CVPR2019 | 面对高度不均衡数据如何提高精度?这篇文章有妙招
作者 | Skura
编辑 | Camel
本文是对 CVPR 2019 论文「Class-Balanced Loss Based on Effective Number of Samples」的一篇点评。
这篇论文针对最常用的损耗(softmax 交叉熵、focal loss 等)提出了一种按类重新加权的方案,以快速提高精度,特别是在处理类高度不平衡的数据时尤其有用。
本文的实现方法(PyTorch)的 github 地址为:
https://github.com/vandit15/Class-balanced-loss-pytorch
有效样本数
在处理长尾数据集(一个数据集的大多数样本属于少数类,而其它许多类的数据很少)时,决定如何权衡不同类的损失是很棘手的。通常,权重设置为类支持的逆或类支持的平方根的逆。
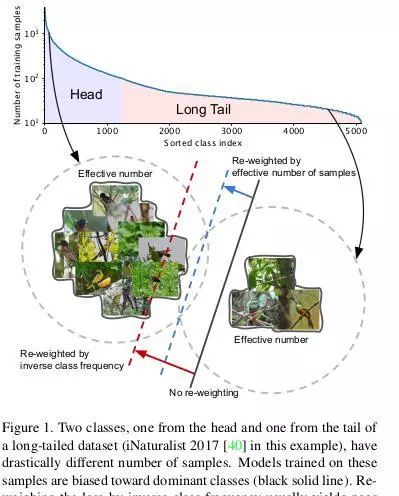
传统重加权与这里提到的重加权
然而,如上图所示,这种现象是因为随着样本数的增加,新数据点带来的额外好处减少了。在训练神经网络时使用重数据增强(如重缩放、随机裁剪、翻转等)时,新添加的样本很可能是现有样本的近似副本。用有效样本数重新加权得到了较好的结果。
有效样本数可以想象为 n 个样本覆盖的实际体积,其中总体积 N 由总样本数表示。
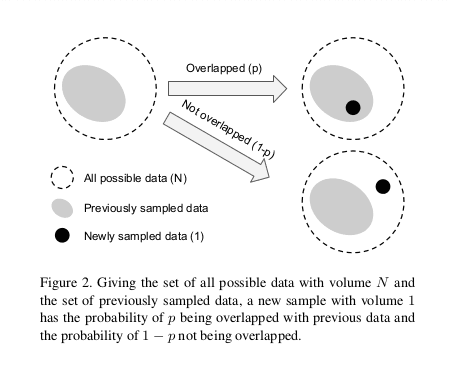
有效样本数
我们写出其公式:
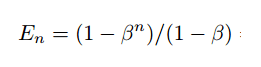
有效样本数
这里,我们假设一个新的样本将只以两种方式与先前采样的数据交互:完全覆盖或完全没有交集(如上图所示)。在这种假设下,用归纳法可以很容易地证明上述表达式(请参阅本文的证明)。
我们也可以像下面这样写:
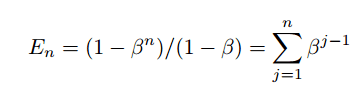
每个样本的贡献
这意味着第 j 个样本对有效样本数贡献为 β^(j-1)。
上述方程的另一个含义是,如果 β=0,则 En=1。同时,En=n 则 β=1。后者可以很容易地用 L'Hopital's 法则证明。这意味着当 N 很大时,有效样本数与样本数相同。在这种情况下,唯一原型数 N 很大,每个样本都是唯一的。然而,如果 N=1,这意味着所有数据都可以用一个原型表示。
类平衡损失
如果没有额外的信息,我们不能为每个类设置单独的 β 值,因此,使用整个数据,我们会将其设置为特定值(通常设置为0.9、0.99、0.999、0.9999 之一的数值)。
因此,类平衡损失可以写成:
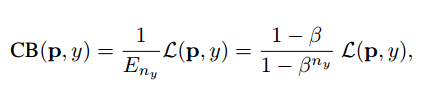
CB 损失
这里,L(p,y) 可以是任何损失函数。
类平衡 focal loss
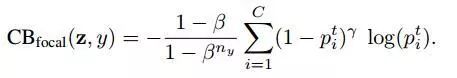
类平衡 focal loss
原始版本的 focal loss 有一个 alpha 平衡变量。相反,我们将使用每个类的有效样本数对其重新加权。
类似地,这种重新加权项也可以应用于其他著名的损失(sigmoid 交叉熵、softmax 交叉熵等)。
应用
在开始应用之前,在使用基于 sigmoid 的损耗进行训练时要注意一点:用 b=-log(c-1)初始化最后一层的偏差,其中类的数量是 c,而不是 0。这是因为设置 b=0 在训练开始时会导致巨大的损失——每个类的输出概率接近 0.5。因此,我们可以假设类 prior 是 1/c,并相应地设置值 b。
类的权重计算

计算标准化权重
上面的代码行是一个简单的实现,获取权重并将其标准化。

获取 one-hot 标签的 PyTorch 张量
在这里,我们得到权重的 one hot 值,这样它们就可以分别与每个类的损失值相乘。
实验
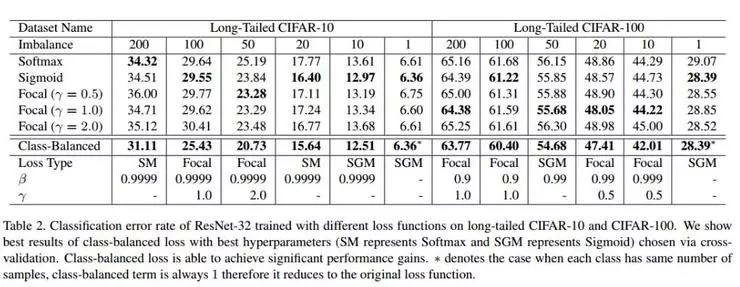
类平衡提供了显著的优势,特别是当数据集高度不平衡时(不平衡=200100)。
结论
利用有效样本数的概念,可以解决数据重合的问题。由于我们没有对数据集本身做任何假设,因此重新加权项通常适用于多个数据集和多个损失函数。因此,类不平衡的问题可以用一个更合适的结构来解决,这一点很重要,因为现实世界中的大多数数据集都存在大量的数据不平衡。
参考
[1] Class-Balanced Loss Based on Effective Number of Samples: https://arxiv.org/abs/1901.05555
via:https://towardsdatascience.com/handling-class-imbalanced-data-using-a-loss-specifically-made-for-it-6e58fd65ffab

3. 巴赫涂鸦创作者 Anna Huang 现身上海,倾情讲解「音乐生成」两大算法
4. 一份完全解读:是什么使神经网络变成图神经网络?


点击阅读原文,加入顶会交流小组


