训练提速60%!只需5行代码,PyTorch 1.6即将原生支持自动混合精度训练
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
PyTorch 1.6 nightly增加了一个子模块 amp ,支持自动混合精度训练。值得期待。来看看性能如何,相比Nvidia Apex 有哪些优势?
A developer-friendly guide to mixed precision training with PyTorch
https://spell.run/blog/mixed-precision-training-with-pytorch-Xuk7YBEAACAASJam
即将在 PyTorch 1.6上发布的 torch.cuda.amp 混合精度训练模块实现了它的承诺,只需增加几行新代码就可以提高大型模型训练50-60% 的速度。
预计将在 PyTorch 1.6中推出的最令人兴奋的附加功能之一是对自动混合精度训练(automatic mixed-precision training)的支持。
混合精度训练是一种通过在半精度浮点数 fp16上执行尽可能多的操作来大幅度减少神经网络训练时间的技术,fp16 取代了PyTorch默认的单精度浮点数 fp32。最新一代 NVIDIA GPU 搭载了专门为快速 fp16矩阵运算设计的特殊用途张量核(tensor cores)。
然而,到目前为止,这些张量核仍然很难用,因为它需要手动将精度降低的操作写入模型中。这就是自动化混合精度训练的用武之地。即将发布的 torc h.cuda.amp API 将允许你只用五行代码就可以在训练脚本中实现混合精度训练!
这篇文章是对开发者友好的混合精度训练的介绍。我们将:
-
深入研究混合精度训练技术 -
介绍张量核: 它们是什么以及是如何工作的 -
介绍新的 PyTorch amp API -
Benchmark用amp训练的三个不同的网络 -
讨论哪些网络原型从amp中受益最多
混合精度是如何工作的
在我们理解混合精度训练是如何工作的之前,首先需要回顾一下浮点数。
在计算机工程中,像1.0151或566132.8这样的十进制数传统上被表示为浮点数。由于我们可以有无限精确的数字(想象一下π) ,但存储它们的空间是有限的,我们必须在精确度(在舍入数字前,我们可以在数字中包含的小数的数量)和大小(我们用来存储数字的位数)之间做出妥协。
浮点数的技术标准 IEEE 754(想要更深入理解,我推荐 PyCon 2019演讲"Floats are Friends: making the most of IEEE754.00000000000000002") 设定了以下标准:
-
fp64, 又名双精度或"double" ,最大舍入误差 ~ 2^-52 -
fp32, 又名单精度或"single",最大舍入误差 ~ 2 ^-23 -
fp16, 又名半精度或"half" ,最大舍入误差 ~ 2 ^-10
Python float 类型为 fp64,而对内存更敏感的PyTorch 使用 fp32作为默认的 dtype。
混合精度训练的基本思想很简单: 精度减半(fp32→ fp16) ,训练时间减半。
最困难的是如何安全地做到这一点。
注意,浮点数越小,引起的舍入误差就越大。对“足够小“的浮点数执行的任何操作都会将该值四舍五入到零!这就是所谓的underflowing,这是一个问题,因为在反向传播中很多甚至大多数梯度更新值都非常小,但不为零。在反向传播中舍入误差累积可以把这些数字变成0或者 nans; 这会导致不准确的梯度更新,影响你的网络收敛。
2018年ICLR论文 Mixed Precision Training 发现,简单的在每个地方使用 fp16 会“吞掉”梯度更新小于2^-24的值——大约占他们的示例网络所有梯度更新的5% :
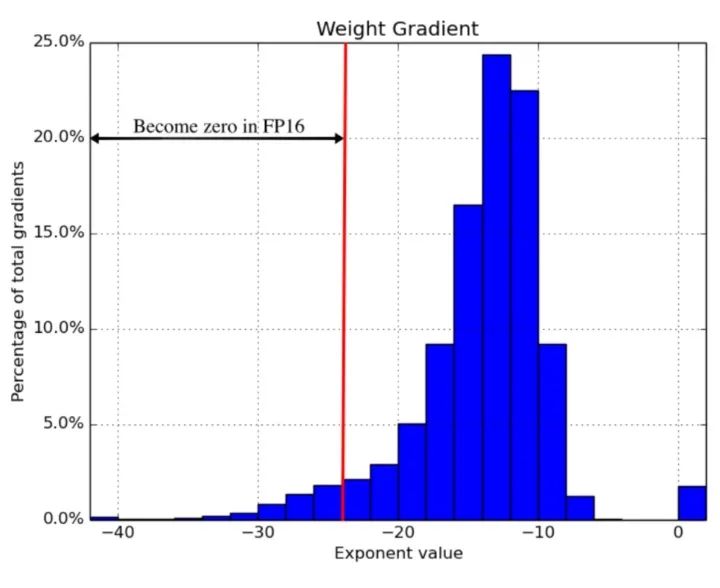
混合精度训练是一套技术,它允许你使用 fp16,而不会导致你的模型训练发生发散。这是三种不同技术的结合。
第一,维护两个权重矩阵的副本,一个“主副本”用 fp32,一个半精度副本用 fp16。梯度更新使用 fp16矩阵计算,但更新于 fp32矩阵。这使得应用梯度更新更加安全。
第二,不同的向量操作以不同的速度累积误差,因此要区别对待它们。有些操作在 fp16中总是安全的,而其它操作只在 fp32中是可靠的。与其用 fp16跑整个神经网络,不如一些用半精度另外的用单精度。这种 dtypes 的混合就是为什么这种技术被称为“混合精度”。
第三,使用损失缩放。损失缩放是指在执行反向传播之前,将损失函数的输出乘以某个标量数(论文建议从8开始)。乘性增加的损失值产生乘性增加的梯度更新值,“提升”许多梯度更新值到超过fp16的安全阈值2^-24。只要确保在应用梯度更新之前撤消缩放,并且不要选择一个太大的缩放以至于产生 inf 权重更新(overflowing) ,从而导致网络向相反的方向发散。
将这三种技术结合在一起,作者可以在显著加速的时间内训练好多种网络以达到收敛。至于benchmarks,我建议读一读这篇只有9页的论文!
张量核(tensor cores)是如何工作的
虽然混合精度训练节省内存(fp16矩阵只有 fp32矩阵的一半大小) ,但如果没有特殊的 GPU 支持,它并不能加速模型训练。芯片上需要有可以加速半精度操作的东西。在最近几代 NVIDIA GPU中这东西叫: 张量核。
张量核是一种新型的处理单元,针对一个非常特殊的操作进行了优化: 将两个4 × 4 fp16矩阵相乘,然后将结果加到第三个4 × 4 fp16或 fp32矩阵(一个“融合乘法加(fused multiply add)”)中。
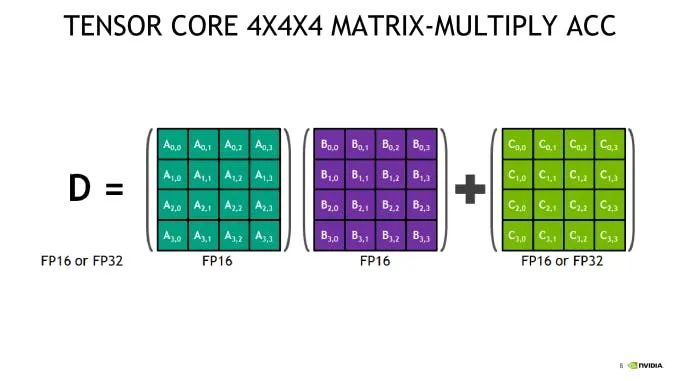
更大的 fp16 矩阵乘法操作可以使用这个操作作为他们的基本构件来实现。由于大多数反向传播都可以归结为矩阵乘法,张量核适用于网络中几乎任何计算密集层。
陷阱: 输入矩阵必须是 fp16。如果你正在使用带有张量核的 GPU 进行训练,而没有使用混合精度训练,你不可能从你的显卡中得到100% 的回报! 在 fp32中定义的标准 PyTorch 模型永远不会将任何 fp16数学运算应用到芯片上,因此所有这些极其强悍的张量核都将处于空闲状态。
张量核在2017年末在上一代Volta体系结构中被引入,当代Turing有了一些改进,并将在即将推出的Ampere中看到进一步的改进。云上通常可用的两款GPU 是 V100(5120个 CUDA 核,600个张量核)和 T4(2560个 CUDA 核,320个张量核)。
另一个值得记住的难题是firmware。尽管 CUDA 7.0或更高版本都支持张量核操作,但早期的实现据说有很多 bug,所以使用 CUDA 10.0或更高版本很重要。
Pytorch 自动混合精度是如何工作的
有了这些重要的背景知识,我们终于可以开始深入研究新的 PyTorch amp API 了。
混合精度训练在技术上已经永远成为可能: 手动运行部分网络在 fp16中,并自己实现损失缩放。自动混合精度训练中令人兴奋的是“自动”部分。只需要学习几个新的 API 基本类型: torch.cuda.amp.GradScalar 和 torch.cuda.amp.autocast。启用混合精度训练就像在你的训练脚本中插入正确的位置一样简单!
为了演示,下面是使用混合精度训练的网络训练循环的一段代码。# NEW标记定位了增加了新代码的地方。
self.train()X = torch.tensor(X, dtype=torch.float32)y = torch.tensor(y, dtype=torch.float32)
optimizer = torch.optim.Adam(self.parameters(), lr=self.max_lr)scheduler = torch.optim.lr_scheduler.OneCycleLR( self.max_lr, cycle_momentum=False, epochs=self.n_epochs, steps_per_epoch=int(np.ceil(len(X) / self.batch_size)),)batches = torch.utils.data.DataLoader( y), batch_size=self.batch_size, shuffle=True)
# NEWscaler = torch.cuda.amp.GradScaler()
for epoch in range(self.n_epochs): for i, (X_batch, y_batch) in enumerate(batches): X_batch = X_batch.cuda() y_batch = y_batch.cuda() optimizer.zero_grad()
# NEW with torch.cuda.amp.autocast(): y_pred = model(X_batch).squeeze() loss = self.loss_fn(y_pred, y_batch)
# NEW scaler.scale(loss).backward() lv = loss.detach().cpu().numpy() if i % 100 == 0: {epoch + 1}/{self.n_epochs}; Batch {i}; Loss {lv}")
# NEW scaler.step(optimizer) scaler.update() scheduler.step()
新的 PyTorch GradScaler 对象是 PyTorch 实现的_损失缩放_。回想一下在“混合精度如何工作”一节中提到,在训练期间,为了防止梯度变小到0,某种形式的缩放是必要的。最佳的损失乘数得足够高以保留非常小的梯度,同时不能太高以至于导致非常大的梯度四舍五入到 inf产生相反的问题。
然而,没有一个损失乘数适用于每个网络。最佳乘数也很可能随着时间的推移而改变,因为通常在训练开始时的梯度要比训练结束时大得多。如何在不给用户另一个需要调整的超参数的情况下找到最佳的损失乘数?
PyTorch使用指数退避(exponential backoff)来解决这个问题。Gradscalar 以一个小的损失乘数开始,这个乘数每次会翻倍。这种逐渐加倍的行为一直持续到 GradScalar 遇到包含 inf 值的梯度更新。Gradscalar 丢弃这批数据(例如跳过梯度更新) ,将损失乘数减半,并重置其倍增时间。
通过这种方式逐级上下移动损失乘数,PyTorch 可以随着时间的推移近似得到合适的损失乘数。熟悉 TCP 拥塞控制的读者应该会发现这里的核心思想非常熟悉!该算法使用的准确数字是可配置的,你可以直接从docstring中看到默认值:
torch.cuda.amp.GradScaler(init_scale=65536.0, growth_factor=2.0, backoff_factor=0.5,growth_interval=2000, enabled=True)
Gradscalar 需要对梯度更新计算(检查是否溢出)和优化器(将丢弃的batches转换为 no-op)进行控制,以实现其操作。这就是为什么 loss.backwards()被 scaler.scale(loss).backwards()取代, 以及 optimizer.step()被 scaler.step(optimizer)替换的原因。
值得注意的是,GradScalar 可以检测并停止overflows(因为 inf 总是坏的) ,但是它无法检测和停止underflows(因为0通常是一个合法值)。如果你选择的初始值太低,增长间隔太长,你的网络可能会在 GradScalar 介入之前underflow并发散。由于这个原因,选择一个非常大的初始值可能是一个好主意,init _ scale = 65536( ) 是 PyTorch 的默认值。
最后,注意 GradScalar 是一个有状态对象。使用此功能保存模型checkpoint需要和模型权重一起写入和读取磁盘。用 state _ dict 和 load _ state _ dict 对象方法(在 PyTorch 文档中有介绍)可以很容易地做到这一点。
自动混合精度训练拼图的另一半是 torch.cuda.amp.autocast 上下文管理器。Autocast实现了 fp32-> fp16转换。回想一下“混合精度是如何工作的“中的内容,由于不同的操作以不同的速率累积误差,并非所有的操作都可以在 fp16中安全运行。下面的截图来自 amp 模块文档,介绍了autocast如何处理 PyTorch 中可用的各种操作:

这个列表主要由矩阵乘法和卷积两部分组成,还有简单的线性函数。

这些操作在 fp16中是安全的,但是在输入有 fp16和 fp32混合的情况下,这些操作具有向上适配(up-casting)规则,以确保它们不会出问题。注意,这个列表还包括另外两个基本的线性代数运算: 矩阵/向量点积和向量叉积。

对数、指数、三角函数、正规函数、离散函数和(大)和在 fp16中是不安全的,必须在 fp32中执行。
通过浏览这个列表,在我看来,大多数层都会从autocasting中受益,这要归功于它们内部对基本线性代数操作的依赖,但大多数激活函数却不是。卷积层是最大赢家。
启用sutocasting非常简单。你只需要做的就是使用autocast上下文管理器包好模型的正向传播:
with torch.cuda.amp.autocast():y_pred = model(X_batch).squeeze()= self.loss_fn(y_pred, y_batch)
以这种方式包装前向传播,可以自动打开后传(如 loss.backwards ())的autocasting,因此不需要调用两次autocast。
只要你遵循PyTorch 的最佳实践(例如,避免in-place操作) ,autocasting基本上就可以“正常工作”。它甚至可以使用多GPU DistributedDataParallel API (只要遵循建议的策略,每个 GPU 只使用一个进程)。只需一个小调整,多GPU DataParallel API也可以用。Pytorch 文档中的 Automatic Mixed Precision Examples 页面的“Working with multiple GPUs”部分是关于这个主题的一个方便的参考。个人观点,有一个要记住的重点是: "优先用 binary cross entropy with logits 而不是 binary cross entropy"。
Benchmarks性能
此时,我们已经了解了什么是混合精度,什么是张量核,以及 PyTorch API 如何实现自动混合精度。唯一剩下的就是看看一些真实世界的性能benchmarks!
我曾经用自动混合精度训练过三个非常不一样的神经网络,还有一次没用,通过 Spell API 调用 V100s (上一代张量核)和 T4s (当代张量核)。我分别使用了 AWS EC2实例、 p3.2xlarge 和 g4dn.xlarge,最近的 PyTorch 1.6 nightly 和 CUDA 10.0。所有模型的收敛都是一致的,即没有一个模型发现混合精度网络和原网络在训练损失上有任何差异。训练的网络如下:
-
前馈, 一个前馈神经网络,训练数据来自Kaggle比赛Rossman Store Samples。点击获取代码 -
UNet, 一个中等大小的原版UNet 图像分割网络, 在数据集Segmented Bob Ross Images 上训练。点击获取代码. -
BERT, 一个大的 NLP transformer 模型,使用bert-base-uncased 骨干(通过 huggingface),及数据来自Kaggle竞赛 Twitter Sentiment Extraction 。点击获取代码.
结果如下:
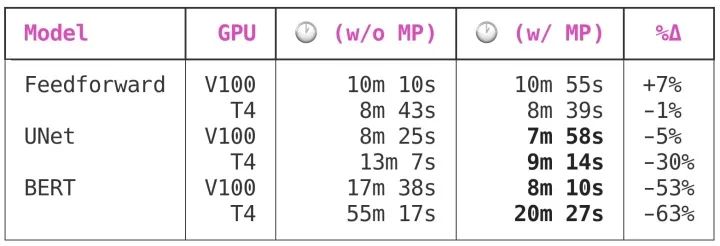
由于前馈网络非常小,混合精度训练对它没有任何好处。
UNet 是一个中等规模的卷积模型,共有7,703,497个参数,从混合精度训练中得到了显著的好处。有趣的是,虽然 V100和 T4都受益于混合精度训练,但 T4的好处要大得多: 节省5%时间vs. 高达30%的时间。
BERT 是一个很大的模型,在这里使用混合精度训练节省时间,从中等模型的“很好”到了“必须拥有”。在Volta或Turing GPU 上训练,自动混合精度将为大型模型减少50% 到60% 的训练时间!
这是一个巨大的优势,尤其是当你考虑到增加的复杂性极小时——只需要对模型训练脚本进行四到五行代码修改。在我看来:
混合精度应该是你对模型训练脚本进行的最先性能优化之一。
内存呢?
正如我在“混合精度是如何工作的”一节中解释的那样,在内存中fp16矩阵的大小是fp32矩阵的一半,因此,混合精度训练的另一个据称的优势是内存使用率。GPU 内存的瓶颈远小于 GPU 的计算能力,但仍有很大的优化价值。你的内存使用效率越高,你可以在 GPU 上使用的batch size就越大。
PyTorch 在模型训练过程开始时保留一定数量的 GPU 内存,并在训练期间保留这些内存。这可以防止其它进程在训练过程中抢占过多的 GPU 内存,迫使 PyTorch 训练脚本崩溃并出现 OOM 错误。
以下是启用混合精度训练对 PyTorch 内存保留行为的影响:
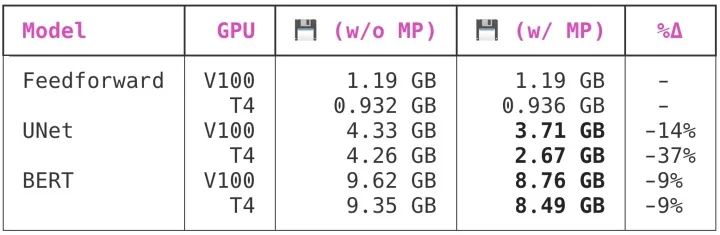
有趣的是,虽然两个较大的模型都看到了切换到混合精度的好处,UNet 从切换中得到的好处比 BERT 多得多。PyTorch 内存分配行为对我来说非常不透明,所以我不知道为什么会出现这种情况。
总结
在即将发布的 PyTorch 1.6版本中,自动混合精度训练是一个易于使用且功能强大的新特性,该版本承诺将在最新的 NVIDIA GPU 上运行的大型模型训练工作加快60% 。
虽然这种技术已经存在了一段时间,但是对于普通用户来说还不是很容易理解,因为直到现在它还没有一个原生 PyTorch API。
要直接从源代码中了解更多关于混合精度训练的信息,请参阅 PyTorch master 文档中的automatic mixed precision package和automatic mixed precision examples页面。
想自己测试一下这个功能?安装最新的 PyTorch nightly非常简单: 查看 PyTorch 主页上的说明了解如何安装。
想要自己复现这些benchmarks吗?所有模型源代码都可以在 GitHub 上的 ResidentMario/spell-feedforward-rossman, ResidentMario/spell-unet-bob-ross, 和 ResidentMario/spell-tweet-sentiment-extraction 库中获得。
推荐阅读

添加极市小助手微信(ID : cv-mart),备注:研究方向-姓名-学校/公司-城市(如:目标检测-小极-北大-深圳),即可申请加入极市技术交流群,更有每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、行业技术交流,一起来让思想之光照的更远吧~

△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~




