资源 | Pandas on Ray:仅需改动一行代码,即可让Pandas加速四倍
选自UC Berkeley Rise Lab
作者:Devin Petersohn
机器之心编译
参与:Nurhachu Null、路雪
本文中,来自 UC Berkeley 的 Devin Petersohn 发布文章介绍了其参与的项目 Pandas on Ray,使用这款工具,无需对代码进行太多改动即可加速 Pandas,遇到大型数据集也不怕。作者还对 Pandas on Ray、Pandas 进行了对比评估。机器之心对此文进行了编译介绍。
项目链接:https://github.com/ray-project/ray
最近,我和一位使用 100 多 TB 生物数据的朋友讨论了数据科学库的一些局限性。当面临这种规模的数据时,Pandas 成了最受喜爱的工具;然而,当你开始处理 TB 级别的基因数据时,单核运行的 Pandas 就会变得捉襟见肘。如果我们拥有更多的处理器核,或者要打开数十 TB 规模的文件时,我们希望 Pandas 运行得更快。目前,Apache Spark 是最高性能的分布式选择了,但是如果未对 Pandas 代码做出足够多的修改,你无法使用 Apache Spark 运行 Pandas 代码。
大规模数据科学任务向来都是丢给分布式计算专家来做的,或者至少是熟悉此类概念的人员。大多数分布式系统的设计者给用户提供了调节「旋钮」,并留下了大量的系统配置。因此,高系统性能需要用明显更加陡峭的学习曲线来折中。大多数现有用户可能只是想让 Pandas 运行得更快,并不希望在特定的硬件环境中优化他们的工作流。在我的案例中,我想在 10KB 和 10TB 的数据上使用相同的 Pandas 脚本,并且希望 Pandas 在处理这两种不同量级的数据时速度一样快(如果我有足够的硬件资源的话)。为了完成这些目标,我们开启了一个 Pandas on Ray 项目。
我们对系统进行了初步测评,Pandas on Ray 可以在一台 8 核的机器上将 Pandas 的查询速度提高了四倍,而这仅需用户在 notebooks 中修改一行代码。我们为现在的 Pandas 用户设计了该系统,旨在帮助他们的程序运行得更快,并且无需大量代码改动就能够进行更好的扩展。这项工作的最终目标就是在云环境中使用 Pandas。
简介
Pandas on Ray 是 DataFrame 库的早期阶段,DataFrame 库封装了 Pandas,并且透明地分配数据和计算。使用 Pandas on Ray,用户不需要知道他们的系统或集群有多少个核心,也不需要指定如何分配数据。事实上,在 Pandas on Ray 上体验可观的加速时,用户可以继续使用之前的 Pandas notebook,甚至是在同一台机器上。仅仅需要按照下面描述的修改 import 语句。一旦修改了 import 语句,你就可以像使用 Pandas 一样使用 Pandas on Ray 了。
Pandas on Ray 主要针对的是希望在不切换 API 的情况下提高性能和运行速度的 Pandas 用户。我们正在积极实现与 Pandas 所有 API 的对等功能,并且已经实现了 API 的一个子集。我们会介绍目前进展的一些细节,并且给出一些使用示例。
使用的数据集
标普 500 股市数据:29.6MB(https://www.kaggle.com/camnugent/sandp500/data)
导入 Pandas on Ray
# import pandas as pd
import ray.dataframe as pd
Waiting for redis server at 127.0.0.1:21844 to respond...
Waiting for redis server at 127.0.0.1:41713 to respond...
Starting local scheduler with the following resources: {'GPU': 0, 'CPU': 8}.
======================================================================
View the web UI at http://localhost:8890/notebooks/ray_ui62630.ipynb?token=bcf6d5b6cb9c2c478207f025384869100d7a25dcc27d7a56
======================================================================
Ray 将根据可用内核的数量进行自动初始化。现在你可以开始运行 Pandas 命令,它们将被并行化。
stocks_df = pd.read_csv("all_stocks_5yr.csv")
print(type(stocks_df))
我们也可以开始检查数据。让我们来看一下坐标轴。
print(stocks_df.axes)
[RangeIndex(start=0, stop=619040, step=1), Index(['date', 'open', 'high', 'low', 'close', 'volume', 'Name'], dtype='object')]
让我们运行一个简单的数据查询(just for fun),看看有多少天是以正收益结束的。
positive_stocks_df = stocks_df.query("close > open")
print(positive_stocks_df['date'].head(n=10))
print("\nNumber of positive days:", positive_stocks_df.size)
print("\nRatio of positive days to total days:", positive_stocks_df.size/stocks_df.size)
0 2013-02-13
1 2013-02-15
2 2013-02-26
3 2013-02-27
4 2013-03-01
5 2013-03-04
6 2013-03-05
7 2013-03-06
8 2013-03-07
9 2013-03-11
Name: date, dtype: object
Number of positive days: 2232790
Ratio of positive days to total days: 0.5152655724993538
我不喜欢使用默认索引,那么让我们来看一下「date」是不是一个好的索引。
print(stocks_df['date'].head(n=10))
0 2013-02-08
1 2013-02-11
2 2013-02-12
3 2013-02-13
4 2013-02-14
5 2013-02-15
6 2013-02-19
7 2013-02-20
8 2013-02-21
9 2013-02-22
Name: date, dtype: object
看上去是个正确的选择,因为我可能希望基于日期查询。让我们修改一下 DataFrame 中的索引,以便设置基于日期的查询。
stocks_df.set_index('date', inplace=True)
print(stocks_df.axes)
[Index(['2013-02-08', '2013-02-11', '2013-02-12', '2013-02-13', '2013-02-14',
'2013-02-15', '2013-02-19', '2013-02-20', '2013-02-21', '2013-02-22',
...
'2018-01-25', '2018-01-26', '2018-01-29', '2018-01-30', '2018-01-31',
'2018-02-01', '2018-02-02', '2018-02-05', '2018-02-06', '2018-02-07'],
dtype='object', name='date', length=619040), Index(['open', 'high', 'low', 'close', 'volume', 'Name'], dtype='object')]
我们可以查询数据来收集更多的信息。我们可以找到股票收益为正的日期。
这个小例子旨在演示一些 Pandas 操作,这些操作作为并行实现可在 Pandas on Ray 上找到。下面,我们会展示一些性能对比,以及我们可以利用机器上更多的资源来实现更快的运行速度,甚至是在很小的数据集上。
转置
分布式转置是 DataFrame 操作所需的更复杂的功能之一。在以后的博客中,我们将讨论我们的实现和一些优化。目前,转置功能相对粗糙,也不是特别快,但是我们可以实现一些简单优化来获得更好的性能。
print(stocks_df.T[:])
date 2013-02-08 2013-02-11 2013-02-12 2013-02-13 2013-02-14 2013-02-15 \
open 15.07 14.89 14.45 14.3 14.94 13.93
high 15.12 15.01 14.51 14.94 14.96 14.61
low 14.63 14.26 14.1 14.25 13.16 13.93
close 14.75 14.46 14.27 14.66 13.99 14.5
volume 8407500 8882000 8126000 10259500 31879900 15628000
Name AAL AAL AAL AAL AAL AAL
date 2013-02-19 2013-02-20 2013-02-21 2013-02-22 ... 2018-01-25 \
open 14.33 14.17 13.62 13.57 ... 78.47
high 14.56 14.26 13.95 13.6 ... 79.38
low 14.08 13.15 12.9 13.21 ... 78.345
close 14.26 13.33 13.37 13.57 ... 79.25
volume 11354400 14725200 11922100 6071400 ... 2327262
Name AAL AAL AAL AAL ... ZTS
date 2018-01-26 2018-01-29 2018-01-30 2018-01-31 2018-02-01 2018-02-02 \
open 79.49 79.81 78.44 78.49 76.84 77.53
high 80.13 79.95 78.69 78.77 78.27 78.12
low 79.38 79.11 77.91 76.54 76.69 76.73
close 80.09 79.18 78.35 76.73 77.82 76.78
volume 2532808 2662383 3808707 4136360 2982259 2595187
Name ZTS ZTS ZTS ZTS ZTS ZTS
date 2018-02-05 2018-02-06 2018-02-07
open 76.64 72.74 72.7
high 76.92 74.56 75
low 73.18 72.13 72.69
close 73.83 73.27 73.86
volume 2962031 4924323 4534912
Name ZTS ZTS ZTS
[6 rows x 619040 columns]
基准测试
接下来,我们要比较一下 Pandas 和 Ray on Pandas。尽管我们目前还没有支持完整的 Pandas 功能 API,但是我们展示了一些初步的基准测试,证明我们的方法是有潜力的。我们会在以下对比中做到尽可能的公平。需要注意的是,我们没有在 Pandas on Ray 上做任何特殊的优化,一切都使用默认设置。还需要注意的是,Ray 使用了 eager execution,因此我们无法进行任何查询规划,也无法掌握计算给定工作流的最佳方法。
所用的数据集
全球健康数据:1.79GB(https://www.kaggle.com/census/international-data/data)
# we are importing Pandas to benchmark against it
import pandas as old_pd
首先我们要检查加载一个 CSV 文件所需的时间。这个文件相对较大(1.7GB),所以使用 Pandas 和使用 Pandas on Ray 的加载时间会有所不同。
# Pandas on Ray
print("Pandas on Ray:")
%time pandas_on_ray = pd.read_csv("midyear_population_age_country_code.csv")
# Pandas
print("\nPandas:")
%time pandas_native = old_pd.read_csv("midyear_population_age_country_code.csv")
Pandas on Ray:
CPU times: user 48.5 ms, sys: 19.1 ms, total: 67.6 ms
Wall time: 68 ms
Pandas:
CPU times: user 49.3 s, sys: 4.09 s, total: 53.4 s
Wall time: 54.3 s
我们看到的结果是:Pandas on Ray 的加载速度大约是 Pandas 的 675 倍。尽管这些数字令人印象深刻,但是 Pandas on Ray 的很多实现将工作从主线程转移到更异步的线程。文件是并行读取的,运行时间的很多改进可以通过异步构建 DataFrame 组件来解释。让我们将所有线程的结果汇总到一起,看看它需要多长时间。
# Pandas on Ray
print("Pandas on Ray:")
%time entire_df = pandas_on_ray[:]
# Pandas
print("\nPandas:")
%time entire_df = pandas_native[:]
Pandas on Ray:
CPU times: user 2.59 s, sys: 2.52 s, total: 5.11 s
Wall time: 9.09 s
Pandas:
CPU times: user 16 ms, sys: 240 ms, total: 257 ms
Wall time: 256 ms
这里我们可以看到,如果我们使用 [:] 运算符将所有的数据收集到一起,Pandas on Ray 速度大约是之前的 1/36。这是因为并行化。所有的线程以并行的方式读取文件,然后将读取结果串行化。主线程又对这些值进行去串行化,这样它们又变得可用了,所以(去)串行化就是我们在这里看到的主要开销。熟悉 Spark 的人可能会记得,这类似于一个.collect() 调用。它使任务不再并行执行,将它们转移动单独的线程中。所以,尽管它读取文件更快,但是将这些片段重新组合在一起的开销意味着 Pandas on Ray 应该不仅仅被用于文件读取。让我们看一下文件加载完成后索引会发生什么。
# Pandas on Ray
print("Pandas on Ray:")
%time pandas_on_ray.index
print("\nPandas:")
# Pandas
%time pandas_native.index
Pandas on Ray:
CPU times: user 12 µs, sys: 1 µs, total: 13 µs
Wall time: 16 µs
Pandas:
CPU times: user 4 µs, sys: 0 ns, total: 4 µs
Wall time: 7.15 µs
RangeIndex(start=0, stop=3058280, step=1)
请注意,两种方法都在缓存.index 调用的结果,所以我们调用一次 .index 之后看到的是原始时间,再一次调用的时候看到的是缓存访问时间。Pandas on Ray 大约慢了 10 µs,但是维持一个分布式索引的复杂度更高。这显示了底层 Ray 基础架构的效率,它能够快速检索数据。
现在让我们尝试加速一次示例查询,看看 Pandas 和 Pandas on Ray 的性能对比。
# Pandas on Ray
print("Pandas on Ray:")
%timeit q0 = pandas_on_ray.query('max_age > 100')
# Pandas
print("\nPandas:")
%timeit q1 = pandas_native.query('max_age > 100')
Pandas on Ray:
100 loops, best of 3: 4.14 ms per loop
Pandas:
The slowest run took 32.21 times longer than the fastest. This could mean that an intermediate result is being cached.
1 loop, best of 3: 17.3 ms per loop
在这次 timeit 调用中,我们看到 Pandas on Ray 的速度大约是 Pandas 的 4 倍。这是在一台 8 核的机器上运行的,由于开销的因素,加速并不是特别完美。尽管如此,通过仅仅修改 import 语句,原始 Pandas 上的运行时间和 Pandas on Ray 上的运行时间还是有显著差别的。
在 Dask 上进行实验
DataFrame 库 Dask 提供可在其并行处理框架上运行的分布式 DataFrame,Dask 还实现了 Pandas API 的一个子集。一般来说,目前 Dask 在绝大多数操作上都比 Pandas on Ray 快一些。Dask 为 Pandas 用户提供精细调整的定制,而 Pandas on Ray 则提供一种以最少的工作量实现更快性能的方法,且不需要多少分布式计算的专业知识。Pandas on Ray 针对的不是目前的 Dask(或 Spark)用户,而是希望在无需学习新 API 的情况下提升现有和未来工作负载的性能和可扩展性的 Pandas 用户。在 columnar operation 上,Dask 比 Pandas on Ray 快,但是它需要一些超出传统 Pandas 之外的知识。
Dask 中存在两个主要的差别,而 Pandas on Ray 则尝试解决这两个差别:
1. 用户需要一直意识到:数据是分布式的,计算是懒惰的。
2. 多线程和多进程之间的权衡是可扩展性和性能之间的权衡。
数据科学家应该用 DataFrame 来思考,而不是动态的任务图
Dask 用户一直这样问自己:
我什么时候应该通过 .compute() 触发计算,我什么时候应该调用一种方法来创建动态任务图?
我什么时候应该调用 .persist() 将 DataFrame 保存在内存中?
这个调用在 Dask 的分布式数据帧中是不是有效的?
我什么时候应该重新分割数据帧?
这个调用返回的是 Dask 数据帧还是 Pandas 数据帧?
使用 Pandas 的数据科学家不一定非得是分布式计算专家,才能对数据进行高效分析。Dask 要求用户不断了解为计算而构建的动态任务图。此外,默认情况下,懒惰计算使每个熟悉的 Pandas 调用返回一个意外的结果。这些差异为 Dask 提供了更好的性能配置,但对于某些用户来说,学习新 API 的开销太高。
使用 Pandas on Ray 的时候,用户看到的数据帧就像他们在看 Pandas 数据帧一样。
我们要速度,也要扩展性
Dask 默认是以多线程的模式运行的,这意味着一个 Dask 数据帧的所有分割部分都在一个单独的 Python 进程中。尽管多线程模式让一些计算变得更快,但是一个单独的 Python 进程并不能利用机器的多个核心。
或者,Dask 数据帧可以以多进程模式运行,这种模式能够生成多个 Python 进程。然而,如果一个 Python 进程需要将一个小的 Pandas 数据帧发送到另一个进程,则该数据帧必须通过 Pickle 进行串行化处理,然后在另一个进程中进行去串行化处理,因为这两个进程没有共享内存。串行化、拷贝以及去串行化,这三步会带来高性能损失。即使这个解决方案可以扩展到多个核心,但是高昂的通信成本会对整体性能造成影响。
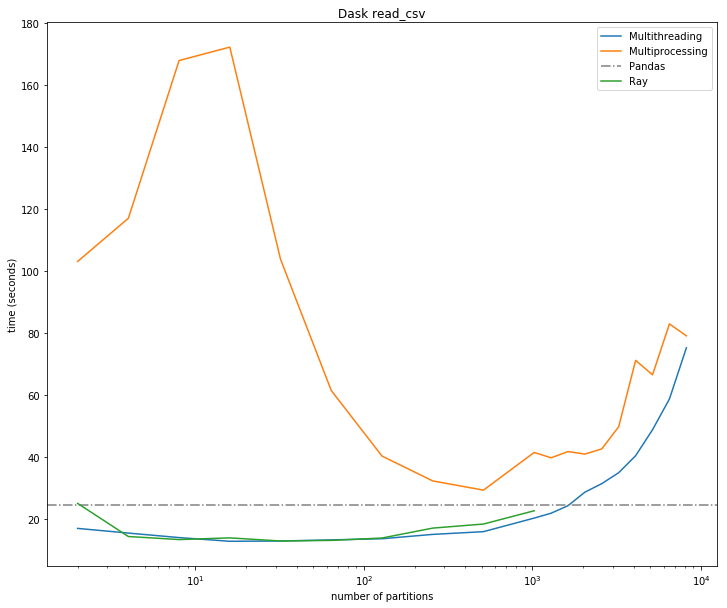
如上图所示,由于串行化和拷贝操作,Dask 的多进程模式损伤了 read_csv 操作的性能。
Pandas on Ray 既可以以多线程模式运行,也可以以多进程模式运行。Ray 的默认模式是多进程,因此它可以从一台本地机器的多个核心扩展到一个机器集群上。至于通信方面,Ray 使用共享内存,并且通过 Apache Arrow 实现零拷贝串行化,显著降低了进程之间的通信代价。
使用 Pandas on Ray,你的 Pandas 工作流可以同时实现快速运行和可扩展性。
read_csv 案例研究
在 AWS m5.2x 大型实例(8 个虚拟核、32GB 内存)上,我们使用 Pandas、Ray 和 Dask(多线程模式)进行了 read_csv 实验。
我们采用了从 60KB 到 2GB 大小不等的四个数据集:
泰坦尼克数据集:60KB(https://www.kaggle.com/c/titanic/data)
Yelp 数据集:31MB(https://www.kaggle.com/c/titanic/data)
Kiva Loan 数据集:187MB(https://www.kaggle.com/kiva/data-science-for-good-kiva-crowdfunding/data)
NYC Parking Tickets 数据集:2GB(https://www.kaggle.com/new-york-city/nyc-parking-tickets/data)
结果显示 Ray 的性能是快速且可扩展的,在多个数据集上都优于 Dask。

注:第一个图表明,在像泰坦尼克数据集这样的小数据集上,分发数据会损害性能,因为并行化的开销很大。
MAX 案例研究
为了查看逐行操作和逐列操作时三者的对比结果,我们继续在相同的环境中进行实验。

除了在最小的文件上 Pandas 是最快的以外,Pandas on Ray 的逐行操作速度大约是 Pandas 和 Dask 的三倍。在逐列操作上,它大约慢了 2.5 倍,这是因为目前的 Pandas on Ray 实现尚未针对 columnar operation 进行优化。值得注意的是,Dask 的惰性计算和查询执行规划不能在单个操作中使用。
通常情况下,Pandas on Ray 是异步运行的,但是出于实验目的,我们强制执行同步,以便对 Pandas 和 Dask 进行正确的评估。
结论
我们已经开始构建 Pandas on Ray,这是一个仅更改 import 语句就可以使 Pandas 工作流并行化的库。到今天为止,我们已经在大约 45 天内实现了 Pandas DataFrame API 的 25%。目前,我们仅在单个节点上加速 Pandas,但很快我们将具备在集群环境中运行 Pandas 的功能。
如果您想试用 Pandas on Ray,请按照 readthedocs 文档说明(http://ray.readthedocs.io/)从源代码开始构建。此处使用的代码目前位于 Ray 的主分支上,但尚未将其转换为发布版本。

原文链接:https://rise.cs.berkeley.edu/blog/pandas-on-ray/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


