学习的发展而受益。我相信我在这个项目中尝试的超分辨率问题在不久的将来就会被解决,所有人都可以看到查理·卓别林这类老电影的4K版。
不过,我确实发现,这一模型的构建、训练和调试都相当困难。当然,大部分的困难是由于我缺乏经验,这也表明有效训练这些模型是需要相当丰富的经验的。我的工作集中在机器学习最为容易的分支上:监督式学习。但即便有着完美的标记数据,开发模型可能仍然十分困难。
一般情况就是预测的维度越大,构建模型所花的时间就越长(例如:花大把的时间进行编程、调试和训练)。基于我的经验,建议所有人在开始时都尽可能的简化和限制你的预测范围。
举一个我们在着色实验中的例子:我们在开始时试图让模型预测整个RGB图像,而非只去预测颜色通道。最开始的想法是,因为我们使用的是跳跃连接(skip connection),所以神经网络应该容易就能处理好灰度图并输出可观的结果。后来,我们通过只预测颜色通道这一做法极大的提高了模型的性能。
如果我用“工作”这一词的直观意义来描述软件的话,那么图像分类任务似乎“工作”的很稳健;生成式模型几乎很少能“工作”,人们也不太了解这种模型,GAN能输出高质量图像,但同时却极难构建起来。我的经验是,对GAN的架构作出任何小改动都有可能使它完全无法工作。我听说强化学习与其相比更加困难,但因经验不足,在此就不作评价了。
另一方面,随机梯度下降算法的性能十分强大,即使是严重的数学错误,可能也只是会使结果有一些失真,而不至于产生严重的偏差。
因为训练模型经常需要花费很多天,这是一个非常缓慢的修改—运行循环。
机器学习领域的测试文化尚未完全兴起。训练模型时我们需要更好的评断方法,例如网络的多个组成部分需要维持特定的均值和变量,不能过度摆动超出界定的范围。机器学习的bug使heisenbugs一类的漏洞很轻松地通过了我写的测试。
并行化(Parallelization)能带来的好处很有限。增加计算机数量使大规模的超参数搜索会变得更加容易,但理想情况下,我们会设计不用特别仔细调试也能很好运转的模型。(实际上,我怀疑超参数搜索能力有限的研究人员将不得不设计出更好的模型,因此他们设计出的模型更加稳定)。
不好的是,对于很多模型而言,异步随机梯度下降算法并没有什么用处——更加精确的梯度通常用处不大。这就是为什么 DCASGD 的研究方向很重要的原因。
从软件维护的角度看,关于如何组织机器学习项目大家鲜有共识——就像是Rails出现之前的网站:一群随机PHP脚本,商业逻辑和标记符号乱写一气。在TensorFlow项目中,数据通道、数学和超参数等配置无组织地混为一团。
我认为精美的机器学习类项目的结构/组织还未被发现(或者说是还未被重新发现,就像DHH重新发现并普及 MVC那样)。我的项目结构一直在进步,但我现在还无法将它称之为“精美”。
机器学习的框架会继续快速迭代。我最初使用的是Caffe,后来又不得不称赞TensorFlow带来的好处,而PyTorch 和 Chainer之类的项目现在则使用动态计算图来形吸引客户。
但漫长的“修改 - 运行”循环是开发更好模型的主要阻碍,所以我认为能优先实现快速启动和快速评估的框架最终会取得成功。尽管拥有TensorBoard和iPython之类的有用工具,但是检查模型在训练期间的具体细节仍然很难。
论文中的信噪比很低。但是还有很大的改进空间。人们通常不会坦率承认他们模型的失败之处,因为学术会议更看重的是准确度而不是透明度。我希望学术会议能接受提交博客文章,并要求开源实现,Distill在这方面的努力值得称赞。
对机器学习而言,这是一个令人激动的时代。在各个层面上都有大量工作等待完成:从理论到框架,每一方面都有很多值得改进的空间。它几乎和互联网的诞生一样令人激动,加入这场技术革命吧!
原文链接:
http://tinyclouds.org/residency/
【今日机器学习概念】
Have a Great Definition

志愿者介绍
回复“志愿者”加入我们








