Facebook开源其四层网络负载均衡器Katran

近日,Facebook 开源了 Katran,一个四层网络负载均衡器软件包,已经被用在 Facebook 的网络负载均衡器当中。Katran 是一种基于软件的负载均衡解决方案,利用了两项最新的内核工程创新:eXpress Data Path(XDP)和 eBPF 虚拟机。Katran 被部署在 Facebook 的 PoP 服务器上,用于提高网络负载均衡的性能和可扩展性,并减少在没有数据包流入时的循环等待。
为了管理 Facebook 的流量,他们部署了一个分布式 PoP 服务器作为数据中心的代理。鉴于极高的请求量,PoP 和数据中心都面临着巨大挑战,比如如何将大量的后端服务器作为单一的虚拟单元提供给外部,以及如何在后端服务器之间高效地分配工作负载。
他们为每个位置分配虚拟 IP 地址(VIP),发送到 VIP 的数据包被无缝地分发给后端服务器。在实现分发算法时,需要考虑到后端服务器通常是在应用层处理请求,并且会终结 TCP 连接。于是网络负载均衡器(通常称为第四层负载均衡器或 L4LB)需要负责处理数据包方面的问题。
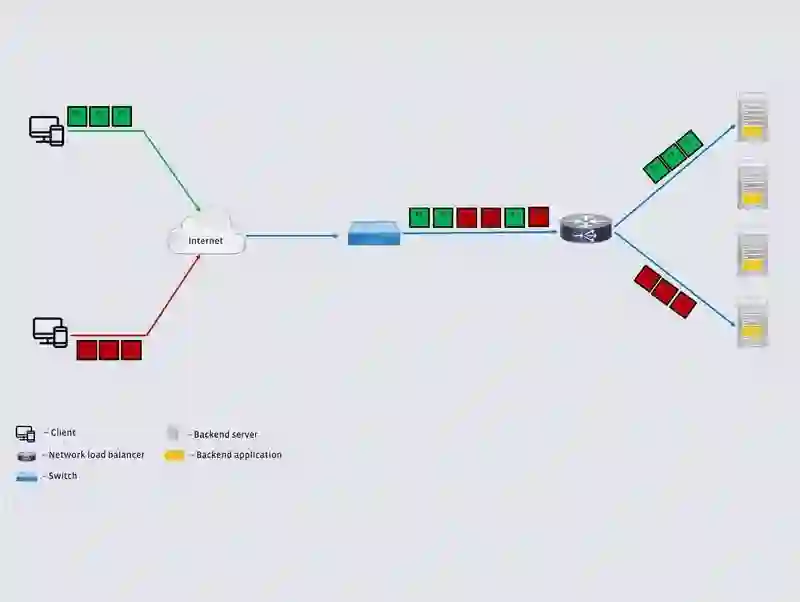
图 1:网络负载均衡器将来自客户端的数据包发送给后端服务器。
L4LB 的性能对降低延迟和扩展后端服务器来说尤其重要,因为 L4LB 需要处理每个传入的数据包。L4LB 的性能通常通过每秒可以处理的数据包峰值(pps)来衡量。一般来说,工程师们首选基于硬件的解决方案,因为这样可以使用加速器,如专用集成电路(ASIC)或可编程门阵列(FPGA)来减轻主 CPU 的负担。然而,基于硬件的解决方案有个缺点,就是它限制了系统的灵活性。为了有效满足 Facebook 的需求,网络负载均衡器必须:
可在商用 Linux 服务器上运行。
与服务器上的其他服务共存。
允许低中断维护。
方便调试。
为了满足这些需求,他们设计了一个高性能的软件网络负载均衡器。第一代 L4LB 基于 IPVS 内核模块,满足了 Facebook 四年多的需求。不过,它与其他服务很难共存,特别是后端服务。在第二次迭代中,他们利用 eXpress 数据路径(XDP)框架和新的 BPF 虚拟机(eBPF)让软件负载均衡器和其他服务运行在一起。
第一代 L4LB 使用了大量的开源组件来实现大部分功能,因此能够在几个月内取代基于硬件的解决方案。该设计有四个主要组成部分:
VIP 发布:该组件通过与位于 L4LB 前面的网络元件(通常为交换机)对等交互向互联发布虚拟 IP 地址。然后,交换机使用等价多路径(ECMP)机制在 L4LB 之间分发数据包。
后端服务器选择:为了将来自某个客户端的所有数据包发送到相同的后端服务器,L4LB 使用了一致性哈希,哈希值取决于传入的 5 元组(源地址、源端口、目标地址、目标端口和协议)数据包。一致性哈希可确保属于相同连接的所有数据包将被发送到相同的后端。
转发面板:一旦 L4LB 选择了合适的后端服务器,数据包将被转发到该服务器。为了突破一些限制,比如 L4LB 与后端主机需要同处于一个 L2 域中,他们使用了简单的 IP-in-IP 封装,这样就可以将 L4LB 和后端主机放置在不同的机架中。他们使用了 IPVS 内核模块,后端服务器的回送接口上配置了相应的 VIP,所以它们可以将返回的数据包直接发送到客户端(而不是 L4LB)。
控制面板:该组件执行其他各种功能,包括对后端服务器执行健康检查,提供简单的接口用于添加或删除 VIP,并提供简单的 API 来检查 L4LB 和后端服务器的状态。
每个 L4LB 还将每个 5 元组保存起来作为查找表,避免重复计算后续数据包的哈希值。这只是一种优化措施,并不会影响到正确性。这种设计符合上述的工作负载要求,但存在一个不足:L4LB 和后端服务共存于同一台设备上增加了设备出现故障的可能性。为此,他们在不相关的一组机器上运行 L4LB 和后端服务。由于 L4LB 数量比后端服务器少,因此更容易受突发流量负载的影响。

图 3:第一代 L4LB 概览
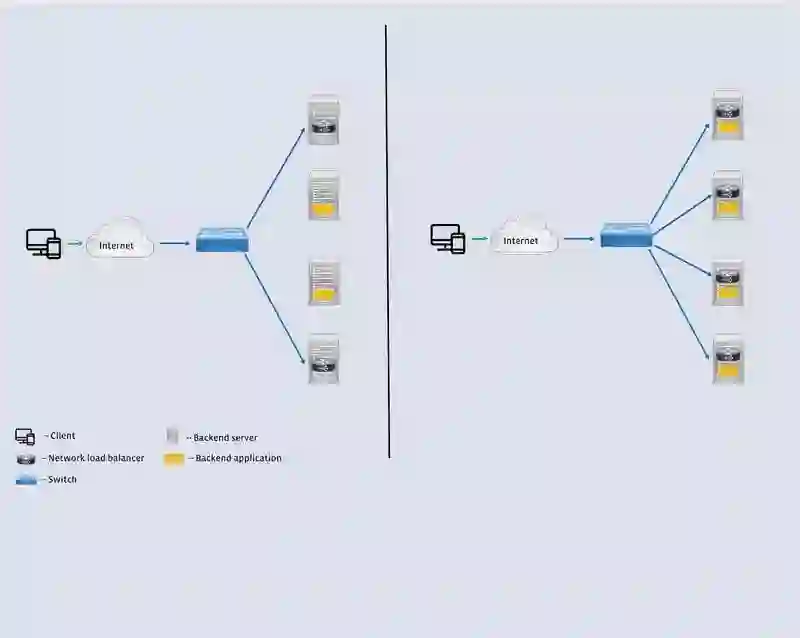
Katran 就是第二代 L4LB,通过完全重新设计转发面板,显著提高之前版本的性能。两项最新的内核工程创新为新设计提供了动力:
XDP 提供了一种高速的可编程网络数据路径,无需使用完整的内核旁路方法,并可与 Linux 网络栈结合使用。
eBPF 虚拟机提供了一种灵活、高效且更可靠的方式来与 Linux 内核进行交互,并通过在内核中的特定点运行用户程序来扩展功能。eBPF 已经为几个领域带来了巨大的改进,包括追踪和过滤。
第二代系统的总体架构与第一代 L4LB 相似:首先,ExaBGP 向互联网发布特定的 Katran 实例负责哪个 VIP。其次,发往 VIP 的数据包通过 ECMP 机制发送到 Katran 实例。最后,Katran 将数据包转发给正确的后端服务器。它们之间的主要区别在于最后一步。
高效的数据包处理:Katran 结合使用 XDP 和 BPF 程序来转发数据包。在驱动器模式下启用 XDP 时,数据包处理例程(BPF 程序)会在网络接口卡(NIC)收到数据包之后以及在内核截获之前运行。XDP 在每个传入数据包上调用 BPF 程序。如果 NIC 具有多个队列,则为每个队列并行调用该程序。用于处理数据包的 BPF 程序是无锁的,并使用单 CPU 内核版本的 BPF 映射。因为具备了这种并行性,性能与 NIC 的 RX 队列数量呈线性关系。Katran 还支持“通用 XDP”操作模式(而不是驱动模式),不过需要以牺牲性能为代价。
开销更小且更稳定的哈希:Katran 使用 Maglev 哈希算法的扩展版来选择后端服务器。扩展版哈希算法具备了更好的弹性,能够更均匀的分布负载,可以为不同的后端服务器设置不同的权重。其中最后一项最为重要,他们因此能够轻松处理 PoP 和数据中心的硬件更新:通过设置适当的权重来更新硬件。计算哈希值的代码体积很小,完全可以放入 L1 缓存中。
更具弹性的本地状态:Katran 在处理数据包和计算哈希值时需要与本地状态表发生交互。他们发现,通常情况下,计算哈希值比查找本地状态表中的 5 元组更容易,因为在本地状态表中有时候需要遍历到最后一级缓存才能找到目标。为此,他们将查找表实现为 LRU 缓存。LRU 缓存大小可在启动时配置,并作为可调参数,以便在计算和查找之间取得平衡。此外,Katran 提供了一个运行时“仅计算”开关,以便在主机发生灾难性内存压力的情况下完全忽略 LRU 缓存。
RSS 封装:接收端伸缩(Received Side Scaling,RSS)是针对 NIC 的一项重要优化,旨在通过将数据包发送到单独的 CPU 来均匀地在 CPU 之间分布负载。不同流中的数据包使用不同的外部 IP 来封装,但相同流中的数据包总是被分配相同的外部 IP。
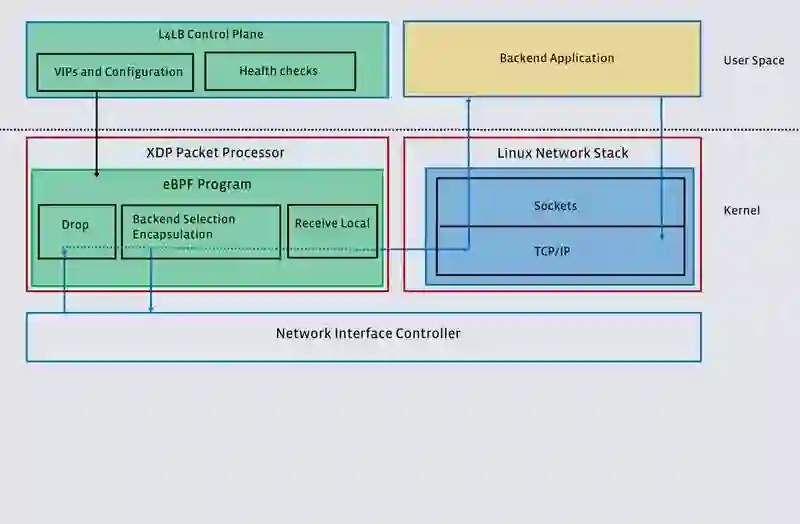
图 4:Katran 为高速处理数据包提供了一条快速路径,无需借助内核旁路。
这些特性显著提升了 L4LB 的性能、灵活性和可扩展性。如果没有数据包流入,Katran 几乎不消耗 CPU。与内核旁路解决方案(如 DPDK)相比,XDP 可以让 Katran 与任何应用程序一起运行,而不会遭受性能损失。现在,Katran 与 Facebook 的 PoP 后端服务器一起运行,增强了对负载峰值的处理能力和主机故障恢复能力。
其他注意事项
Katran 仅适用于直接服务回退(Direct Service Return,DSR)模式。
Katran 是决定数据包最终目的地的组件,因此网络需要首先将数据包路由到 Katran,这要求网络拓扑是基于 L3 的。
Katran 不能转发分段的数据包,也不能自行进行数据包分段。这个问题可以通过增加网络内部的最大传输单元(MTU)或通过在后端更改 TCP MSS 来解决。
Katran 不支持包含 IP 选项设置的数据包,最大数据包大小不能超过 3.5KB。
Katran 的设计是基于这样的前提,即它将被用在“单臂负载均衡器”中。
GitHub 地址:https://github.com/facebookincubator/katran
如果,Google 早已解决不了你的问题。
如果,你还想知道 Apple、Facebook、IBM、阿里等国内外名企的核心架构设计。
来,我们在深圳准备了 ArchSummit 全球架构师峰会,想和你分享:
微信百亿消息背后的万级机器是怎么做 AI 调度的
滴滴三核心引擎之一的地图,如何计算路径规划和道路匹配
微博如何做万亿级关系的实时协同推荐
微众区块链首席架构师的两个具体案例实操
罗辑思维 Go 语言微服务完整改造全过程
阿里菜鸟全球跨域 RPC 架构设计
前特斯拉视觉深度学习负责人带来的核心技术解析
微服务楷模 Netflix 在 FaaS 上的最新实践