开源开放 | OpenKG发布cnSchema重构版本
cnSchema网站:http://cnschema.openkg.cn/
GitHub地址:https://github.com/cnschema/cnSchema
开放许可协议:CC 0
1.类层次结构的优化和扩展
2.针对中文领域需求对类及属性进行了扩增和删改
3.新增了支持cnSchema的预训练抽取模型
1. cnSchema重构简介
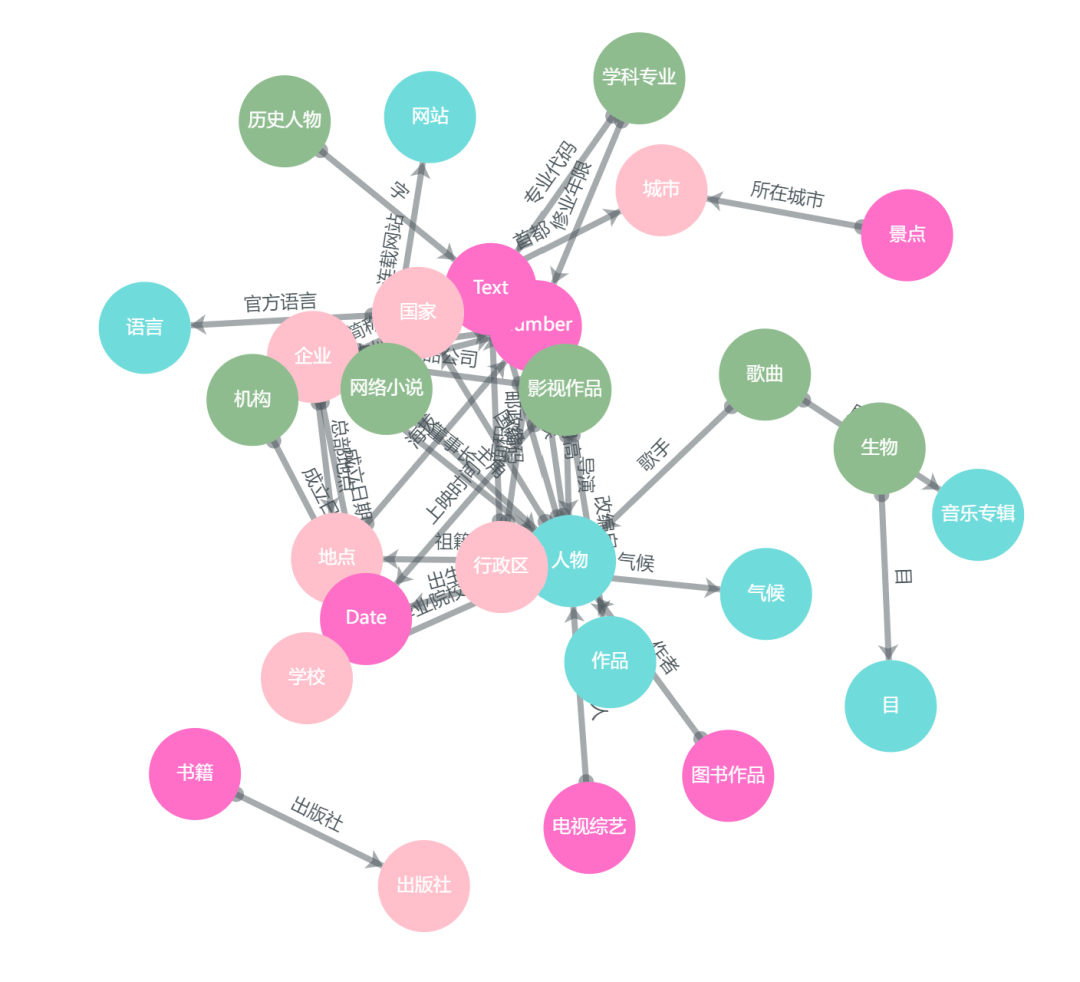
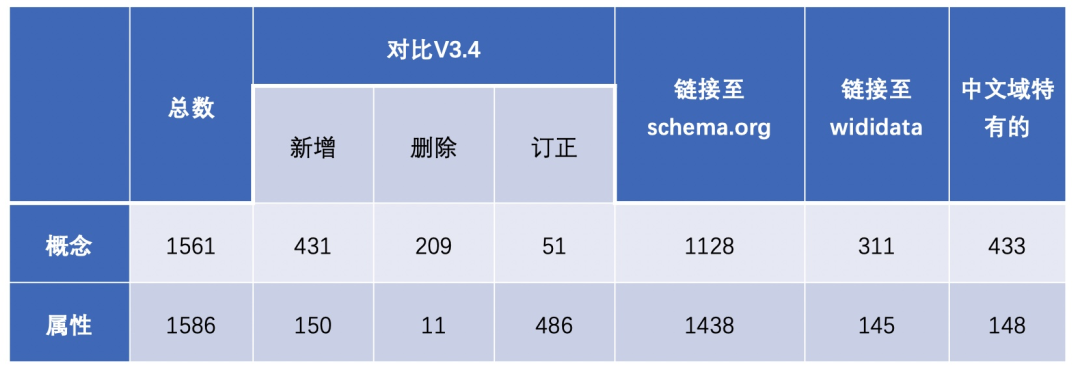
2. 如何使用cnSchema
cnSchema将对外提供基于数据和基于模型的使用方法:
1.下载源数据,进行自主编辑:用户可以在github或cnSchema网站下载最新版的cnSchema数据,包括json/jsonld/xls等格式。cnSchema将发布用于可用于cnSchema编辑的python工具包以及网页版可视化编辑工具,以便用户进行自主编辑和修改。
2.使用基于cnSchema的预训练抽取工具:cnSchema提供了支持cnSchema的预训练抽取工具,该工具可以帮助用户自动构建符合cnSchema定义的知识图谱,目前已支持面向二十多种关系和近五十种概念的三元组抽取。
具体使用方法参考cnschema官方网站:http://cnSchema.openkg.cn
cnSchema会定期更新,欢迎大家试用和提建议。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
登录查看更多
相关内容
Arxiv
0+阅读 · 2022年11月29日
Arxiv
0+阅读 · 2022年11月28日
Arxiv
0+阅读 · 2022年11月27日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月29日
Arxiv
0+阅读 · 2022年11月28日
Arxiv
0+阅读 · 2022年11月27日