![]()
尊敬的各界同仁:
第四届中国模式识别与计算机视觉大会(The fourth Chinese Conference on Pattern Recognition and Computer Vision, PRCV 2021)将于2021年10月29日至11月1日在北京国际会议中心举行。PRCV2021由中国图象图形学学会(CSIG)、中国人工智能学会(CAAI)、中国计算机学会(CCF)和中国自动化学会(CAA)联合主办,由北京科技大学、北京交通大学和北京邮电大学共同承办,中山大学、清华大学协办,是国内顶级的模式识别和计算机视觉领域学术盛会。
本届会议将主要汇聚国内国外模式识别和计算机视觉理论与应用研究的广大科研工作者及工业界同行,共同分享我国模式识别与计算机视觉领域的最新理论和技术成果,提供精彩的学术盛宴。同时,PRCV2021邀请了北京大学人工智能研究院院长朱松纯教授、中国科学院自动化研究所所长徐波研究员、美国马里兰大学Larry Davis教授、日本东京大学Yoichi Sato教授、德国马克斯-普朗克研究所Michael Black等国际知名专家作大会主题报告。本届会议同期将举办模式识别、计算机视觉与机器学习领域前沿理论与方法论坛、讲习班及博士生论坛,以及行业专业应用竞赛。
欢迎各界同仁参会,感谢支持!
PRCV 2021组委会
2021年7月22日
![]()
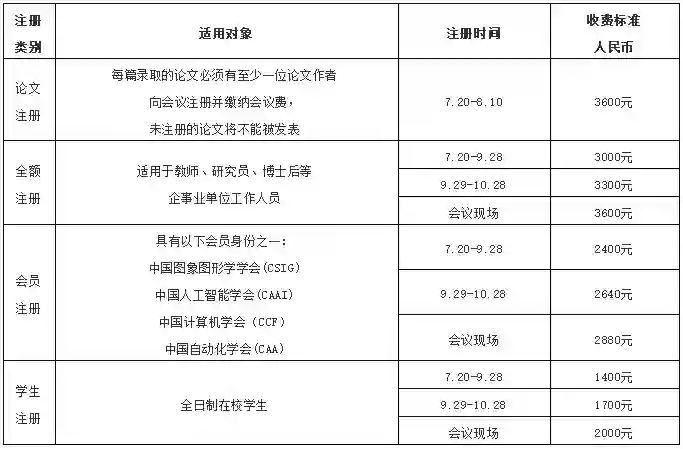
· 每篇录取的论文当且仅当只能注册一位作者,需于2021年8月10日前注册;未注册的论文将不能被发表;其他与会者按照类别注册参会;
· 全日制在校学生不含在职研究生和博士后,学生注册时须提供学生证的扫描件,否则需补齐全额注册费;
· 会议报到日期:2021年10月29日;报到地点:北京国际会议中心,北京市朝阳区北辰东路8号院;
· 往返交通及食宿费用自理。
1、注册方式支持大会官网注册和微网站注册两种方式。
2、缴费方式支持微信支付、支付宝支付以及线下转账汇款三种方式。
3、线下转账汇款账户信息:
账户名:马上科普教育科技(北京)有限公司
账 号:110061241013000738801
开户行:交通银行北京中关村园区支行
备注:如选择线下转账汇款注册方式,请务必先办理转账汇款后再进行注册,请务 必在办理汇款时附言里注明姓名和单位,务必在注册完成后上传付款凭证截图(登录个人中心-我的订单-上传付款凭证)。
4、大会官网注册请通过链接: http://s.31url.cn/vC8N5c8j
5、微网注册请扫描以下二维码:
![]()
温馨提示:请在网上注册界面,准确填写姓名、单位、电子邮箱、手机号等信息。
1、会议发票由PRCV2021会务公司:
马上科普教育科技(北京)有限公司开具。
2、参会人员预定的酒店,由酒店开具发票。
1、会务组联系人:
殷君君 13260015764 明悦 15110206295
肖继民 17605127961 赵毅 18910476625
2、注册缴费/发票:李超 13439275509
PRCV2021期待您的莅临,共享模式识别与计算机视觉领域的国内顶级学术盛会!
Question 1.论文注册是指论文有收录在proceedings中?
Answer 是的。
Question 2.
论文注册了,就不需要作者注册?
Answer
需要至少一位作者论文注册,论文注册只绑定一位参会者,其他与会者按照类别注册参会。
Question 3.
如果没有论文,可以选择‘全文’、‘会员’、‘学生’注册?
Question 4.
一个论文只能注册一个参会人员?
Answer
需要至少一位作者论文注册,其他与会者按照类别注册参会。
Answer 是的。
Question 6.
每个论文都要有‘论文注册’,是吗?
Answer 是的。
![]()
1、朱松纯教授,北京通用人工智能研究院院长、北京大学讲席教授、清华大学基础科学讲席教授
主旨报告人简介:
朱松纯教授出生于湖北省鄂州,全球著名计算机视觉专家,统计与应用数学家、人工智能专家。1991年毕业于中国科技大学,1992年赴美留学,1996年获得美国哈佛大学计算机博士学位。2002年至2020年,在美国加州大学洛杉矶分校(UCLA)担任统计系与计算机系教授,UCLA视觉、认知、学习与自主机器人中心主任。在国际顶级期刊和会议上发表论文300余篇,获得计算机视觉、模式识别、认知科学领域多个国际奖项,包括3次问鼎计算机视觉领域国际最高奖项--马尔奖,赫尔姆霍茨奖等,2次担任国际计算机视觉与模式识别大会主席(CVPR2012、CVPR2019),2010-2020年 2次担任美国视觉、认知科学、人工智能等领域多大学、跨学科合作项目MURI负责人。朱松纯教授长期致力于构建计算机视觉、认知科学、乃至人工智能科学的统一数理框架。在留美28年后, 朱教授于2020年9月回国,担任北京通用人工智能研究院院长,并任北京大学讲席教授、清华大学基础科学讲席教授。
报告题目:Computer Vision: A Task-oriented and Agent-based Perspective
2、徐波,中国科学院自动化研究所所长、研究员
主旨报告人简介:现任中科院自动化研究所所长,中国科学院大学人工智能学院院长,兼任国家新一代人工智能战略咨询委员会委员等职。长期从事智能语音处理和人工智能技术研究和应用。曾获 “中国科学院杰出青年奖”、 “王选新闻科技进步一等奖”等奖项;主持多项国家支撑、863、973以及自然科学基金重点项目和课题。研究成果在教育、广电、安全等领域获得规模化应用。近年了重点围绕听觉模型、类脑智能、认知计算及博弈智能等进行研究探索。
摘要:随着文本模型GPT3/BERT等提出,预训练模型呈现高速发展的趋势,图像-文本联合学习的双模态模型也不断涌现,显示出在无监督情况下自动学习不同任务和快速迁移到不同领域数据的强大能力。然而,当前的预训练模型忽略了声音信息。在我们周边还包含大量的声音,其中语音不仅是人类之间交流的手段,还蕴藏着情绪和感情。本报告将介绍引入语音以后的首个图-文-音三模态大模型 “紫东太初”。模型将视觉、文本、语音不同模态通过各自编码器映射到统一语义空间,然后通过多头自注意力机制(Multi-head Self-attention)学习模态之间的语义关联以及特征对齐,形成多模态统一知识表示;既可以实现跨模态理解,还能实现跨模态生成,同时做到理解和生成认知能力的平衡;我们提出了一个基于词条级别(Token-level)、模态级别(Modality-level)以及样本级别(Sample-level)的多层次、多任务自监督学习统一框架,对更广泛、更多样的下游任务提供模型基础支撑,并特别地实现了通过语义网络以图生音、以音生图的功能。三模态大模型是迈向具有艺术创作能力、强大交互能力和任务泛化能力的通用型人工智能的一次重要的尝试。
![]()
3、Prof. Larry Davis,University of Maryland, USA
主旨报告人简介:
Larry S. Davis is a Distinguished University Professor in the Department of Computer Science and director of the Center for Automation Research (CfAR). His research focuses on object/action recognition/scene analysis, event and modeling recognition, image and video databases, tracking, human movement modeling, 3-D human motion capture, and camera networks. Davis is also affiliated with the Computer Vision Laboratory in CfAR. He served as chair of the Department of Computer Science from 1999 to 2012. He received his doctorate from the University of Maryland in 1976. He was named an IAPR Fellow, an IEEE Fellow, and ACM Fellow.
![]()
4、Prof. Yoichi Sato,University of Tokyo, Japan
主旨报告人简介:
Yoichi Sato is a professor at Institute of Industrial Science, the University of Tokyo. He received his B.S. degree from the University of Tokyo in 1990, and his MS and PhD degrees in robotics from School of Computer Science, Carnegie Mellon University in 1993 and 1997. His research interests include first-person vision, and gaze sensing and analysis, physics-based vision, and reflectance analysis. He served/is serving in several conference organization and journal editorial roles including IEEE Transactions on Pattern Analysis and Machine Intelligence, International Journal of Computer Vision, Computer Vision and Image Understanding, CVPR 2023 General Co-Chair, ICCV 2021 Program Co-Chair, ACCV 2018 General Co-Chair, ACCV 2016 Program Co-Chair and ECCV 2012 Program Co-Chair.
报告题目:
Understanding Human Activities from First-Person Perspectives
摘要:
Wearable cameras have become widely available as off-the-shelf products. First-person videos captured by wearable cameras provide close-up views of fine-grained human behavior, such as interaction with objects using hands, interaction with people, and interaction with the environment. First-person videos also provide an important clue to the intention of the person wearing the camera, such as what they are trying to do or what they are attended to. These advantages are unique to first-person videos, which are different from videos captured by fixed cameras like surveillance cameras. As a result, they attracted increasing interest to develop various computer vision methods using first-person videos as input. On the other hand, first-person videos pose a major challenge to computer vision due to multiple factors such as continuous and often violent camera movements, a limited field of view, and rapid illumination changes. In this talk, I will talk about our attempts to develop first-person vision methods for different tasks, including action recognition, future person localization, and gaze estimation.
![]()
5、Michael Black,Max Planck Institute for Intelligent Systems, Germany
主旨报告人简介:Michael Black received his B.Sc. from the University of British Columbia (1985), his M.S. from Stanford (1989), and his Ph.D. from Yale University (1992). After post-doctoral research at the University of Toronto, he worked at Xerox PARC as a member of research staff and area manager. From 2000 to 2010 he was on the faculty of Brown University in the Department of Computer Science (Assoc. Prof. 2000-2004, Prof. 2004-2010). He is one of the founding directors at the Max Planck Institute for Intelligent Systems in Tübingen, Germany, where he leads the Perceiving Systems department. He is also a Distinguished Amazon Scholar (VP), an Honorarprofessor at the University of Tuebingen, and Adjunct Professor at Brown University. His work has won several awards including the IEEE Computer Society Outstanding Paper Award (1991), Honorable Mention for the Marr Prize (1999 and 2005), and all three major test-of-time awards including the 2010 Koenderink Prize, the 2013 Helmholtz Prize, and the 2020 Longuet-Higgins Prize. He is a foreign member of the Royal Swedish Academy of Sciences. In 2013 he co-founded Body Labs Inc., which was acquired by Amazon in 2017.
PRCV2021大会官网
PRCV2021微网站
![]()
![]()