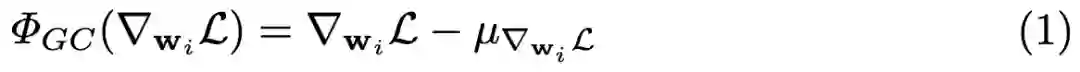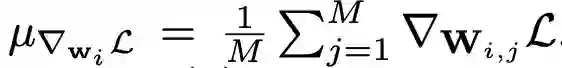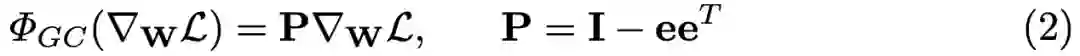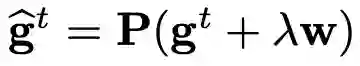![]()
本文约3284字,建议阅读8分钟。
本文介绍阿里达摩院的研究者另辟蹊径,直接对梯度下手,提出全新的梯度中心化方法。只需一行代码即可嵌入现有的 DNN 优化器中,还可以直接对预训练模型进行微调。
优化技术对于深度神经网络 (DNN) 的高效训练至关重要。以往的研究表明,使用一阶和二阶统计量(如平均值和方差)在网络激活或权重向量上执行 Z-score 标准化(如批归一化 BN 和权重标准化 WS)可以提升训练性能。
已有方法大多基于激活或权重执行,最近阿里达摩院的研究人员另辟蹊径提出了一种新型优化技术——梯度中心化(gradient centralization,GC),该方法通过中心化梯度向量使其达到零均值,从而直接在梯度上执行。
我们可以把 GC 方法看做对权重空间和输出特征空间的正则化,从而提升 DNN 的泛化性能。此外,GC 还能提升损失函数和梯度的 Lipschitz 属性,从而使训练过程更加高效和稳定。
GC 的实现比较简单,只需一行代码即可将 GC 轻松嵌入到现有基于梯度的 DNN 优化器中。它还可以直接用于微调预训练 DNN。研究者在不同应用中进行了实验,包括通用图像分类和微调图像分类、检测与分割,结果表明 GC 可以持续提升 DNN 学习性能。
-
论文地址:https://arxiv.org/pdf/2004.01461.pdf
-
项目地址:https://github.com/Yonghongwei/Gradient-Centralization
不同于基于激活或权重向量运行的技术,该研究提出了一种基于权重向量梯度的简单而有效的 DNN 优化技术——梯度中心化(GC)。
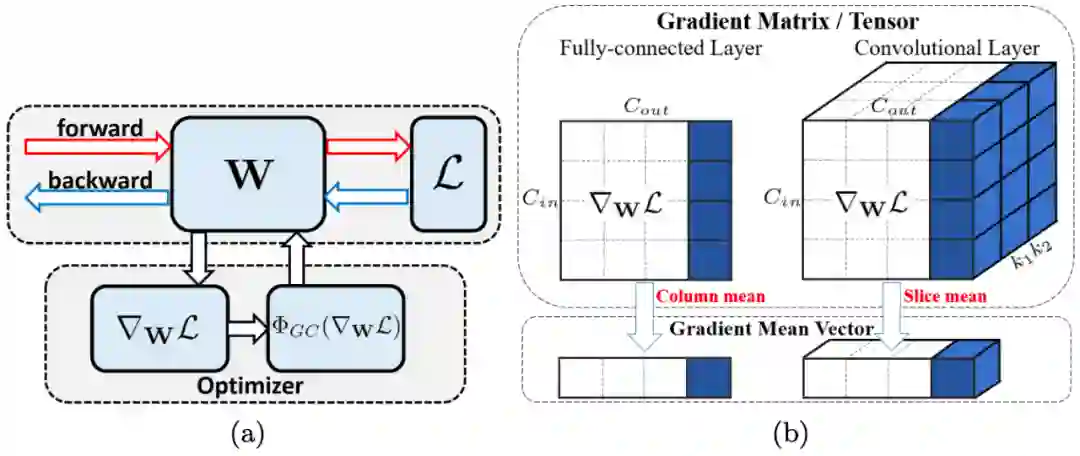
如图 1(a) 所示,GC 只是通过中心化梯度向量使其达到零均值。只需要一行代码,即可将其轻松嵌入到当前基于梯度的优化算法(如 SGDM、Adam)。
尽管简单,但 GC 达到了多个期望效果,比如加速训练过程,提高泛化性能,以及对于微调预训练模型的兼容性。
图 1:(a) 使用 GC 的示意图。W 表示权重,L 表示损失函数,∇_WL 表示权重梯度,Φ_GC(∇_WL) 表示中心梯度。如图所示,用 Φ_GC(∇_WL) 替换 ∇_WL 来实现 GC 到现有网络优化器的嵌入,步骤很简单。(b) 全连接层(左)和卷积层(右)上梯度矩阵/权重张量的 GC 运算。GC 计算梯度矩阵/张量的每列/slice 的平均值,并将每列/slice 中心化为零均值。
-
提出了一种通用网络优化技术——梯度中心化(GC),GC 不仅能够平滑和加速 DNN 的训练过程,还可以提升模型的泛化性能。
-
分析了 GC 的理论性质,指出 GC 通过对权重向量引入新的约束来约束损失函数,该过程对权重空间和输出特征空间进行了正则化,从而提升了模型的泛化性能。此外,约束损失函数比原始损失函数具备更好的利普希茨属性,使得训练过程更加稳定高效。
研究动机
研究者提出了这样的疑问:除了对激活和权重的处理外,是否能够直接对梯度进行处理,从而使训练过程更加高效稳定呢?一个直观的想法是,类似于 BN 和 WS 在激活与权重上的操作,使用 Z-score 标准化方法对梯度执行归一化。不幸的是,研究者发现单纯地归一化梯度并不能提高训练过程的稳定性。于是,研究者提出一种计算梯度向量均值并将梯度中心化为零均值的方法——梯度中心化。该方法具备较好的利普希茨属性,能够平滑 DNN 的训练过程并提升模型的泛化性能。
GC 公式
对于全连接层或卷积层,假设已经通过反向传播获得梯度,那么对于梯度为 ∇_w_i L (i = 1, 2, ..., N ) 的权重向量 w_i,GC 的公式如下所示:
![]()
其中
![]()
GC 的公式很简单。如图 1(b) 所示,只需要计算权重矩阵列向量的平均值,然后从每个列向量中移除平均值即可。
公式 1 的矩阵表述如下所示:
![]()
在实际实现中,我们可以从每个权重向量中直接移除平均值来完成 GC 操作。整个计算过程非常简单高效。
GC 嵌入到 SGDM/Adam 中,效果如何?
GC 可以轻松嵌入到当前的 DNN 优化算法中,如 SGDM 和 Adam。在得到中心化梯度 Φ_GC(∇_wL) 后,研究者直接使用它更新权重矩阵。算法 1 和算法 2 分别展示了将 GC 嵌入两大最流行优化算法 SGDM 和 Adam 的过程。此外,如要使用权重衰减,可以设置
![]()
,其中 λ 表示权重衰减因子。
将 GC 嵌入到大部分 DNN 优化算法仅需一行代码,就可以微小的额外计算成本执行 GC。例如,研究者使用 ResNet50 在 CIFAR100 数据集上进行了一个 epoch 的训练,训练时间仅增加了 0.6 秒(一个 epoch 耗时 71 秒)。
我们可以把 GC 看作具备约束损失函数的投影梯度下降方法。约束损失函数及其梯度的利普希茨属性更优,从而使训练过程更加高效稳定。
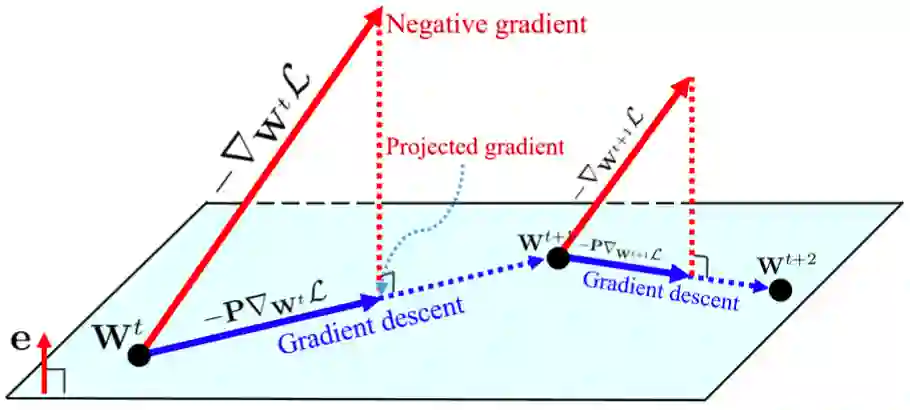
之前的研究已经说明了投影梯度方法的特性,即投影权重梯度将限制超平面或黎曼流形的权重空间。类似地,我们也可以从投影梯度下降的角度看待 GC 的作用。下图 2 展示了使用 GC 方法的 SGD:
图 2:GC 方法的几何解释。梯度被投影在超平面 e^T (w − w^t) = 0 上,投影梯度被用于更新权重。
优化图景平滑:之前的研究表明 BN 和 WS 可以平滑优化图景。尽管 BN 和 WS 在激活和权重上执行,但它们隐式地限制了权重梯度,从而使权重梯度在快速训练时更具预测性,也更加稳定。
类似的结论也适用于 GC 方法,研究者对比了原始损失函数 L(w) 和公式 4 中约束损失函数的利普希茨属性,以及函数梯度的利普希茨属性。
梯度爆炸抑制:GC 对于 DNN 训练的另一个好处是避免梯度爆炸,使训练更加稳定。这一属性类似于梯度剪裁。梯度太大会导致权重在训练过程中急剧变化,造成损失严重振荡且难以收敛。
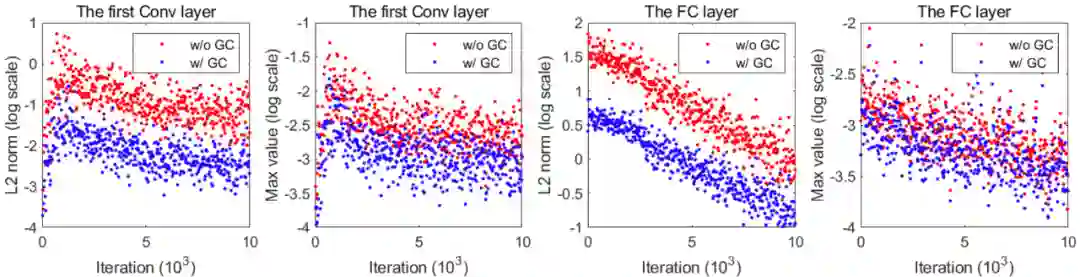
为了研究 GC 对梯度剪裁的影响,研究者在图 4 中展示了,在使用和不使用 GC 方法时(在 CIFAR100 上训练得到的)ResNet50 第一个卷积层和全连接层的梯度矩阵最大值和 L2 范数。从图中我们可以看到,在训练过程中使用 GC 方法使得梯度矩阵的最大值和 L_2 范数有所降低。
图 4:梯度矩阵或张量的 L_2 范数(对数尺度)和最大值(对数尺度)随迭代次数的变化情况。此处使用在 CIFAR100 上训练得到的 ResNet50 作为 DNN 模型。左侧两幅图展示了在第一个卷积层上的结果,右侧两幅图展示了全连接层上的结果。红点表示不使用 GC 方法的训练结果,蓝点反之。
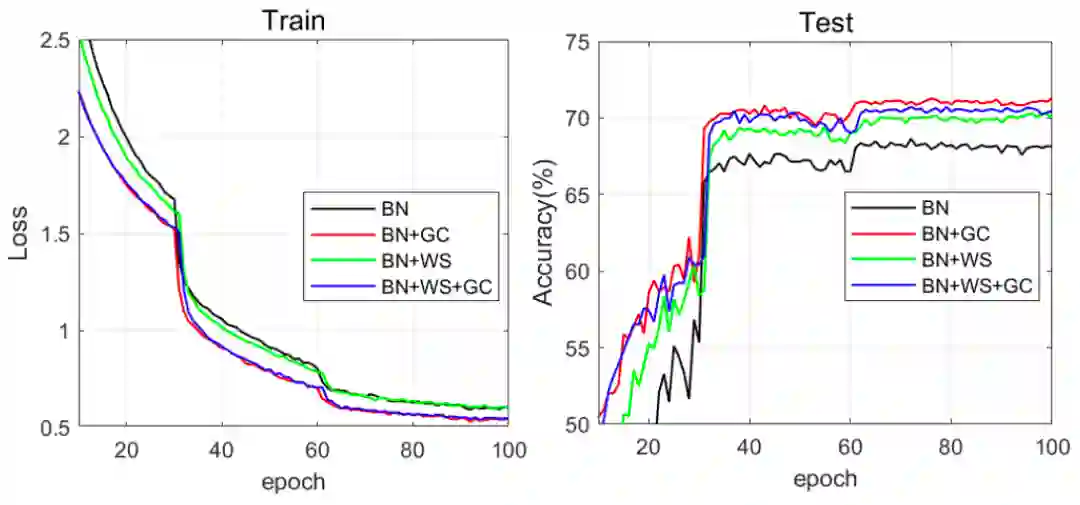
下图 5 展示了四种组合的训练损失和测试准确率曲线。
与 BN 相比,BN+GC 的训练损失下降得更快,同时测试准确率上升得也更快。对于 BN 和 BN+WS 而言,GC 能够进一步加快它们的训练速度。此外,我们可以看到,BN+GC 实现了最高的测试准确度,由此验证了 GC 能够同时加速训练过程并增强泛化性能。
图 5:在 Mini-ImageNet 数据集上,训练损失(左)和测试准确率(右)曲线随训练 epoch 的变化情况。ResNet50 被用作 DNN 模型。进行对比的优化方法包括 BN、BN+GC、BN+WS 和 BN+WS+GC。
下表 3 展示了不同权重衰减设置下的测试准确率变化,包括 0、1e^-4、2e^-4、5e^-4 和 1e^-3。优化器是学习率为 0.1 的 SGDM。从表中可以看到,权重衰减的性能通过 GC 实现了持续改善。
表 3:在不同权重衰减设置下,使用 ResNet50 在 CIFAR100 数据集上的测试准确率。
下表 4 展示了 SGDM 和 Adam 在不同学习率下的测试准确率变化。
表 4:使用 ResNet50,不同学习率的 SGDM 和 Adam 在 CIFAR100 数据集上的测试准确率。
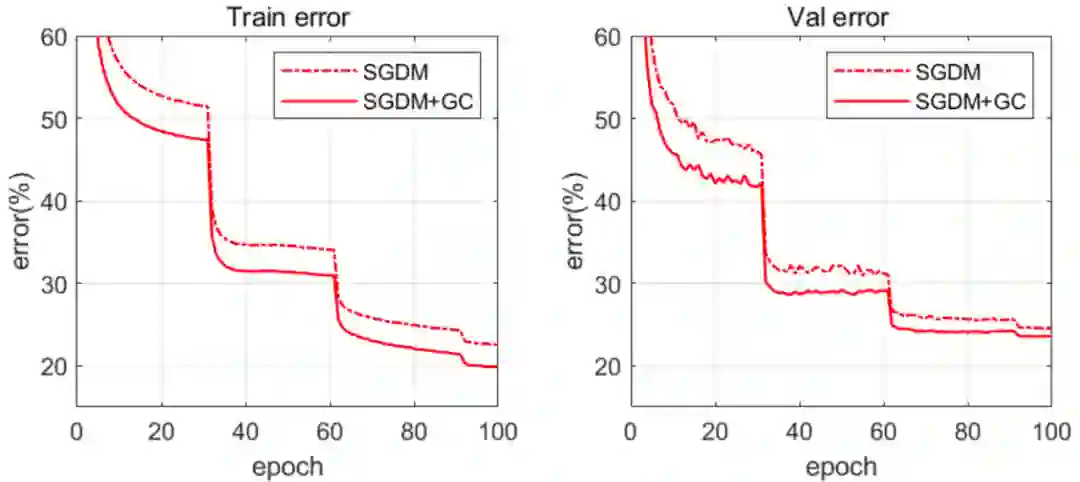
下图 6 展示了 ResNet50 的训练和验证误差曲线(GN 被用于特征归一化)。我们可以看到,借助于 GN,GC 可以大大加速训练过程。
图 6:在 ImageNet 数据集上,训练误差(左)和验证误差(右)曲线随训练 epoch 的变化情况。
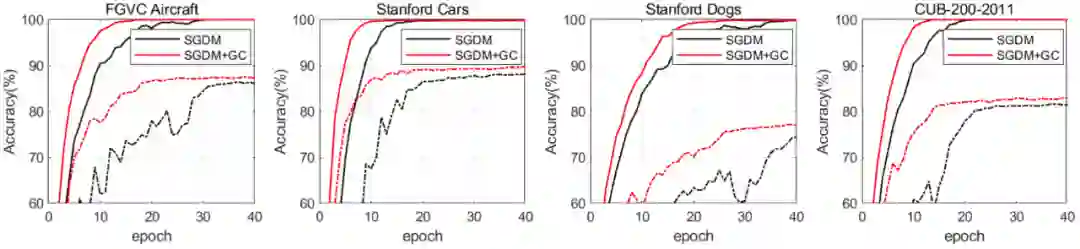
下图 7 展示了在 4 个细粒度图像分类数据集上执行前 40 个 epoch 时,SGDM 和 SGDM+GC 的训练和测试准确率。
图 7:在 4 个细粒度图像分类数据集上,训练准确率(实线)和测试准确率(虚线)曲线随训练 epoch 的变化情况。
下表 8 展示了 Faster R-CNN 的平均精度(Average Precision,AP)。我们可以看到,在目标检测任务上,使用 GC 训练的所有骨干网络均实现了约 0.3%-0.6% 的性能增益。
表 8:使用 Faster-RCNN 和 FPN,不同骨干网络在 COCO 数据集上的检测结果。
下表 9 展示了边界框平均精度(AP^b)和实例分割平均精度(AP^m)。我们可以看到,目标检测任务上的 AP^b 提升了 0.5%-0.9%,实例分割任务上的 AP^m 提升了 0.3%-0.7%。
表 9:使用 Mask-RCNN 和 FPN,不同骨干网络在 COCO 数据集上的检测和分割结果。
研究者开源了论文中所提方法,使用 PyTorch 实现。包括 SGD_GC、SGD_GCC、SGDW_GCC、Adam_GC、Adam_GCC、AdamW_GCC 和 Adagrad_GCC 多种优化器,其相应实现在 SGD.py 中提供。后缀为「_GC」的优化器使用 GC 对卷积层和全连接层进行优化,而后缀为「_GCC」的优化器仅可用于卷积层。
而想要使用这些优化器非常简单,只需使用如下命令 import 对应的模块即可。
论文一作 Hongwei Yong(雍宏巍)分别在 2013 年和 2016 年取得了西安交通大学的本科与硕士学位,目前是香港理工大学电子计算系博士生。他的主要研究领域包括图像建模和深度学习等。
其余三位作者均供职于阿里达摩院,其中 Jianqiang Huang(黄建强)为达摩院资深算法专家,Xiansheng Hua(华先胜)为达摩院城市大脑实验室负责人,Lei Zhang(张磊)为达摩院城市大脑实验室高级研究员。
![]()
![]()