Python中的字符串和字符数据(下)

s.isspace()
判断目标字符串是否由空白字符组成
如果s是非空的并且所有字符都是空白字符,s.isspace()返回True,否则返回False。
最常遇到的空白字符是空格" ",制表符" "和换行符" ":

但是,还有一些其他ASCII字符可以作为空格,而且如果你考虑使用Unicode字符,还会有更多:

( "" 以及 " " 是ASCII换页和回车的转义字符;" " 是Unicode Four-Per-Em Space的转义字符。)
s.istitle()
判断目标字符串是否为单词首字母大写
如果s非空且每个单词的第一个字母字符为大写,所有其他字母字符均为小写,s.istitle()返回True,否则返回False:

注意:以下是Python文档中对.istitle()的描述,如果您觉得这更直观的话:“大写字符只能跟在非大小写字符的后面,小写字符只能跟在大小写字符的后面。”
s.isupper()
判断目标字符串的字母字符是否为大写
如果s是非空的,并且它包含的所有字母字符都是大写的,则s.isupper()返回True,否则为False。非字母字符将被忽略:

字符串格式化
本组方法修改或增强字符串的格式。
s.center(<width>[, <fill>])
在字段中居中字符串
s.center(<width>)返回一个s在<width>宽度字段居中的字符串。默认情况下,由ASCII码中的空格字符进行填充:

如果指定了可选参数<fill>,则将其用作填充字符:

如果s长度已经大于等于<width>,则返回结果不改变:

s.expandtabs(tabsize=8)
扩展字符串中的制表符
s.expandtabs()用空格替换每个制表符(‘ ")。默认情况下,在假设制表符每八列一停的情况下填充空格:
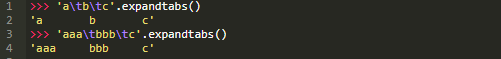
tabsize是一个可选关键字参数,用来指定替换制表符的停止列数。

s.ljust(<width>[, <fill>])
左对齐字段中的字符串
s.ljust(<width>)返回一个s在<width>宽度字段左对齐的字符串。默认情况下,由ASCII码中的空格字符进行填充:

如果指定了可选参数<fill>则将其用作填充字符:

如果s长度已经大于等于<width>,则返回结果不改变:

s.lstrip([<chars>])
修剪字符串中的前导字符
s.lstrip()返回删除左端全部空白字符的s的副本:

如果指定了可选参数<chars>,则它指定了一个被移除的字符的集合:

s.replace(<old>, <new>[, <count>])
替换字符串中出现的子字符串
s.replace(<old>,<new>)返回将s中所有的子串<old>替换为<new>的副本:

如果指定了可选参数<count>,仅执行最大数目为<count>的替换,从字符串左侧开始:

s.rjust(<width>[, <fill>])
右对齐字段中的字符串
s.rjust(<width>)返回一个s在<width>宽度字段右对齐的字符串。默认情况下,由ASCII码中的空格字符进行填充:

如果指定了可选参数<fill>,则将其用作填充字符:

如果s长度已经大于等于<width>,则返回结果不进行改变:

s.rstrip([<chars>])
修剪字符串中的尾随字符
s.rstrip()返回删除右端全部空白字符的s的副本:

如果指定了可选参数<chars>,则它指定了一个被移除的字符的集合:

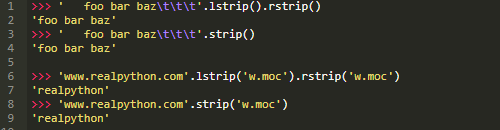
s.strip([<chars>])
从字符串的左端和右端修剪字符
s.strip()基本上相当于连续调用s.lstrip()和s.rstrip()。如果没有指定<chars>参数,它会删除前导和尾随空白字符:

与.lstrip()和.rstrip()一样,可选参数<chars>指定要删除的字符集:

注意:当字符串方法的返回值是另一个字符串时(通常是这种情况),可以通过链接调用来连续调用方法:
s.zfill(<width>)
用零填充字符串左侧
s.zfill(<width>)返回一个左侧用指定<width>个"0"字符填充的s的副本

如果s包含前导符号,则在插入零后它将保留在结果字符串的左边缘:

如果s长度已经大于等于<width>,则返回结果不进行改变:

.zfill()在用字符串表示数字的过程中最有用,但Python还是会很乐意向普通字符串中添加零:

在字符串和列表之间转换
此组中的方法通过将对象粘贴在一起以生成字符串或将字符串分成多个片段来在字符串和某些复合数据类型之间进行转换。
这些方法操作或返回iterables,这是对象的顺序集合的通用Python术语。您将在即将到来的definite iteration教程中更详细地探索iterables的内部工作原理。
这些方法中很多都返回列表或者是元组。这是两个类似的复合数据类型,它们是Python中可迭代对象的典型示例。
它们将在下一个教程中介绍,所以很快您将了解它们。在此之前,只需要将它们视为值的序列。一个列表用方括号括起来([]),一个元组用括号括起来(())。
介绍完毕,让我们来看看最后一组字符串方法。
s.join(<iterable>)
从可迭代对象中链接字符串
s.join(<iterable>) 返回由分隔符s连接在<iterable>中的对象所组成的字符串。
需要注意.join在分隔符字符串s上进行调用。<iterable>也必须是一个字符串对象序列。
一些示例代码应该会让说明变得更清晰。在下面的例子中,分隔符s是字符串",",并且<iterable>是字符串值的列表。
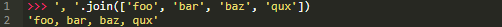
返回结果是列表中的对象被逗号分隔所组成的单一字符串。
在下一个例子中,<iterable>被指定为单一字符串值。当一个字符串值作为可迭代对象时,它被解释成字符串中每个独立字符所组成的列表。

因此,":".join("corge") 返回的结果是"corge"中的每个字符通过":"分割所组成的字符串。
下面这个例子报错了因为<iterable>中有一个对象不是字符串:

但是,这个错误可以改正:

很快你就会看到,Python中的许多复合对象可以被解释为可迭代对象,.join()对于从它们中创建字符串特别有用。
s.partition(<sep>)
基于分隔符分割字符串
s.partition(<sep>)在第一次出现字符串<seq>的地方对s进行分割。返回的三元元组包括:
s中<seq>之前的部分
<seq>本身
s中<seq>后面的部分
下面是一些实际使用.partition的例子:
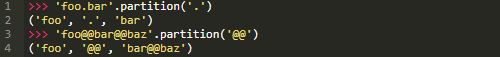
如果在s中没有找到<seq>,则返回的元组包含s和两个空字符串:

记住:列表和元组将会在下一个教程介绍。
s.rpartition(<sep>)
基于分隔符分割字符串
s.rpartition(<sep>)与s.partition(<sep>)在功能上极其相似,除了是在s中最后一次出现<seq>而不是第一次出现的地方进行分割:

s.rsplit(sep=None, maxsplit=-1)
将一个字符串分成一组子串
在不带参数的情况下,s.rsplit()将s中任何空白字符序列分隔的子字符串进行分割,并将子字符串用列表返回:

如果<sep>被指定,则将其用作分割标识:

(如果<seq>的值被指定为None,则字符串依照空白字符进行分割,就和<seq>没有被指定一样)
当<sep>明确作为分隔符给出时,s中连续的分隔符被认为对空字符串进行分隔,返回结果如下:

然而,当省略<sep>时情况则并非如此。在这种情况下,连续的空白字符被合并成一个分隔符,并且结果列表中将不会包含空字符串:

如果指定了可选参数<maxsplit>,仅从字符串右侧开始执行最大次数的分割操作:

<maxsplit>的默认值为-1,意味者所有可能的分割都要执行——与<maxsplit>被完全忽略的时候一样:

s.split(sep=None, maxsplit=-1)
将一个字符串分成一组子串
s.split()与s.rsplit()看起来非常像,除了当<maxsplit>被指定的时候,从s左侧开始计数而不是右侧:

如果<maxsplit>没有指定,.split()和.rsplit()是完全一样的。
s.splitlines([<keepends>])
按照行边界分割字符串
s.splitlines()将s按行分割并将结果用列表返回。下面的字符或者字符序列都被看作构成了行边界:
| 转义字符 | 描述 |
| 换行 | |
| 回车 | |
| 回车+换行 | |
| 或 | 行列表 |
| 或 | 换页 |
| 文件分隔符 | |
| 组分隔符 | |
| 记录分隔符 |
|
| 下一行(C1控制代码) | |
| Unicode行分隔符 | |
| Unicode段落分隔符 |
下面是一个使用了多个不同行分割符的例子:

如果连续的行界符出现在字符串中,它们会被认为是对空行进行分隔,会在结果列表中进行返回:

如果指定了可选参数<keepends>并且值为真,那么行界符将会包含在结果字符串中:

bytes对象
bytes对象是用于二进制数据操作的核心内置类型之一。一个bytes对象是单个字节值组成的不可更改的序列。bytes对象中的每个元素都是在0到255之间的一个小整数。
定义bytes对象字面量
bytes对象与字符串对象的字面量按照相同的方法定义,需要额外添加"b"前缀:

与字符串一样,你可以使用单引号,双引号以及三引号:

bytes字面量只允许ASCII编码字符。任何超过127的字符值必须使用适当的转义字符进行指定:

与字符串相同,在bytes字面量中使用"r"前缀用来禁用转义字符:

使用内置bytes()函数定义一个bytes对象
bytes()函数可以创建一个bytes对象。返回哪种bytes对象取决于传递给函数的参数。可能的形式如下:
bytes(<s>, <encoding>)
从字符串中创建bytes对象
bytes(<s>, <encoding>)根据指定的<encoding>利用str.encode()将字符串<s>转化为一个bytes对象:

技术说明:在bytes()函数的这种形式中,<encoding>参数是必需的。“编码”是指将字符转换为整数值的方式。值"utf8"表明使用Unicode转换格式UTF-8,它是一种可以处理每个可能的Unicode字符的编码。UTF-8也可以通过指定<encoding>为"UTF8","utf-8"或"UTF-8"。
更多信息,请参考Unicode文档。只要你处理的是普通的拉丁字符,UTF-8都会很合适。
bytes(<size>)
创建一个由null(0x00)组成的bytes对象
bytes(<size>)定义了一个指定<size>的bytes对象,其中<size>必须为正整数。结果字节对象使用null(0x00)字节进行初始化:

bytes(<iterable>)
从可迭代对象中创建bytes对象
bytes(<iterable>) 从<iterable>产生的一系列整数中定义一个bytes对象。<iterable>必须是一个能够产生一系列0到255范围内的整数的可迭代对象:

bytes对象上的操作
类似字符串,bytes对象支持常见的序列操作:
in和not in运算符:

连接(+)以及复制(*)运算符:

索引和切片

内置函数:

许多定义在字符串上的方法在字节对象中也是合法的:

然而,需要注意的是,当在bytes对象上调用这些运算符以及方法的时候,操作数和参数也必须是bytes对象:

虽然bytes对象定义和表示基于ASCII文本,但它实际上表现一个包含范围0到255的小整数的不可变序列。这就是为什么来自bytes对象的单个元素显示为整数:

切片显示为字节对象,尽管只有一个字节长:

您可以使用内置的list()函数将字节对象转化为一个整数列表:

十六进制数通常用于指定二进制数据,因为两个十六进制数字直接对应于单个字节。bytes类支持两个附加的方法便于与十六进制进行相互转化。
bytes.fromhex(<s>)
返回由十六进制值字符串构造的bytes对象
bytes.fromhex(<s>)返回在<s>中的每一对十六进制数字对应的字节值所组构建的字节对象。<s>中的十六进制数值对可以随意被空白字符分开,空白字符会被忽略:

注意:这个方法是一个类方法,不是对象方法。它与bytes类绑定,而不是bytes对象。在即将到来的面向对象编程教程中,您将深入研究类,对象及其各自方法之间的区别。现在,只需观察到此方法是在bytes类上调用的,而不是在对象上b调用的。
b.hex()
从bytes对象中返回十六进制值的字符串
b.hex()返回将bytes对象b转换为十六进制数字对的字符串的结果。也就是说,它与.fromhex()的功能是相反的:
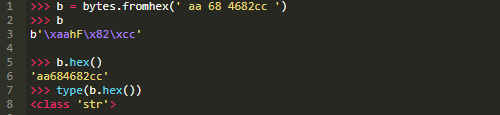
注意:与.fromhex()相对的,.hex()是一个对象方法而非类方法。因此,它在bytes类型的对象上调用,而不是类本身。
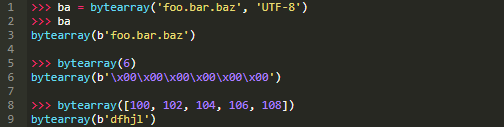
bytearray对象
Python支持的另一种二进制序列类型叫做bytearray。bytearray对象与bytes对象非常相似,仅有一些不同:
Python中没有专门的语法来定义bytearray字面量,类似"b"前缀可以用来定义bytes对象。bytearray对象始终使用bytearray()内置函数创建:
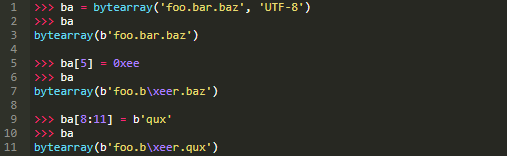
bytearray对象是可变的。您可以使用索引和切片修改bytearray对象的内容:
bytearray对象也可以直接从bytes对象中创建:

结论
本教程深入介绍了Python为字符串处理提供的许多不同机制,包括字符串运算符,内置函数,索引,切片和内置方法。同样也向您介绍了bytes和bytearray类型。
英文原文:https://realpython.com/python-strings/
译者:搞一个大新闻



