Flink on PaaSTA:Yelp运行在Kubernetes上的新流处理平台

本文最初发布于 yelp 工程博客,由 InfoQ 中文站翻译并分享。
在 Yelp,我们每天使用 Apache Flink 处理 TB 级的流数据,为各种各样的应用提供支持:ETL 管道、推送通知、机器人过滤、Session 化等等。我们运行成百上千的 Flink 作业,因此,如果没有适当程度的自动化,像部署、重启和保存点这样的常规操作会花费开发人员数千小时的时间。最近,我们的工具室中增加了一个新的流处理平台,它基于 Yelp 的 PaaS 服务 PaaSTA。其核心是一个 KubernetesOperator,它自动监视我们的 Flink 集群的 fleet 部署和生命周期。

Flink on PaaSTA on Kubernetes
在 Yelp 引入 Kubernetes 之前,Yelp 的 Flink 工作负载运行在专用的 AWSElasticMapReduce 集群上,这些集群预装了 Flink 和 YARN。为了实现 EMR 实例与 Yelp 生态系统其余部分的良好协同,我们之前的流处理平台 Cascade 在一个 Docker 容器中运行大量的 Puppet 单体,以应用配置并启动一组常见的守护进程(在 Yelp 几乎所有的主机上运行)。
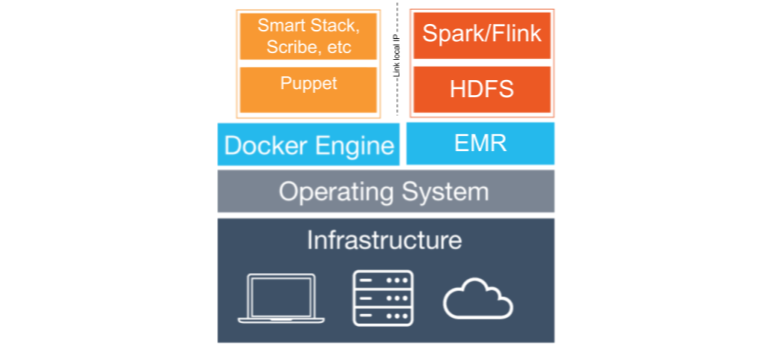
Cascade 的架构
Cascade 还针对每个集群引入了一个控制器组件,负责 Flink 作业生命周期(启动、停止、设置保存点)和监控,我们称之为 Flink Supervisor。
虽然这个系统为我们服务了很多年,但我们的开发人员受到了不少限制:
-
之前需要大约 30 分钟才能启动一个新的 Flink 集群; -
我们需要训练有素的操作人员手动部署新版本或扩大每个集群的资源; -
我们无法升级到更新版本的 Flink,除非 AWS 支持这些版本; -
在 Docker 中运行 Puppet 以及维护一个与 Yelp 其他部分完全不同的基础设施,复杂而耗时。
当 Kubernetes 在公司内外的发展势头越来越猛时,我们确信,是时候做出改变了。
PaaSTA 是 Yelp 的平台即服务,运行 Yelp 的所有 Web 服务和其他一些无状态的工作负载,比如批处理作业。它最初是在 Apache Mesos 上开发的,现在我们正在将其迁移到 Kubernetes。得益于 Kubernetes 的强大功能,这为我们支持更复杂的工作负载提供了机会。Flink 是第一个,Cassandra 支持也很快就会到来(请关注新博文!),对于这两者,相关开发工作都是在与计算基础设施团队的紧密合作下开展的。
为了在 Kubernetes 上运行 Flink,我们没有使用现成的东西,而是开发了一个完善的平台,使运行 Flink 工作负载的体验尽可能类似于运行 Yelp 的任何其他服务。我们这样做是为了极大地减少用户操作 Flink 集群所需的知识,并使我们的基础设施与 Yelp 生态系统的其他部分保持同构。
借助 Flink on PaaSTA,配置集群就像编写一个 YAML 配置文件一样简单。只要通过 Jenkins 提交给 Git,新的代码就会自动进行部署。PaaSTA 提供的启动、停止、日志读取或 Web 服务监视命令对于任何 Flink 集群都完全相同。
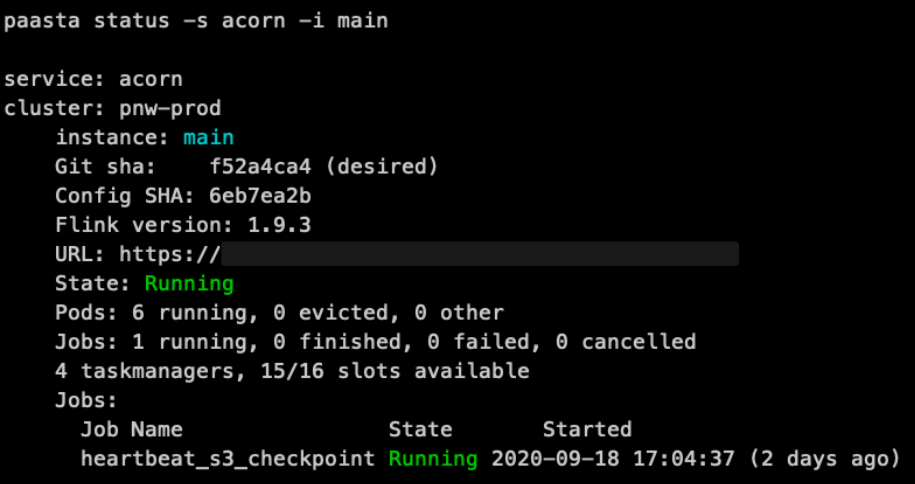
paasta status 命令的输出
除了用户体验方面的改进,我们还成功地将 Flink 集群的平均启动时间从 30 分钟减少到 2 分钟以内,而且,我们现在可以按照自己的时间表自由地跳转到 Flink 的最新版本。
Flink on PaaSTA 的核心是我们自定义的 KubernetesOperator,它监视在 Kubernetes 上运行的 Flink 集群的状态,并确保它们始终与用户定义的配置相匹配。
我们的 PaaSTA 将该配置转换为 Kubernetes 自定义资源,Operator 读取这些资源并使用从 Flink 集群获取的信息(如作业列表和状态)更新它们。PaaSTA 命令也使用这些资源来获取要向用户显示的内容,并与 Operator 进行交互,以完成启动、停止等操作。
Operator 知道如何将 Flink 集群资源的高级定义映射到正确的 Kubernetes 原语中,比如 Deployment 调度 TaskManagers,Service 让集群中的其他组件可以发现 JobManager,或 Ingress 让用户可以访问 Flink Web 仪表板。Operator 和 Jenkins 将这些组件安排在 Docker 容器中,这让我们可以自定义 Flink 安装,并为每个应用程序选择合适的 Flink 版本。
在下图中,你可能会惊讶地发现,我们的遗留组件 Supervisor 在我们的新平台中仍然占有一席之地。在 Yelp,我们在处理我们的所有项目时都秉承实用的精神,包括基础设施迁移。虽然 Supervisor 所做的一切都可以由 Operator 完成,但我们决定保留它,通过重用现有功能来减少开发时间。更重要的是,最小化更改范围还有助于尽可能简化现有用户从 Cascade 到 PaaSTA 的迁移。
例如,我们将 Supervisor 部署为一个 Kubernetes 作业,以便在 Operator 关闭集群之前利用它的逻辑触发集群上运行的所有 Flink 作业的保存点。
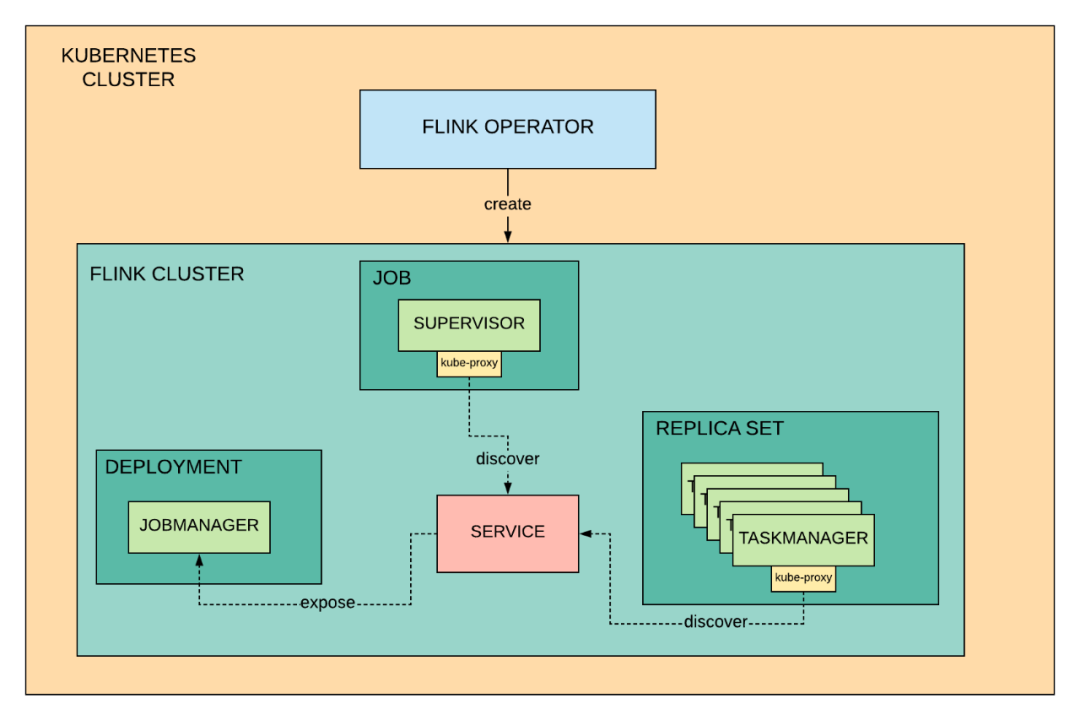
一个 Flink PaaSTA 集群的组件
如果你想了解更多细节,建议你观看我们在 Flink Forward 上的演讲。
Flink on PaaSTA 将我们从数百个 Flink 集群的管理中解放出来,为我们的用户和流处理团队打开了一个充满可能性的新世界。
在基础设施方面,为了使 Python 流处理成为 Yelp 的一等公民,我们现在已基本完成在 Flink onPaaSTA 上添加 Apache Beam 支持。此外,我们还在为 Flink 集群实现自动伸缩和针对每个作业的成本报告。
在用户体验方面,我们正在开发工具,以便让我们的用户可以使用单个配置文件定义流组件的复杂管道。此外,我们也正在忙着构建功能来塑造我们的在线机器学习平台。
如果你想了解以上内容,请继续关注!
英文原文:
Flink on PaaSTA: Yelp’s new stream processing platform runs on Kubernetes
https://engineeringblog.yelp.com/2020/10/flink-on-paasta.html
InfoQ 读者交流群上线啦!各位小伙伴可以扫描下方二维码,添加 InfoQ 小助手,回复关键字“进群”申请入群。回复“资料”,获取资料包传送门,注册 InfoQ 网站后,可以任意领取一门极客时间课程,免费滴!大家可以和 InfoQ 读者一起畅所欲言,和编辑们零距离接触,超值的技术礼包等你领取,还有超值活动等你参加,快来加入我们吧!
-
点个在看少个 bug 👇