一次性付费进群,长期免费索取教程,没有付费教程。
教程列表见微信公众号底部菜单
进微信群回复公众号:微信群;QQ群:460500587
![]()
微信公众号:计算机与网络安全
ID:Computer-network
本文将从网站上获取免费的代理服务器。使用Scrapy获取代理服务器后,一一验证哪些代理服务器可用,最终将可用的代理服务器保存到文件。
首先要做的是找到免费代理服务器的来源。浏览器中打开百度,搜索“免费代理服务器”。
先在www.proxy360.cn中获取代理服务器。如果数量不够,可以在www.xicidaili.com中获取代理服务器。
在浏览器中打开这两个站点,观察所需的项目。发现大部分的项目都相同,共有的项目有服务器IP、服务器端口、是否匿名、服务器位置。xicidaili站点中独有的项有服务协议。最后还应该添加获取服务器的来源站点。知道了这些内容,items.py文件基本已经出来了。
打开Putty连接到Linux。在工作目录下创建Scrapy项目,并根据提示依照spider基础模版创建一个spider。执行命令:
scrapy startproject getProxy
scrapy genspider proxy360Spider proxy360.cn
这里创建了一个名为getProxy的Scrapy项目,并创建了一个名为proxy360Spider.py的Spider文件。
items.py包含6项。items.py文件内容如下:
1 # -*- coding: utf-8 -*-
2
3 # Define here the models for your scraped items
4 #
5 # See documentation in:
6 # http://doc.scrapy.org/en/latest/topics/items.html
7
8 import scrapy
9
10
11 class GetproxyItem(scrapy.Item):
12 # define the fields for your item here like:
13 # name = scrapy.Field()
14 ip = scrapy.Field()
15 port = scrapy.Field()
16 type = scrapy.Field()
17 loction = scrapy.Field()
18 protocol = scrapy.Field()
19 source = scrapy.Field()
需要几项,就填入几项。最简模式就是只要代理IP和端口。这个文件没什么好解释的,比较简单直白。
(2)修改Spider文件proxy360Spider.py
先把proxy360Spider.py文件放到一边。使用scrapy shell命令查看一下连接网站返回的结果和数据,进入getProxy项目下的任意目录下,执行命令:
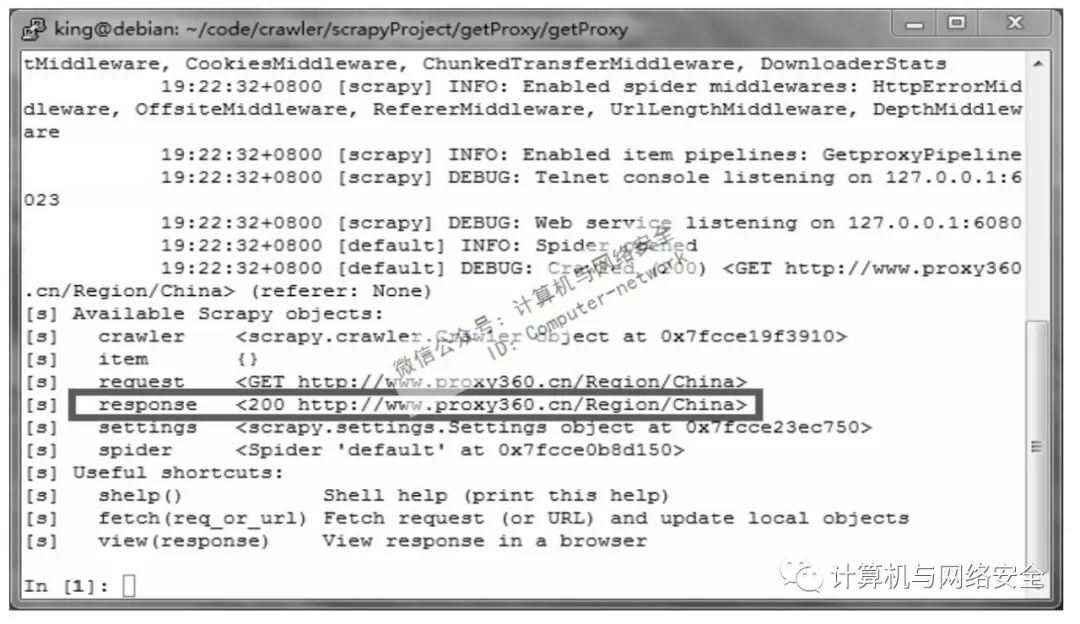
scrapy shell http://www.proxy360.cn/Region/China
![]()
图1 scrapy shell
从response的返回代码可以看出request请求正常返回。再查看一下response的数据内容,执行命令:
response.xpath('/*').extract()
![]()
图2 response数据
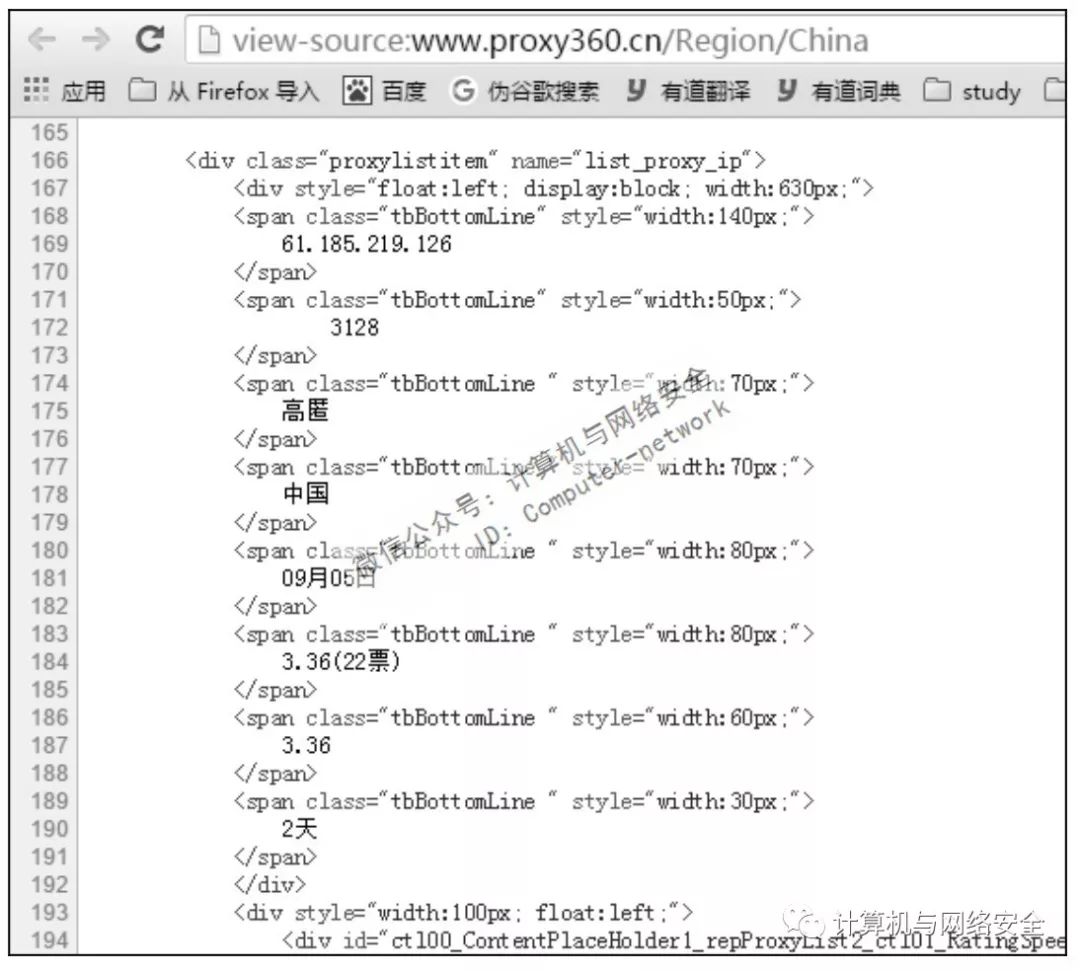
返回的数据中含有代理服务器(难道返回代码为200时,还有返回数据不含代理服务器的吗?这个还真有)。测试一下如何使用选择器在response中的得到所需的数据。在浏览器中打开http://www.proxy360.cn/Region/China,在网页的任意空白处右击,选择“查看网页源代码”,打开页面的源代码网页,如图3所示。
![]()
图3 页面源代码
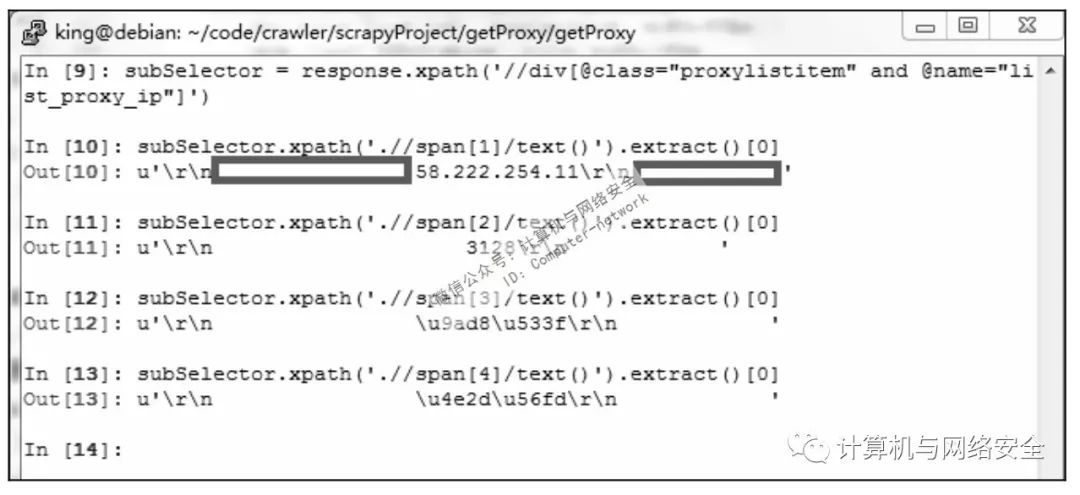
观察一下,似乎所有的数据块都是以<div class="proxylistitem" name="list_proxy_ip">这个tag开头的。在scrapy shell中测试一下,回到scrapy shell中,执行命令:
subSelector=response.xpath('/div[@class="proxylistitem" and @name="list_proxy_ip"]')
subSelector.xpath('.//span[1]/test()').extract()[0]
subSelector.xpath('.//span[2]/test()').extract()[0]
subSelector.xpath('.//span[3]/test()').extract()[0]
subSelector.xpath('.//span[4]/test()').extract()[0]
![]()
图4 proxy360Spider测试选择器
现在如何用选择器从response中获取所需数据的方法也出来了,接下来可以开始编写Spider文件proxy360Spider.py。proxy360Spider.py的内容如下:
1 # -*- coding: utf-8 -*-
2 import scrapy
3 from getProxy.items import GetproxyItem
4
5 class Proxy360Spider(scrapy.Spider):
6 name = "proxy360Spider"
7 allowed_domains = ["proxy360.com"]
8 nations=['Brazil','China','America','Taiwan','Japan','Thailand','Vietnam','bahrein']
9 start_urls = []
10 for nation in nations:
11 start_urls.append('http://www.proxy360.cn/Region/' + nation)
12
13
14 def parse(self, response):
15 subSelector = response.xpath('//div[@class="proxylistitem" and @name="list_proxy_ip"]')
16 items = []
17 for sub in subSelector:
18 item = GetproxyItem()
19 item['ip'] = sub.xpath('.//span[1]/text()').extract()[0]
20 item['port'] = sub.xpath('.//span[2]/text()').extract()[0]
21 item['type'] = sub.xpath('.//span[3]/text()').extract()[0]
22 item['loction'] = sub.xpath('.//span[4]/text()').extract()[0]
23 item['protocol'] = 'HTTP'
24 item['source'] = 'proxy360'
25 items.append(item)
26 return items
在http://www.proxy360.cn/Region/China页面中并没有显示服务器使用的协议。一般都是HTTP协议,所以item['protocol']统一设置成了HTTP。而数据来源都是proxy360网站,item['source']都设置成了proxy360。
(3)修改pipelines.py,处理Spider的结果
这里还是将Spider的结果保存为txt格式,以便于阅读。pipelines.py文件内容如下:
1 # -*- coding: utf-8 -*-
2
3 # Define your item pipelines here
4 #
5 # Don't forget to add your pipeline to the ITEM_PIPELINES setting
6 # See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
7
8 import codecs
9
10 class GetproxyPipeline(object):
11 def process_item(self, item, spider):
12 fileName = 'proxy.txt'
13 with codecs.open(fileName, 'a', 'utf-8') as fp:
14 fp.write("{'%s': '%s://%s:%s'}||\t %s \t %s \t %s \r\n"
15 %(item['protocol'].strip(), item['protocol'].strip(),item['ip'].strip(),item['port'].strip(),item['type'].strip(),item['loction'].strip(),item['source'].strip()))
在14行中加入了两条竖线,是为了以后能方便地将代理字典({'http':'http://1.2.3.4:8080'})从字符串中分离出来。在15行中,写入文件时使用了strip()函数去除所得数据左右两边的空格。
(4)修改settings.py,决定由哪个文件来处理获取的数据
settings.py稍作修改即可。将pipelines.py添加到ITEM_PIPELINES中去就能解决问题。settings.sp文件内容如下:
1 # -*- coding: utf-8 -*-
2
3 # Scrapy settings for getProxy project
4 #
5 # For simplicity, this file contains only the most important settings by
6 # default. All the other settings are documented here:
7 #
8 # http://doc.scrapy.org/en/latest/topics/settings.html
9 #
10
11 BOT_NAME = 'getProxy'
12
13 SPIDER_MODULES = ['getProxy.spiders']
14 NEWSPIDER_MODULE = 'getProxy.spiders'
15
16 # Crawl responsibly by identifying yourself (and your website) on the User-Agent
17 #USER_AGENT = 'getProxy (+http://www.yourdomain.com)'
18
19
20 ### user add
21 ITEM_PIPELINES = {
22 'getProxy.pipelines.GetproxyPipeline':100
23 }
scrapy crawl proxy360Spider
![]()
图5 scrapy crawl proxy360Spider
得到的结果没什么问题。可花了这么长时间最后只得到了144个数据的结果,效率也太低了点吧。不过没关系,再给它一个Spider就可以了,一个站点的数据不够就再加一个站点。如果还不够,就继续增加站点吧!
按照一个Spider的思路,得到的proxy数据不够多,则可以在www.xicidaili.com中获取代理补足。到项目getProxy目录下,执行命令:
scrapy genspider xiciSpider xicidaili.com
创建一个名为xiciSpider.py的Spider文件。items.py无须修改了,直接对xiciSpider.py做修改就可以了。我们还是先用scrapy shell命令来确定如何获取数据,执行命令:
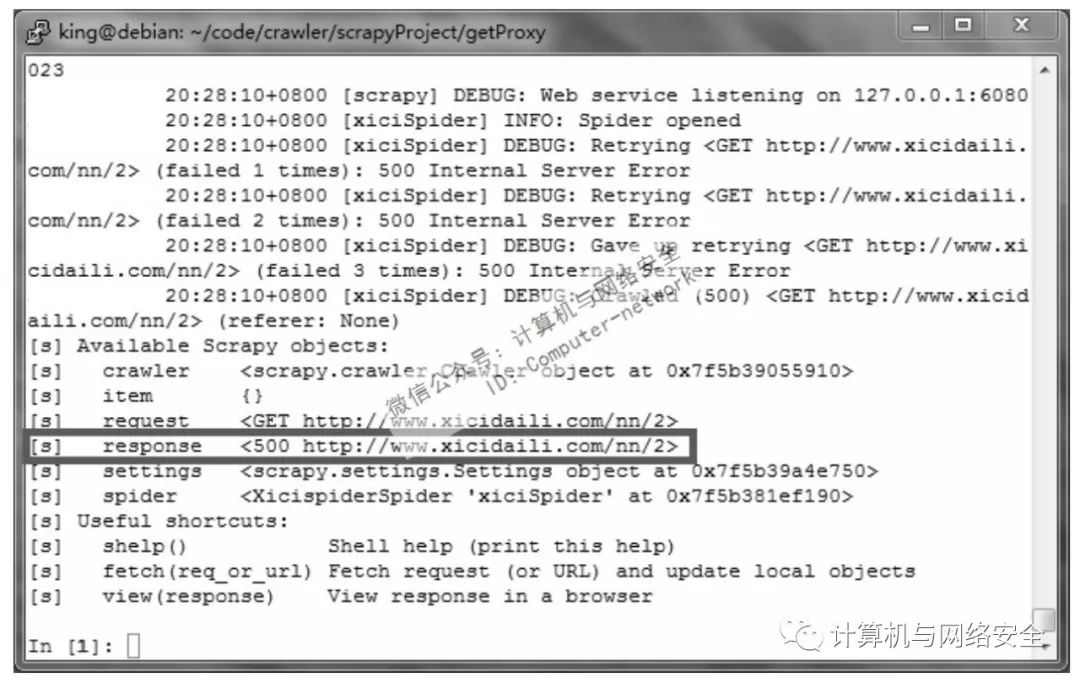
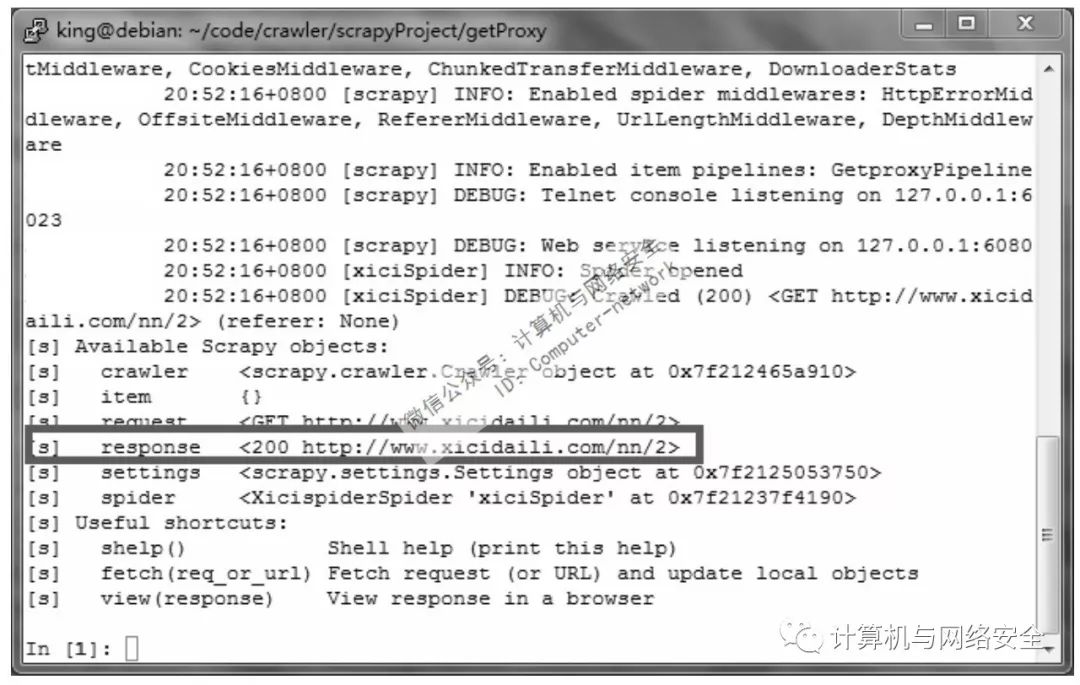
scrapy shell http://www.xicidaili.com/nn/2
![]()
图6 scrapy shell
这里发现一个问题。respnose返回的代码是500,要知道返回码是200才是正常返回。在浏览器中打开http://www.xicidaili.com/nn/2是正常显示的,而该网页并不需要登录,那就是说并不涉及cookie。用scrapy shell请求页面和用浏览器请求页面用的是同一IP。也不存在IP封锁的问题。剩下的就只有headers中User-Agent的问题了。除去所有的不可能,最后那一选项大致就是正确答案。
在Scrapy中的确是有默认的headers,但这个headers与浏览器的headers是有区别的。有的网站会检查headers,如果是正常浏览器的headers网站则予以通过,而机器人或者说爬虫的headers则拒绝访问。所以在这里只需要给scrapy一个浏览器的headers就可以解决问题了。修改settings.py文件内容如下:
1 # -*- coding: utf-8 -*-
2
3 # Scrapy settings for getProxy project
4 #
5 # For simplicity, this file contains only the most important settings by
6 # default. All the other settings are documented here:
7 #
8 # http://doc.scrapy.org/en/latest/topics/settings.html
9 #
10
11 BOT_NAME = 'getProxy'
12
13 SPIDER_MODULES = ['getProxy.spiders']
14 NEWSPIDER_MODULE = 'getProxy.spiders'
15
16 # Crawl responsibly by identifying yourself (and your website) on the User-Agent
17 #USER_AGENT = 'getProxy (+http://www.yourdomain.com)'
18
19
20 ### user add
21 USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36(KHTML, like Gecko)'
22 ITEM_PIPELINES = {
23 'getProxy.pipelines.GetproxyPipeline':100
24 }
只需要在settings.py里添加一个USER_AGENT项就可以了。如果可以,尽可能使用本机浏览器的headers。这里使用的是随意选取的一个headers,好在该网站没有根据不同的headers返回不同的内容。
再回到getProxy项目的目录下,使用scrapy shell测试如何获取有效数据。执行命令:
scrapy shell http://www.xicidaili.com/nn/2
![]()
图7 修改headers后scrapy shell
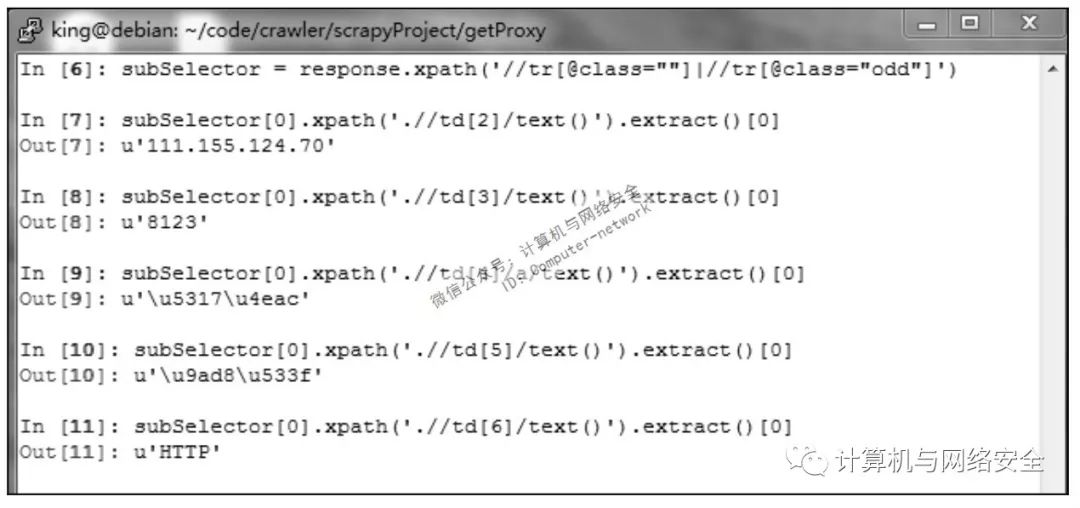
如图7所示,response的返回码为200,现在没问题了。浏览器中打开http://www.xicidaili.com/nn/2,空白处右击,选择“查看网页源代码”,打开了页面的源代码网页,发现所需数据的块都是以<tr class="odd">或者<tr class="">开头的。在scrapy shell中执行命令:
subSelector=response.xpath('//tr[@class=""]|//tr[@class="odd"]')
subSelector[0].xpath('.//td[2]/test()').extract()[0]
subSelector[0].xpath('.//td[3]/test()').extract()[0]
subSelector[0].xpath('.//td[4]/test()').extract()[0]
subSelector[0].xpath('.//td[5]/test()').extract()[0]
subSelector[0].xpath('.//td[6]/test()').extract()[0]
![]()
图8 xiciSpider测试选择器
现在xiciSpider.py怎么编写已经一目了然了。xiciSpider.py的内容如下:
![]()
![]()
图9 scrapy crawl xiciSpider
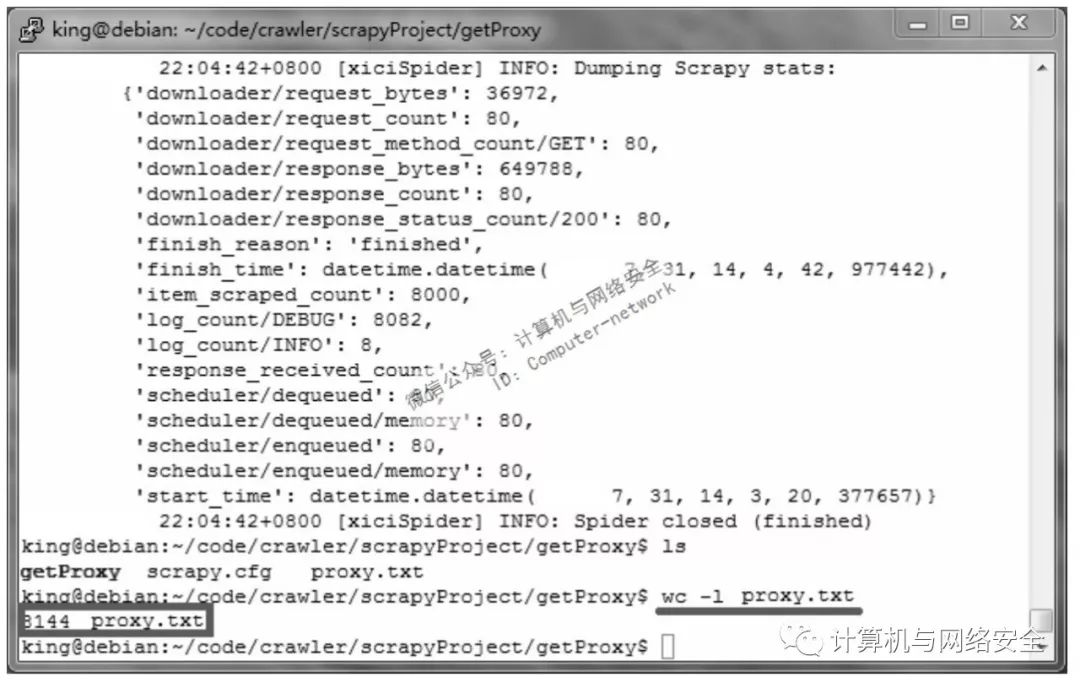
xicidaili.com同一IP,短时间内频繁爬取,超过一定次数就会被封锁IP。万一被封锁了,那就重启路由器或者光猫换个IP吧。
从文件保存的记录数字来看,应该是没问题的。但这么多的记录,或者说这么多的代理服务器有多少是可用的呢?
如何来验证上面已经获取到的代理服务器地址,最简单的方法当然是在pipelines文件里直接修改。但不幸的是验证一个代理服务器是否有效所需的时间和将一行记录写入文件的时间相差得太远了。前者所需的时间是以秒计算的,后者是以微秒计算。这样一来还不如先将所有的代理服务器保存到文件,然后另外写一个Python程序来验证代理。
进入getProxy项目的目录下,创建Python验证程序。执行命令:
代理服务器验证程序connWebWithProxy.py的内容如下:
![]()
![]()
python3 connWebWithProxy.py
利用多线程来验证来源文件proxy.txt里的代理。经过验证,有181个代理可以使用。将self.threads设置为10,使用10个进程并发,大概需要1分钟左右,速度还可以接受。这个速度已经很快了,没有必要将self.threads设置得太大,以免占用太多的系统资源。最终得到文件alive.txt。这个程序还比较简陋,有很大的改进空间。例如,同一网站下爬取的代理服务器也许不会有重复的情况,但多个网站爬取的代理服务器就有可能重复。这种情况可以在程序内加上一个去重的函数。
微信公众号:计算机与网络安全
ID:Computer-network