Google提出新型学习范式,或将彻底改变机器学习领域
最近,Google提出了一种称之为Deep Memory的新型学习范式,并在生成式建模任务上使用MenGEN算法将此范式得以实现,经过一系列实验表明,科学家们发现,要想尽可能多地保留样本中的信息,较好方法是将它们完全存储起来,即Memory is All You Need。
最近,我们提出了一种新型的学习范式,我们将其称之为Deep Memory。它有可能彻底革新机器学习领域。令人惊奇的是,与深度学习不同,这种范式还没有被重新加以改造。这种方法的核心是“Learning By Heart”原则,而这一原则在全世界的小学中得到了充分研究。受到诗歌朗诵或π小数记忆的启发,我们提出了一种模仿人类行为的具体算法。我们在生成式建模任务上实现了这个范式,并将其应用于图像、自然语言,甚至π小数,只要人们能够将它们打印成文本。我们所提出的算法甚至在独热学习环境中生成了本篇论文。通过精心设计的实验,我们表明,通过任何统计测试或度量进行衡量,所生成的样本都无法与训练样本相区分。

我们遵循LaLoudouana和Tarare于2003年所开启,后来又被Albanie等人于2017年、Garfinkel等人于2017年所延伸的基本科学研究路线。受这些方法的启发,我们将着重点放在生成式建模的最终目标上:就像输入分布那样输出相同的分布。一直以来,Garbage In,Garbage Out在机器学习中都是一个被广泛研究的谚语,而我们的主要贡献在于真正地将其付诸实现。
在我们详细介绍这个理论和实验之前,不妨退一步思考,想一想我们为什么要进行生成式建模?会议结束后我们可以仔细想一下,因为就目前来看,距下一次会议还有一段时间。
众所周知,生成式模型和蛋糕一样好,试问有谁不喜欢蛋糕呢?但现在,我们假设蛋糕是一个谎言。生成式模型从给定的数据分布中抽取样本,并从中学习一个模型。然后,我们希望我们可以利用这一模型解决其他任务。通过仔细研究Shannon于1948发表的论文,人们可以注意到,从样本中尽可能多地保留信息的较好方法是将它们完全存储起来。毕竟,信息不丢失,我们就没有什么可失去的。
可惜的是,仅有想法是不够的。一个重要的新想法是利用先进的数据结构,例如利用列表,甚至哈稀图来进行生成式建模。据我们所知,使用那些的尖端技术(Knuth于1997年,Cormen于2009年提出),我们能够超越那些在80年代被称为是神经网络的旧技术(这些技术不过是简单的加法和乘法而已)。
我们的贡献
•我们提出了一种全新颖的学习范式。对于一个具体应用而言,我们展示了如何推导出最终的生成式建模算法,该算法证明了输出与输入具有相同的分布。
•得益于CPU出色的算法效率,GPUs可以再次免费地应用于游戏。计算效率的主要缺点是,博士生目前可以与大型组织展开竞争,而大型组织却不能利用他们更先进的基础设施,这显然是不公平的,因为在建设基础设施的过程中要克服重重困难。
•从统计数据来看,我们难以区分生成式样本与真实样本。因此我们提出了Rademacher掷硬币度量(Rademacher Coin Flipping),它可以更可靠地给出相似的结果,从而结束了关于生成式建模度量的长期争论。
算法
有关更多细节都在算法1中体现。我们始终在强调该算法是灵活的,并且可以应用更为复杂的数据结构,如哈希图。

算法1:MemGEN
实证评估
为了展示我们的研究结果,我们将演示这种简单的方法是如何优于当前较先进的技术的。目前用于评估生成式模型的较佳度量指标是基于两个样本之间的距离,以及人为评估。我们对这两个操作都加以执行以量化我们算法的性能。
定量结果
两个样本之间的距离:给定一个来自真实分布的样本,以及一个来自生成式分布的样本,我们测量两个基本分布之间的相似程度。显然,我们使用测试集来表示真实的分布,因为采用训练集不会揭示可能存在的过度拟合问题。实验结果表明,我们的结果比实施在所有距离度量标准中的任何较先进的结果要好得多。图1说明了这些结果。
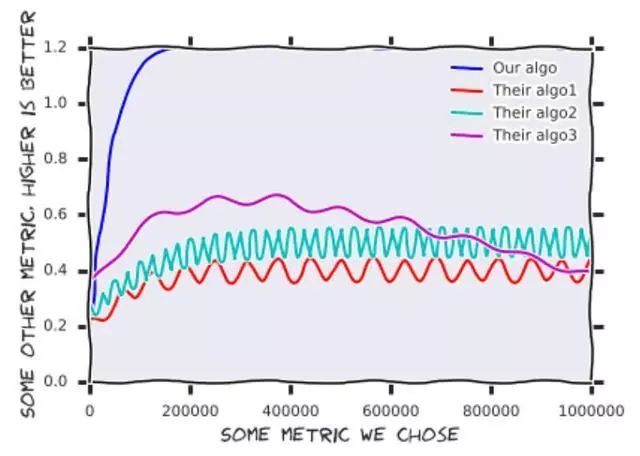
图1:使用我们的算法所实现的结果。优点是这个数据可以重复用于其他论文。
人为评估:评估者显示了两张图像,一张是从模型中抽样获得的的,另一张则是从一个保留组中抽样获得的,他们必须做出决定:哪一张看起来更好。图2显示了人为评估的结果,表明人类无法区分真实的样本和虚假的样本。事实上,我们无法使用无偏差掷硬币的结果对这些结果进行区分。因此,我们现在提出使用投币替代模型评估,从而解决这个长期存在的问题,并节省大量资源。我们称之为Rademacher掷硬币度量。
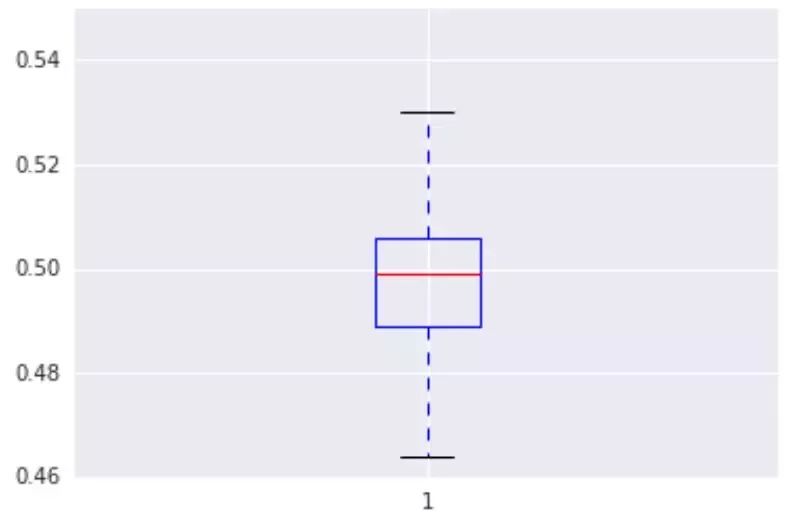
图2:人为评估,来自测试集和生成式模型的样本并排显示,以供人类评估员校准。
文本
对于文本建模,我们考虑了一个自回归--双向长短期记忆网络--注意力--循环神经网络(autoregressive-bilstm-attention-cnn)模型。最后,我们通过恒等函数(identity function)解决了这个问题,因为它是自动可逆的,这很好。
生成的图像
在图3中,我们展示了一些具有代表性的,在互联网图像上进行训练后生成的MemGEN图像。在那些未经训练的人们看来,模型似乎崩溃了,只能生成猫的照片。也许互联网上充满了猫的图像?对于在网上发现的自然图像的快速估计似乎证实了这一假设,但需要进一步调查。

图3:从随机互联网图像中进行学习后,MemGEN所生成的随机图片。这证明,生成的数据分布代表学习分布。
我们提出了一种全新的生成式建模算法,该算法具有独特的优点、很好的属性,并且在一系列重要指标上表现出优异的性能。与LaLoudouana和Tarare在2003年提出的结论相比,我们甚至不需要选择数据集,只需要确定度量即可。本文是依照最严格的科学原则撰写的,因此文中显露出的任何瑕疵都只是单纯的巧合。
文章来源:雷克世界

《OpenCV计算机视觉产品实战》关注怎样运用OpenCV编写程序,解决实际项目问题,课程注重运用而非理论,因此即使你不具备基础知识,但是在一步一步的讲解中,按图索骥,也能够快速入门,并且建立起知识框架;对于具备一定基础的开发者来说,学习本门课程能够加速对图像处理程序的理解,并且逐渐积累起自己的开发框架。点击下方二维码报名课程




