作业帮基于 Delta Lake 的湖仓一体实践

作业帮是一家以科技为载体的在线教育公司。目前旗下拥有工具类产品作业帮、作业帮口算,K12 直播课产品作业帮直播课,素质教育产品小鹿编程、小鹿写字、小鹿美术等,以及喵喵机等智能学习硬件。作业帮教研中台、教学中台、辅导运营中台、大数据中台等数个业务系统,持续赋能更多素质教育产品,不断为用户带来更好的学习和使用体验。其中大数据中台作为基础系统中台,主要负责建设公司级数仓,向各个产品线提供面向业务主题的数据信息,如留存率、到课率、活跃人数等,提高运营决策效率和质量。
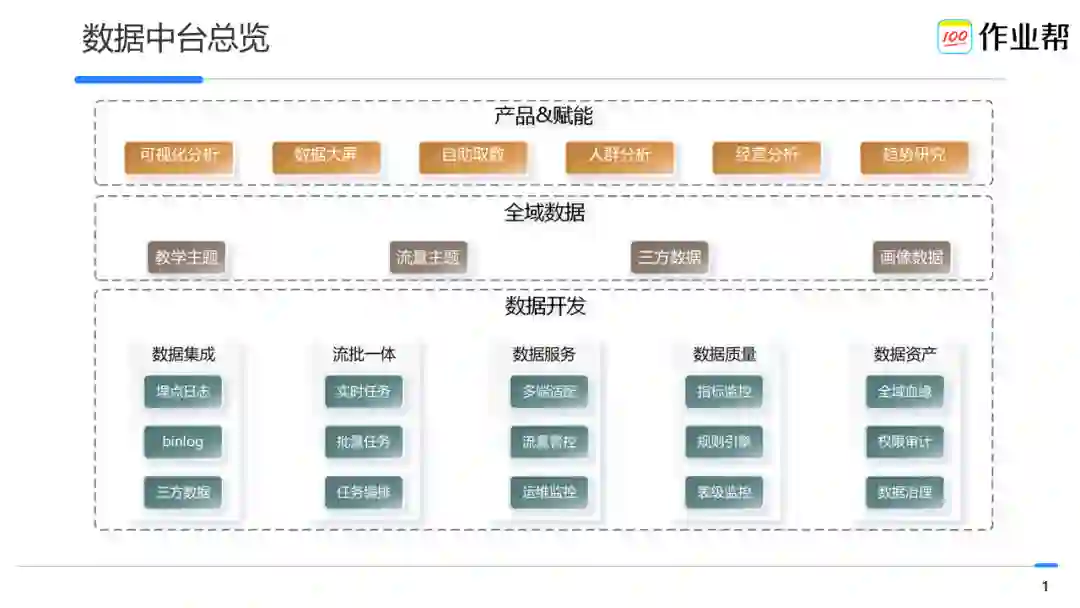
上图为作业帮数据中台总览。主要分为三层:
第一层是数据产品以及赋能层。主要是基于主题数据域构建的数据工具以及产品,支撑商业智能、趋势分析等应用场景。
第二层是全域数据层。通过 One Model 统一建模,我们对接入的数据进行了标准化建模,针对不同时效性的场景构建了业务域的主题数据,提高上层产品的使用效率和质量。
第三层是数据开发层。我们构建了一系列的系统和平台来支持公司内所有的数据开发工程,包括数据集成、任务开发、数据质量、数据服务、数据治理等。
本次分享的内容主要是面向离线数仓(天级、小时级)解决其生产、使用过程中的性能问题。
作业帮离线数仓基于 Hive 提供从 ODS 层到 ADS 层的数据构建能力,当 ADS 表生成后,会通过数据集成写入 OLAP 系统面向管理人员提供 BI 服务;此外,DWD、DWS、ADS 表,也会面向分析师提供线下的数据探查以及取数服务。
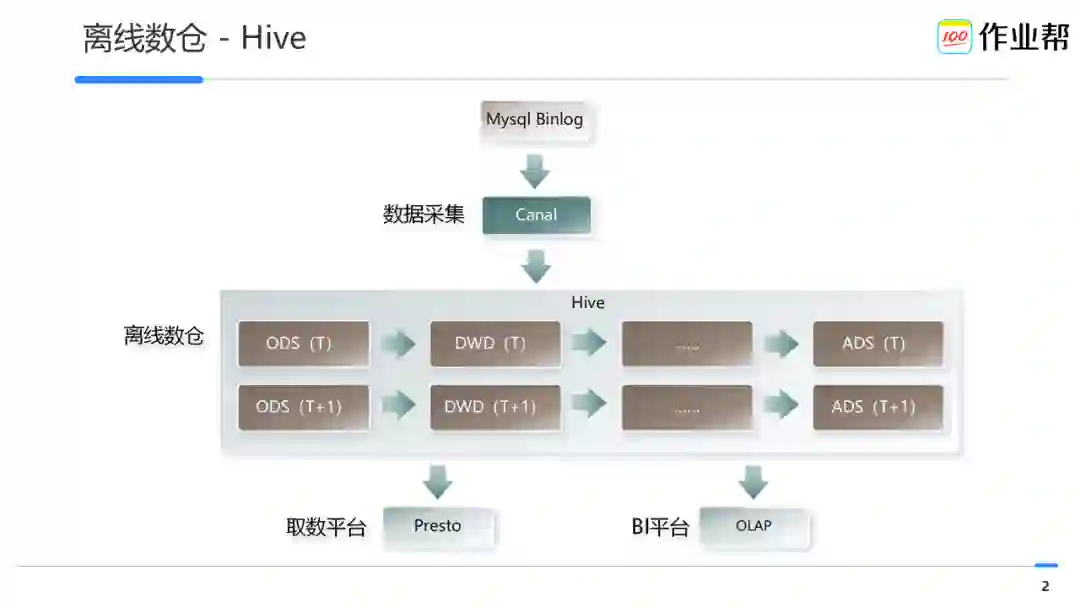
随着业务逐步发展以及对应的数据量越来越多,离线数仓系统突显如下主要问题:
ADS 表产出延迟越来越长。
由于数据量增多,从 ODS 层到 ADS 层的全链路构建时间越来越长。虽然对于非常核心的 ADS 表链路可以通过倾斜资源的模式来短期解决,但是其实这个本质上就是丢车保帅的模式,该模式无法规模化复制,影响了其他重要的 ADS 表的及时产出,如对于分析师来说,由于数据表的延迟,对于 T+1 的表最差需等到 T+2 才可以看到。
小时级表需求难以承接。
有些场景是小时级产出的表,如部分活动需要小时级反馈来及时调整运营策略。对于这类场景,随着数据量增多、计算集群的资源紧张,小时级表很多时候难以保障及时性,而为了提高计算性能,往往需要提前预备足够的资源来做,尤其是需要小时级计算天级数据的时候,最差情况下计算资源需要扩大 24 倍。
数据探查慢、取数稳定性差
数据产出后很多时候是面向分析师使用的,直接访问 Hive 则需要几十分钟甚至小时级,完全不能接受,经常会收到用户的吐槽反馈,而采用 Presto 来加速 Hive 表的查询,由于 Presto 的架构特点,导致查询的数据表不能太大、逻辑不能太复杂,否则会导致 Presto 内存 OOM,且 Hive 已有的 UDF 和 VIEW 等在 Presto 中也没法直接使用,这也非常限制分析师的使用场景。
不论是常规的 ODS 层到 ADS 层全链路产出慢、或者是面对具体表的探查取数慢,本质上都是在说 Hive 层的计算性能不足。从上述场景分析来看:
链路计算慢的原因:由于 Hive 不支持增量更新,而来自业务层数据源的 Mysql-binlog 则包含大量的更新信息,因此在 ODS 这一层,就需要用增量数据和历史的全量数据做去重后形成新的全量数据,其后 DWD、DWS、ADS 均是类似的原理。这个过程带来了数据的大量重复计算,同时也带来了数据产出的延迟。
数据查询慢的原因:由于 Hive 本身缺少必要的索引数据,因此不论是重吞吐的计算还是希望保障分钟级延迟的查询,均会翻译为 MR-Job 进行计算,这就导致在数据快速探查场景下,导致查询结果产出变慢。
从上面分析来看,如果可以解决离线数仓的数据增量更新问题就可以提高链路计算的性能,而对于数据表支持索引能力,就可以在保障查询功能不降级的前提下降低查询的延迟。
基于 HBase+ORC 的解决方案
解决数据的更新问题,可以采用 HBase 来做。对 RowKey 设置为主键,对各列设置为 Column,这样就可以提供数据实时写入的能力。但是受限于 HBase 的架构,对于非主键列的查询性能则非常差。为了解决其查询性能,需要定期(如小时表则小时级、天级表则天级)将 HBase 的表按照特定字段排序后导出到 HDFS 并存储为 ORC 格式,但是 ORC 格式只支持单列的 min、max 索引,查询性能依然无法满足需求,且由于 HBase 的数据写入一直在持续发生,导出的时机难以控制,在导出过程中数据还可能发生变化,如我们希望导出 12 月 11 日 21 点前的数据作为数据表 21 点分区的数据就需要考虑版本数、存储容量、筛选带来的计算性能等因素,系统复杂度陡增,同时也引入了 HBase 系统增加了运维成本。
数据湖
数据湖实现上是一种数据格式,可以集成在主流的计算引擎(如 Flink/Spark)和数据存储 (如对象存储) 中间,不引入额外的服务,同时支持实时 Upsert,提供了多版本支持,可以读取任意版本的数据。
目前数据湖方案主要有 Delta Lake、Iceberg、Hudi。我们调研了阿里云上这三种方案,其区别和特点如下:
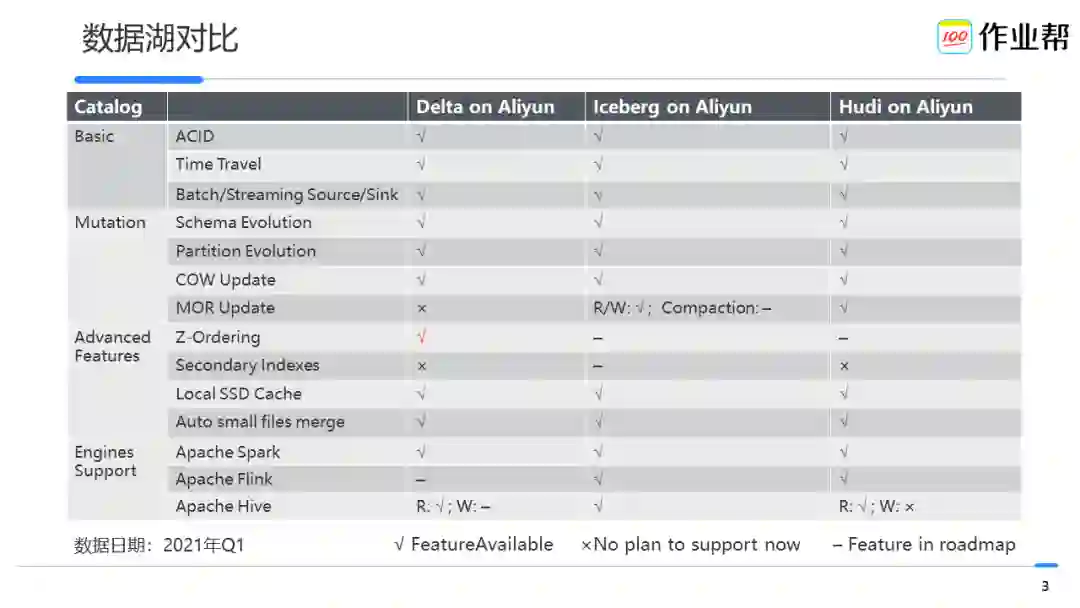
此外,考虑到易用性(Delta Lake 语义清晰,阿里云提供全功能 SQL 语法支持,使用简单;后两者的使用门槛较高)、功能性(仅 Delta Lake 支持 Zorder/Dataskipping 查询加速)等方面,结合我们的场景综合考虑,我们最后选择 Delta Lake 作为数据湖解决方案。
引入 Delta Lake 后,我们的离线数仓架构如下:
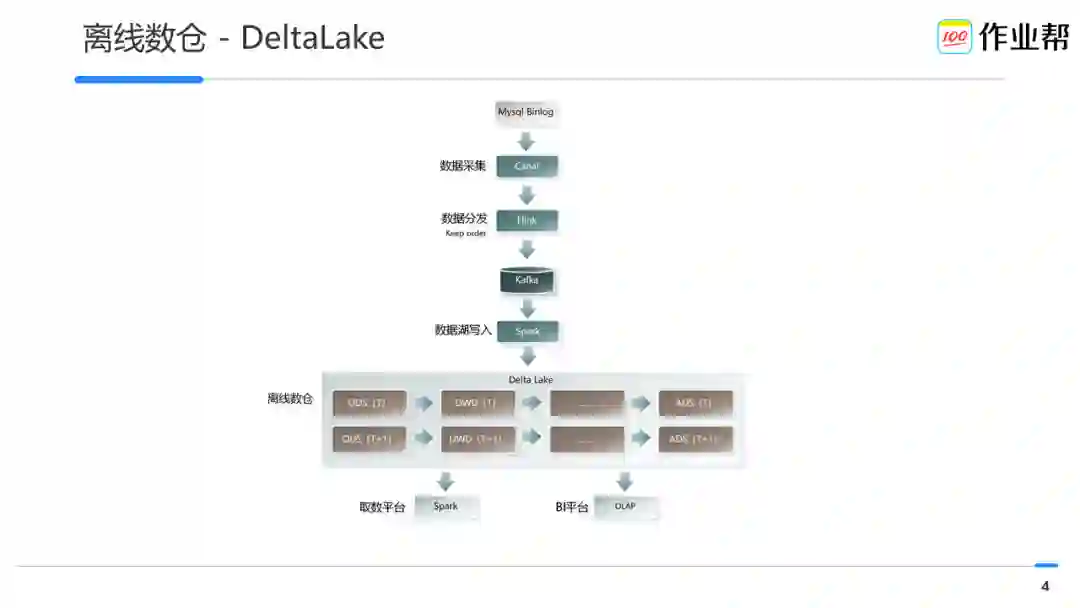
首先 Binlog 通过 Canal 采集后经过我们自研的数据分发系统写入 Kafka,这里需要提前说明的是,我们的分发系统需要对 Binlog 按照 Table 级严格保序,原因下面详述。其后使用 Spark 将数据分批写入 Delta Lake。最后我们升级了数据取数平台,使用 Spark sql 从 Delta Lake 中进行取数。
在使用 Delta Lake 的过程中,我们需要解决如下关键技术点:
业务场景下,对于离线数仓的 ETL 任务,均是按照数据表分区就绪来触发的,如 2021-12-31 日的任务会依赖 2021-12-30 日的数据表分区就绪后方可触发运行。这个场景在 Hive 的系统上是很容易支持的,因为 Hive 天然支持按照日期字段(如 dt)进行分区。但是对于 Delta Lake 来说,我们数据写入是流式写入的,因此就需要将流数据转为批数据,即某天数据完全就绪后,方可对外提供对应天级分区的读取能力。
流式数据一般会有乱序的情况,在乱序的情况下,即使采用 watermark 的机制,也只能保障一定时间范围内的数据有序,而对于离线数仓来说,数据需要 100% 可靠不丢。而如果我们可以解决数据源的有序性问题,那么数据就绪问题的解决就会简化很多:假如数据按照天级分区,那么当出现 12-31 的数据时,就可以认为 12-30 的数据都就绪了。因此,我们的方案拆解为两个子问题:
流数据有序后界定批数据边界
保障流数据有序的机制
首先对于前者,总体方案如下:
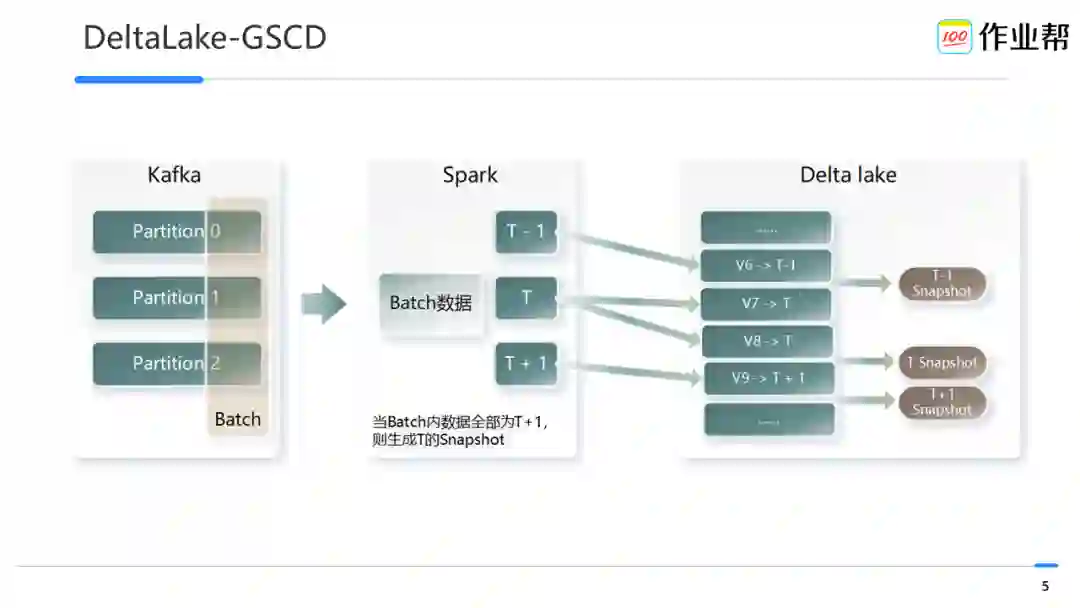
设定数据表的逻辑分区字段 dt 以及对应的时间单位信息。

当 Spark 读取某一个 batch 数据后,根据上述表元数据使用数据中的 event time 生成对应的 dt 值,如数据流中 event time 的值均属于 T+1,则会触发生成数据版本 T 的 snapshot,数据读取时根据 snapshot 找到对应的数据版本信息进行读取。
不论是 app-log 还是 mysql-binlog,对于日志本身都是有序的,以 mysql-binlog 举例,单个物理表的 binlog 必然有序,但是实际业务场景下,业务系统会经常进行分库分表的使用,对于使用分表的场景,一张逻辑表 Table 会分为 Table1、Table2、……几张表,对于离线数仓的 ODS 表,则需要屏蔽掉业务侧 Mysql 分表的细节和逻辑,这样,问题就聚焦为如何解决分表场景下数据有序的问题。
保障分库分表,甚至不同分表在不同集群的情况下,数据写入到 Kafka 后的有序性。即写入 Delta Lake 的 spark 从某个 topic 读取到逻辑表的数据是 partition 粒度有序的。
保障 ODS 表就绪的时效性,如区分无 binlog 数据的情况下,ODS 层数据也可以按期就绪。此处需要对原有系统进行升级改造,方案如下:
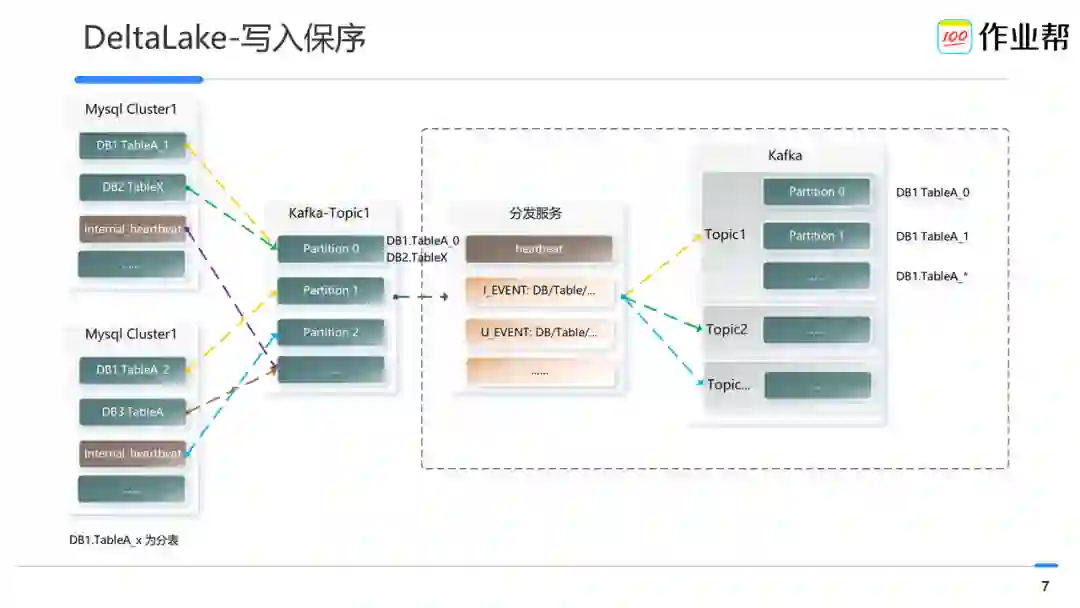
如上图所示:某个 mysql 集群的 binlog 经 canal 采集后写入到特定的 Kafka-topic,但是由于写入时按照 db 和 table(去分表 _* 后缀)做 hash 确定 partition,因此单个 partition 内部会存在多个物理表的 binlog,对于写入 Delta Lake 来说非常不友好。考虑到对其他数据应用方的兼容性,我们新增了数据分发服务:
将逻辑表名(去分表 _* 后缀)的数据写入到对应的 topic,并使用物理表名进行 hash。保障单 partition 内部数据始终有序,单 topic 内仅包括一张逻辑表的数据。
在 mysql 集群内构建了内部的心跳表,来做 canal 采集的延迟异常监控,并基于此功能设置一定的阈值来判断当系统没有 binlog 数据时是系统出问题了还是真的没数据了。如果是后者,也会触发 Delta Lake 进行 savepoint,进而及时触发 snapshot 来保障 ods 表的及时就绪。
通过上述方案,我们将 binlog 数据流式的写入 Delta Lake 中,且表分区就绪时间延迟<10mins。
下面讲下我们在使用 Delta Lake 过程中遇到的性能问题以及对应的解法。
Delta Lake 支持通过 SparkStreamingSQL 的方式来写入数据。

因为要做记录的合并去重,因此这里需要通过 merge into 的方式写入。Delta Lake 更新数据时分为两步:
定位到要更新的文件,默认情况下需要读取全部的文件和 spark 内 batch 的增量数据做 join,关联出需要更新的文件来。
merge 后重新写入这些文件,把老的文件标记为删除。
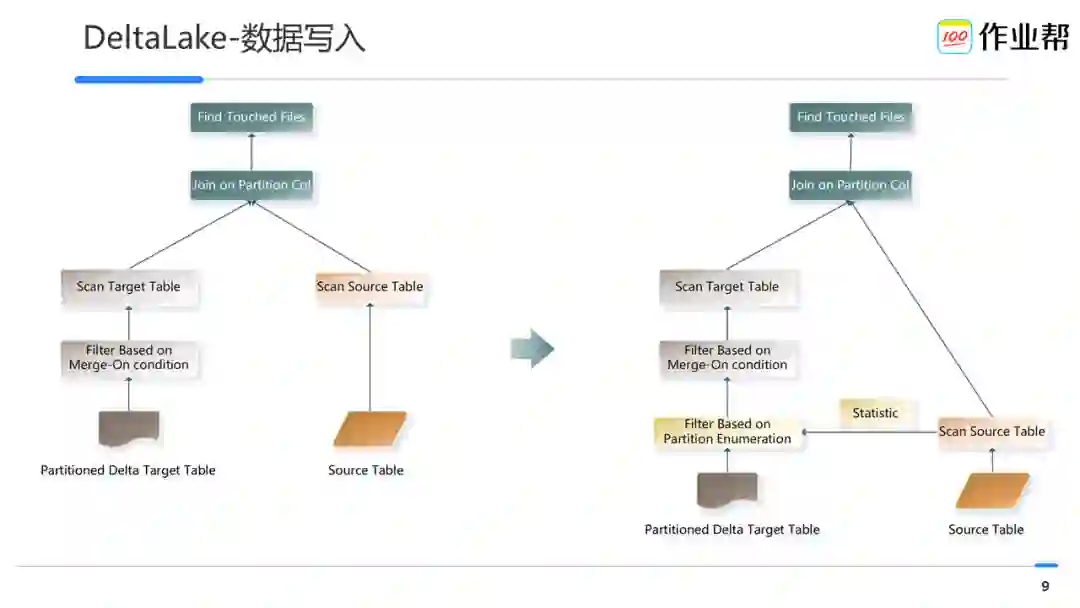
如上左图所示,由于 Delta Lake 默认会读取上个版本的全量文件,因此导致写入性能极低,一次合并操作无法在 spark 一个 batch 内完成。
针对这种场景,对 Delta Lake 做了升级:使用 DPP 做分区剪枝来优化 megre into 的性能,如上右图所示:
分析 merge-on 条件,得到 source 表中对应到 Delta Lake 表分区字段的字段。
统计得到分区字段的枚举列表。
将上步结果转化成 Filter 对象并应用,进一步过滤裁剪数据文件列表。
读取最终的数据文件列表和 batch 的 source 数据关联得到最终需更新的文件列表。
通过 DPP 优化后,Spark 一个 batch(5min 粒度)的处理延迟由最大 20mins+ 减少到 最大~3mins,完全消除了过去因为处理时间过长导致延迟不断叠加的问题。
在解决了数据的写入性能后,我们又遇到了数据读取性能的问题。
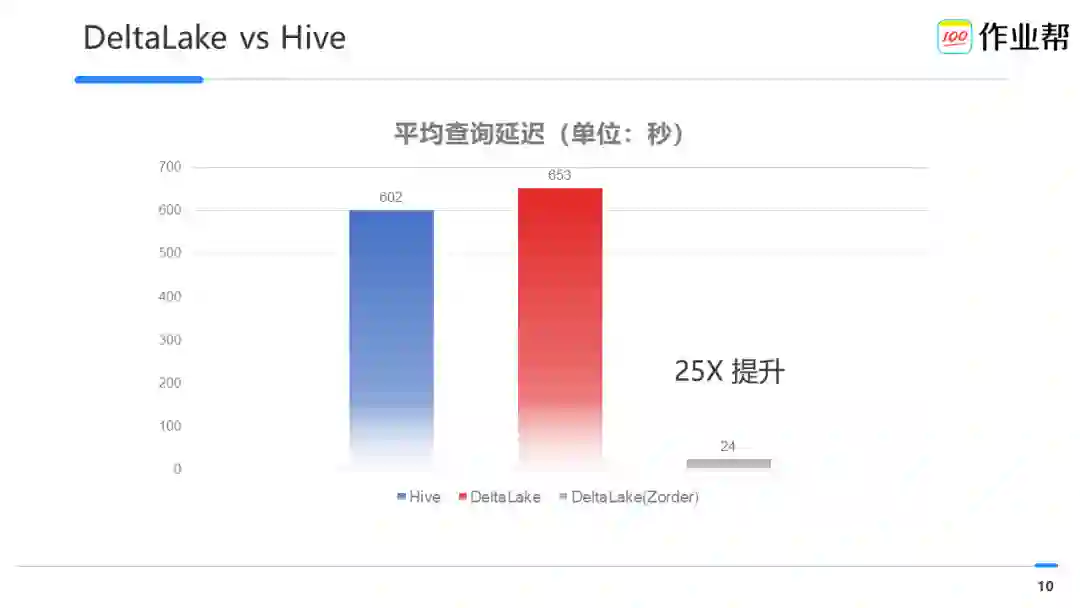
我们使用同样的数据(200 亿 +),使用 Hive 计算,平均延迟 10min+,而使用 Delta Lake 后,平均延迟居然高达~11mins+。分析后发现主要是没有对筛选列使用 Zorder 排序,当开启 Zorder 后,延迟则降低到了~24s,提高了近 25X 性能。、
基于 Zorder 对 Delta Lake 表进行查询优化,主要会涉及两个方面的提升:
Dataskipping
Delta Lake 会按照文件粒度统计各个字段的 max/min 值,用于直接过滤数据文件。
Zorder
一种数据 layout 的方式,可以对数据重排列尽可能保证 Zorder 字段的数据局部性。
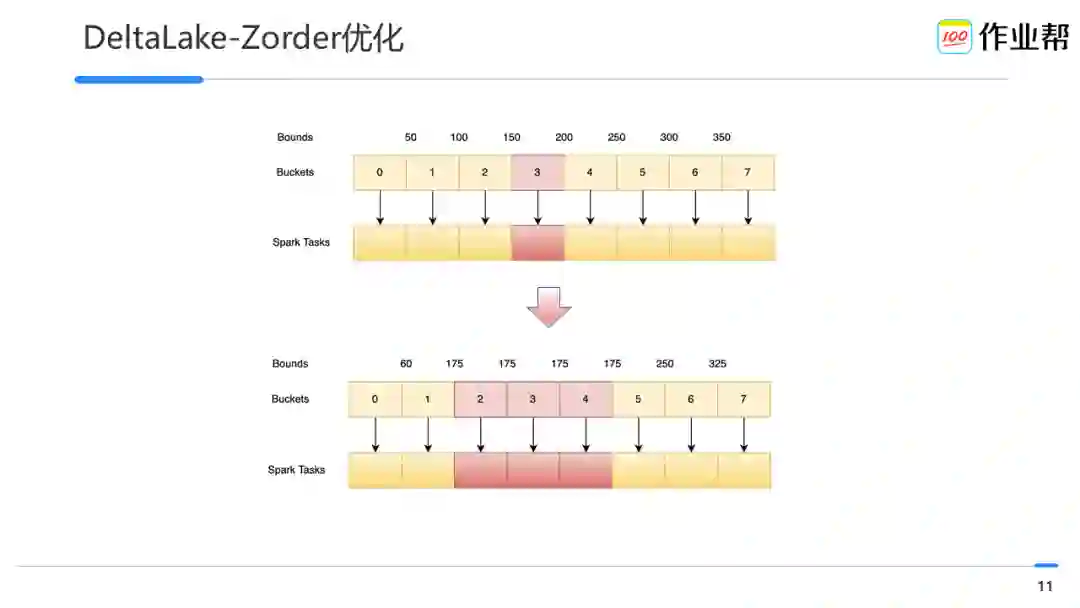
对哪些列开启 Zorder 是按需构建的,常规情况构建时长~30mins,数据倾斜下,构建 Zorder 时长高达~90mins。
针对这两种情况,对 Zorder 进行了优化:
常规情况下,对于多列的 Zorder,由多次遍历数据集改为遍历一次数据集来提升构建效率。构建时长从平均~30mins 降低到~20mins。
数据倾斜下,对于倾斜列所在的 bucket 做了热点分散,构建时长从平均~90mins 降低到~30mins。
经过了近半年多的开发和优化,近期基于 Delta Lake 的离线数仓已经上线,重点是提升分析的查询优化,同时针对有小时全量需求的场景,也同样提供了支持,整体看的效果如下:
就绪时间更快:ODS 替换到 Delta Lake 后,产出时间从之前凌晨 2:00 - 3:00 提前到凌晨 00:10 左右,产出时间提前了 2 个多小时。
能力扩展更广:大数据具备了支持小时全量表的能力,利用 Delta Lake 增量更新的特性,低成本的实现了小时全量的需求,避免了传统方案下读取全量数据的消耗。目前已经应用到了部分核心业务中来,构建小时级全量表,同时时效性上保障从过去的~40mins 降低到~10mins。
查询速度提升:我们重点提升的分析师的即席查询效率,通过将分析师常用的数仓表迁移到 Delta Lake 之后,利用 Zorder 实现了查询加速,查询速度从过去的数十分钟降低到~3mins。
随着 Delta Lake 在作业帮的使用,当前还有一些问题有待解决:
提高修数效能。
使用 hive 时我们可以方便的针对某个历史分区独立修复,但是 Delta Lake 表修数时需要通过回退故障版本后的所有版本。
完全支持 Hive 引擎。
目前我们使用 Delta Lake,主要解决了过去使用 Hive 查询慢、使用 Presto 限制复杂查询的问题,在复杂查询、低延迟上提供了解决方案,但前面提到的 gscd、dataskipping 等特性 hive 还不支持,导致用户无法向使用 hive 一样使用 Delta Lake。
支持 Flink 接入。
我们流计算系统生态主要围绕 flink 构建,引入 Delta Lake 后,也同时使用 spark,会导致我们的流计算生态维护成本加重。
最后,非常感谢阿里云 EMR 数据湖团队,凭借他们在 Delta Lake 中的专业能力和合作过程中的高效支持,在我们这次数据湖迁移过程中,帮助我们解决了很多关键性问题。
作者介绍:
刘晋,作业帮大数据平台技术部负责人,专注于大数据基础架构、数据平台、数据治理工具、数据体系建设
王滨,作业帮大数据平台技术部 - 高级架构师,擅长 SQL 引擎、分布式离线计算、资源调度、湖仓一体建设
AlphaCode编程比赛击败一半程序员;微信超1亿人视频号看春晚,6.6亿人抢红包;Flutter 2.10发布 | Q资讯
用了五年 VS Code,我决定换成 JetBrains...

点个在看少个 bug 👇



