ICCV 2019 | VrR-VG:聚焦视觉相关关系

作者丨梁远智
学校丨西安交通大学硕士生
研究方向丨视觉关系
本文提出视觉相关的对象关系在语义理解上有更高的价值。在视觉关系学习表达中,我们需要关注于视觉相关关系,而避免对于视觉无关的信息学习。由于现有数据中存在大量的非视觉的先验信息,方法上很容易学到简单的位置关系或单一固定关系,而不具备进一步推测学习语义信息的能力。从而导致现有关系数据的表征并不能明显提升语义相关任务性能。
而本文提出明确了视觉关系学习中什么是值得学习的,什么是需要学习的。并且通过实验,也验证了所提出的视觉相关关系数据可以有效的提升特征的语义理解能力。


数据及项目网站:http://vrr-vg.com/
引文
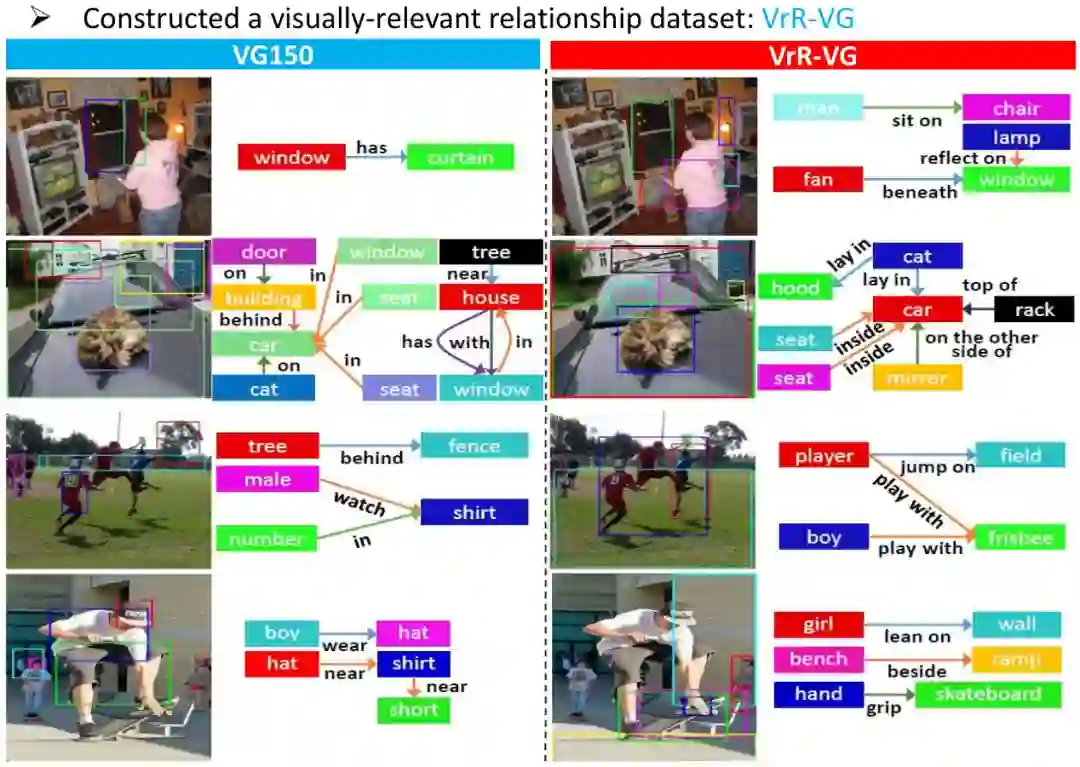
在计算机视觉的研究中,感知任务(如分类、检测、分割等)旨在准确表示单个物体对象信息;认知任务(如看图说话、问答系统等)旨在深入理解整体场景的语义信息。而从单个物体对象到整体场景,视觉关系表征两个物体之间的交互,连接多个物体构成整体场景。关系数据可以作为物体感知任务和语义认知任务之间的桥梁和纽带,具有很高的研究价值。
考虑到关系数据在语义上的这种纽带的作用,对象关系数据应当有效的推进计算机视觉方法对于场景语义理解上的能力。构建从单物体感知,到关系语义理解,到整体场景认知,由微观到宏观,由局部到整体的层次化的视觉理解能力。
但现有关系数据中,由于大量先验偏置信息的存在,导致关系数据的特征并不能有效的利用在语义理解中。其中,位置关系如“on”, “at”等将关系的推理退化为对象检测任务,而单一固定的关系,如“wear”,“has”等,由于数据中主体客体组合搭配固定,此类关系将关系推理退化为简单演绎推理。
因此这些关系数据的大量存在,导致关系特征的学习更多倾向于对单物体感知,而非真正的对场景语义的理解,从而无法使关系数据发挥的作用。同时,这种语义上的、学习上的先验偏置,无法通过常规的基于频率或规则的方法筛选剔除,这导致上述数据端的问题阻碍了关系语义理解上的发展与研究,使得视觉对象关系的研究与语义理解的目标渐行渐远。
本文首先提出视觉相关假设和视觉相关关系判别网络来构建具有更高语义价值的数据集。我们认为,许多关系数据不需要理解图像,仅仅通过单物体感知上的标签信息(如 bounding box, class)就可以推断的是关系学习中应避免的,即非视觉相关关系。而在关系数据中,对于视觉相关关系的学习与理解,将逼迫网络通过图像上的视觉信息,推理得到关系语义信息,而不是依赖基于单物体感知的能力,拟合先验偏置的标签。
在我们的方法中,我们设计了一个视觉相关判别网络,通过网络自主的学习,分辨那些仅通过一些标签信息即可推断的非视觉相关关系,从而保证数据中留存的都是具有高语义价值的视觉相关关系。此外,我们设计了一个考虑关系的联合训练方法,有效的学习关系标签的信息。
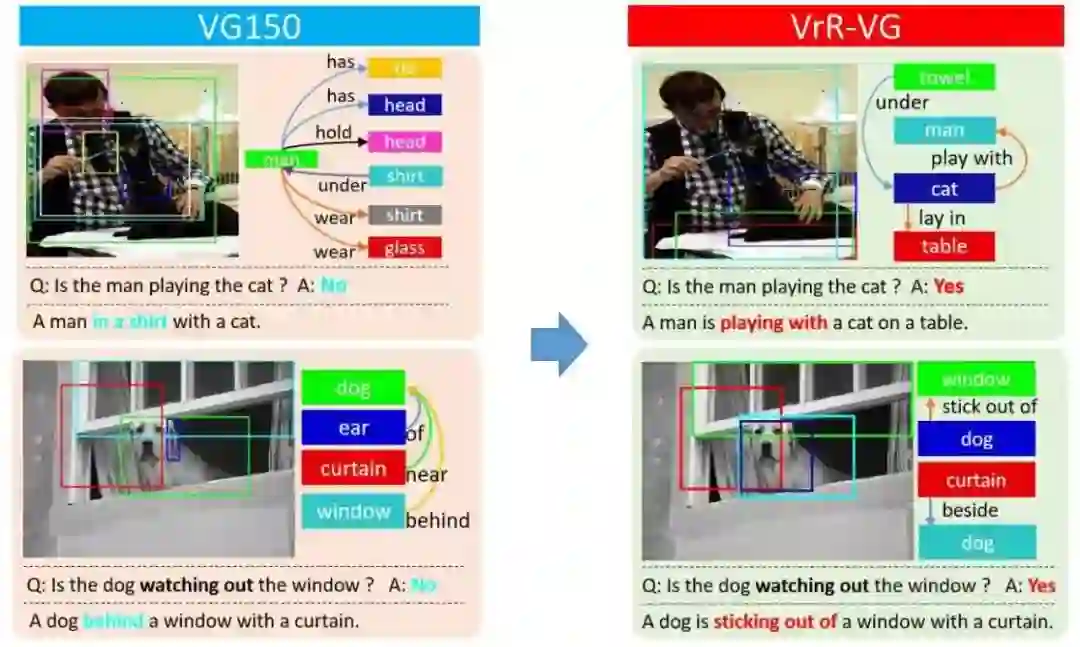
在实验中,我们从两个方面验证了我们的想法。关系表征学习中,在场景图生成任务上,我们的视觉相关关系有效的拉大了学习型方法与非学习型方法之间的性能差距,由此证明了非视觉关系是关系数据中的先验偏置且通过简单方法即可推断。另一方面,通过学习视觉相关关系,我们得到的特征具有更好的语义表达与理解能力。该特征也在问答系统、看图说话中展现出更好的性能,由此证明了视觉相关关系是真正需要被学习,且更有利于提升语义理解能力。
方法
视觉相关判别网络(VD-Net)
提出的 VD-Net 用于分辨对象关系是否视觉相关。网络仅需要物体对象的位置信息 bounding box 和类别信息 class,并将两种信息做编码输入,而不考虑图像信息。具体输入如下。
位置编码:
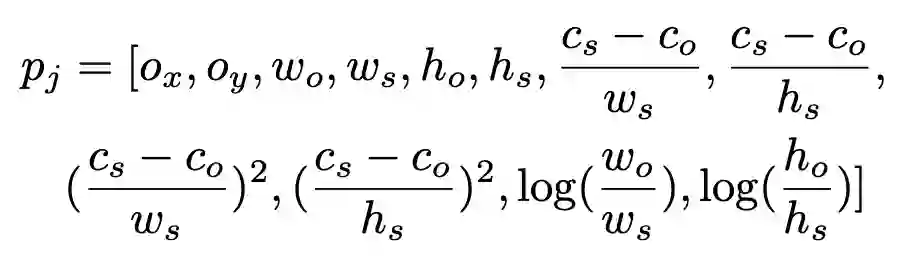
其中含有物体中心点、宽高、位置关系信息、尺寸信息等。
针对类别信息,我们使用类别标签的 glove 特征向量作为输入。网络设置如下:
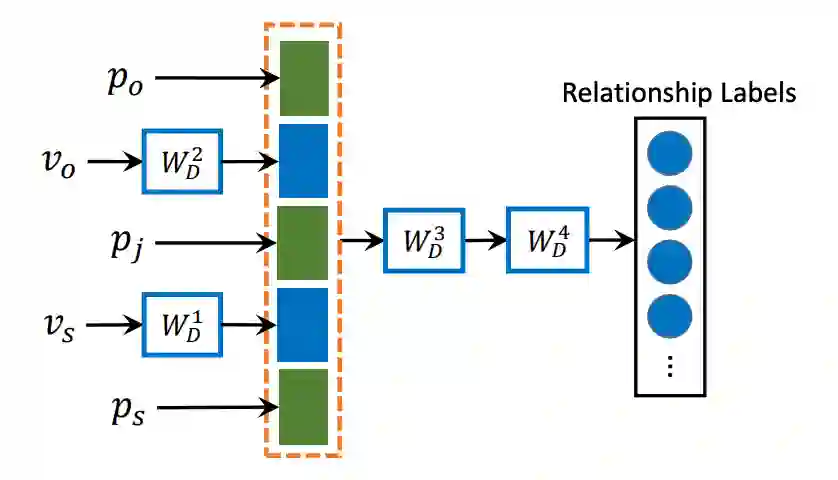
为了避免过拟合,网络设计需要尽可能的小。网络包含 4 个全连接层,其中,
,
分别是主体、客体的位置编码及二者联合位置编码。
,
分别是主体、客体对象的类别词向量。
通过 VD-Net 网络的学习,可以发现现有的数据集中,关系预测具有很高的准确率,在 VG150 中,37% 的标签在 VD-Net 中有至少 50% 的准确率。

考虑关系信息的联合特征学习
我们提出的方法如下:
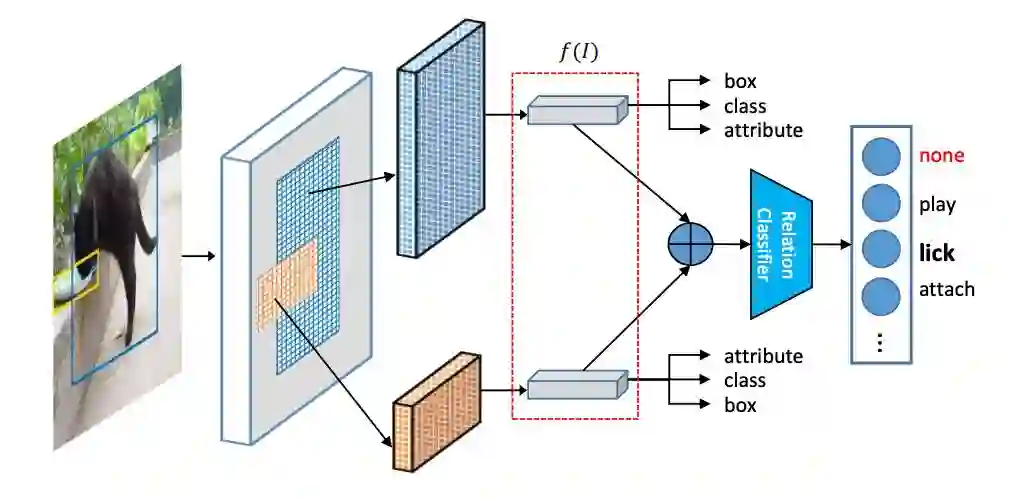
其中,我们使用 Faster-RCNN 用于特征提取,f(I) 取自于 RPN 部分。网络综合的学习位置、类别、属性和关系信息。通过对象关系的信息,进一步拓展特征的语义表征能力。
实验
场景图生成实验
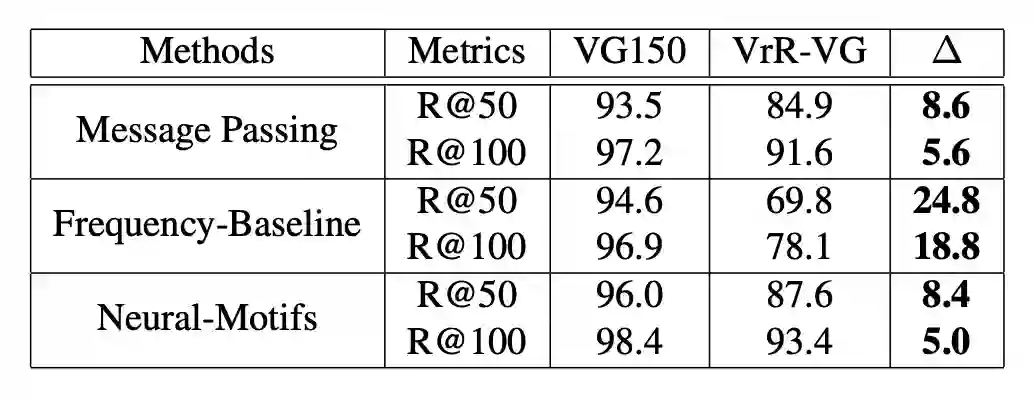
Freqency-Baseline 是非学习型方法,基于对数据的统计。在我们的实验中,VrR-VG 明显的拉开了非学习方法与可学习方法之间的性能差距。更加凸显出场景图生成任务中,各个方法的真实性能。同时,实验也说明非视觉相关的关系比较容易。相对来说,在含有大量非视觉关系的情况下,网络学习到的内容和基于统计的非学习型方法直接推断的内容差距有限。
问答系统实验
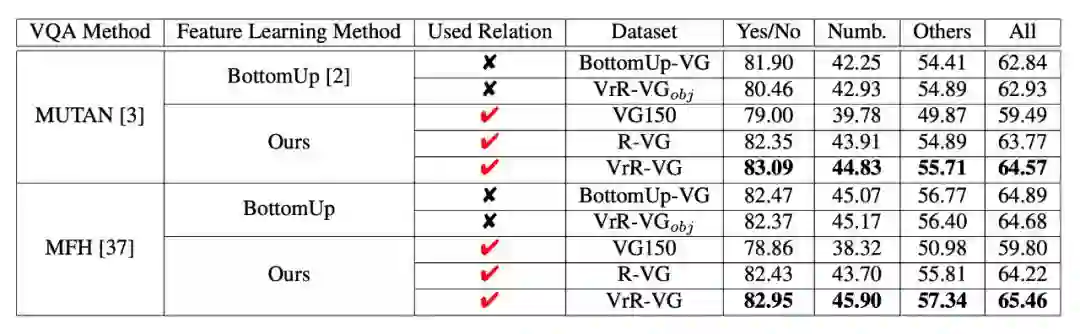
在问答系统实验中,通过学习视觉相关关系,特征具有更好的性能,在指标上有明显的提升。

在具体的案例分析上,通过学习视觉相关关系,特征能够提供更多的语义信息。一些通过单物体信息无法正确回答的问题,在我们的方法下有明显的效果。
看图说话实验
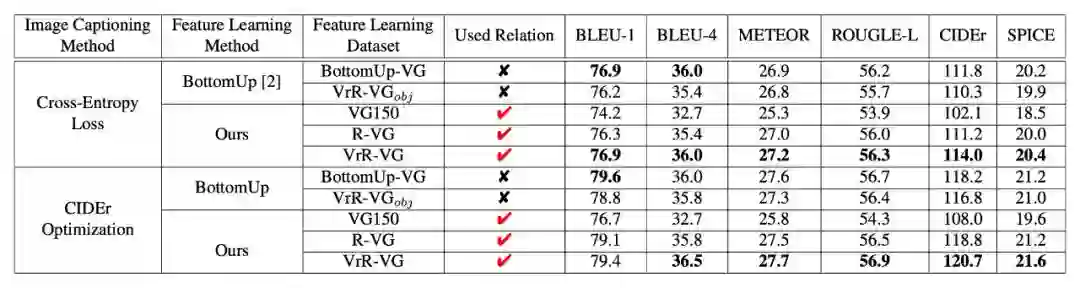
在看图说话的任务中,通过学习视觉相关关系,任务的性能也有提升。

通过对生成的句子案例分析,我们可以发现,我们的方法给出了一些具有鲜明语义关系的句子。有时句子整体会有更加鲜活的表达,内涵更加丰富的交互信息。
结论
在对象关系的学习与应用中,我们需要关注视觉相关关系的学习。现有关系数据不能有效的利用在语义相关的任务中,其主要问题是在数据侧而非方法侧。为了使对象关系应该在语义理解上有更广泛深入的引用,需要首先明晰那些关系需要学习。在解决什么需要学的前提下,才能在如何学习的方法侧走的更远。

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文


