Adam优化器再次改进,用长期记忆限制过高学习率,北大孙栩课题组提出
晓查 发自 凹非寺
量子位 报道 | 公众号 QbitAI
Adam作为一种快速收敛的优化器被广泛采用,但是它较差的收敛性限制了使用范围,为了保证更优的结果,很多情况下我们还在使用SGD。
但SGD较慢的收敛速度也令人头疼,所以人们一直在研究进一步优化Adam的方法。AdaBound、RAdam都是在这方面的尝试。
最近北京大学孙栩课题组提出了一种新的优化器AdaMod。这是一种基于Adam的改进优化器,具有自动预热试探法和长期学习速率缓冲。

AdaMod的名称来自Adaptive(自适应)和Momental Bound(矩限制)。
在训练过程中,AdaMod可以轻松击败Adam,同时对学习率超参数、训练曲线都不那么敏感,并且不需要预热。
优点
AdaMod的原理是,在训练的同时计算自适应学习率的指数长期平均值,并使用该平均值来修剪训练过程中过高的学习率。
这一做法提高了优化器的收敛性,无需进行预热,并且降低了对学习率的敏感性。
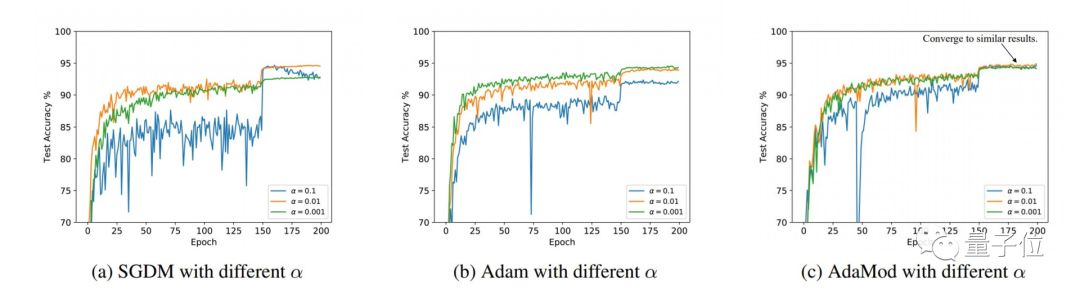
在上图中,我们可以看出,SGDM和Adam的训练结果都依赖于初始学习率的选择。而AdaMod即使学习率相差两个数量级,也能收敛到同一结果。
相比Adam优化器,AdaMod只增加了一个超参数β3,用来描述训练中记忆长短的程度。
这种长期记忆解决了自适应学习率的异常过大数值,免于让优化器陷入了不良的状态。
与之前的RAdam优化器类似,AdaMod能够从训练开始就控制自适应学习率的变化,从而确保训练开始时的稳定性,无需预热。
相关报道:
RAdam优化器又进化:与LookAhead强强结合,性能更优速度更快
在3个基于Transformer的神经机器翻译模型上,没有预热的AdaMod显示出了比预热的Adam有着更快的收敛速率和更好的收敛结果。
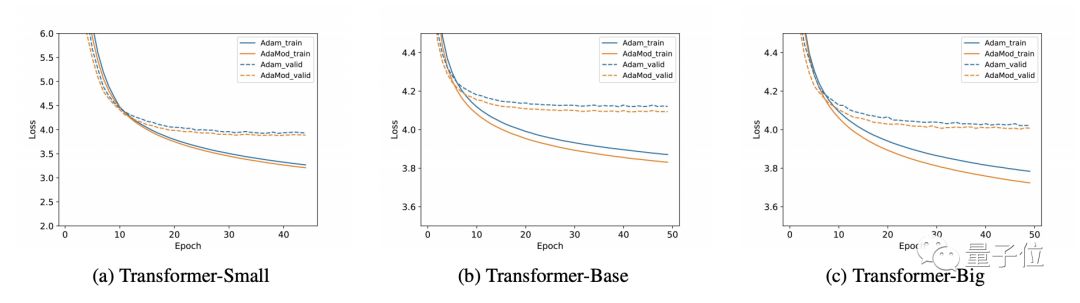
而Adam优化器如果不预热,效果可能会非常差,达到完全不可用的程度。
算法实现
其实,AdaMod的思路也很简单,只是在Adam的基础上做了一个小幅的修改。
如AdaBound所描述的,不稳定和异常的学习率通常出现在训练快结束时,这会危及自适应方法的泛化性能。
相关报道:
中国学霸本科生提出AI新算法:速度比肩Adam,性能媲美SGD,ICLR领域主席赞不绝口
所以AdaBound的思路是,先定义学习率的下限ηl和ηu,一开始下限为0,上限为∞,随着训练过程的进行,上下限分别收敛到SGD的学习率α。
Adam会根据一阶矩和二阶矩的梯度估计值计算自适应学习率。受指数滑动平均(EMA)的启发,AdaMod计算梯度的低阶矩,并通过参数β3将记忆带到下一个步骤中。


可以看出,Adam和AdaMod的前8步完全相同,后者只是比前者多了9、10两步。
具体来说,在Adam中进行以下操作:
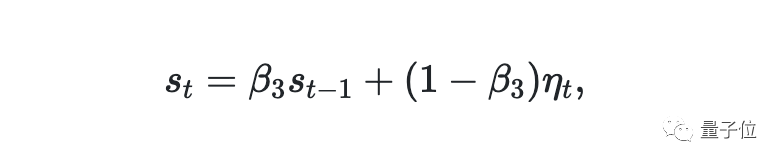
指数滑动平均的范围是1/β3。β3就是记忆长短的量度,它越接近1,记忆长度也就越长。
例如当β3=0.9时,记忆平均范围是10个周期;当β3=0.999时,平均范围是1000个周期。
根据β3可以算出当前步骤的平滑值和之前平滑值的关系。
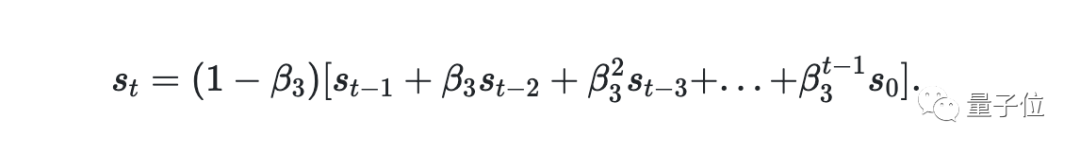
通过这个方程,我们定义了当前平滑值和过去“长期记忆”(long-term-memory)的关系。显然,当β3=0时,AdaMod则完全等价于Adam。
计算出当前平滑值后,在它和当前Adam算出的学习率ηt中选出一个最小值,从而避免了出现过高学习率的情况。
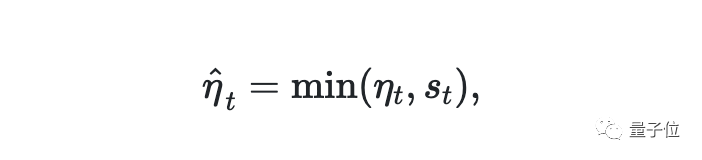
这项操作可以看作是逐个元素地削减学习率,从而使输出受到当前平滑值的限制。
现在你已经可以直接通过pip安装。
pip install adamod局限性
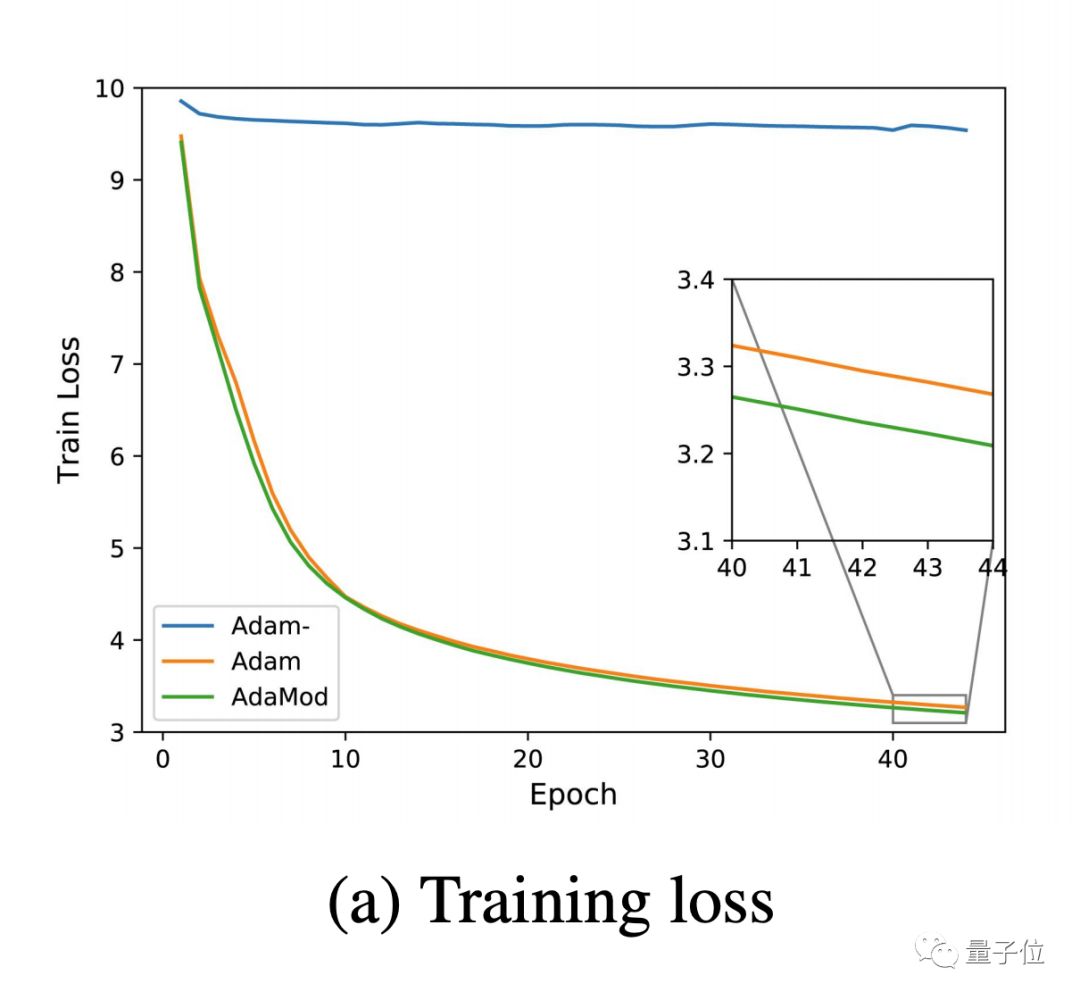
尽管AdaMod胜过Adam,但是在更长的训练条件下,SGDM仍然可以胜过AdaMod。
因此,有人提出了结合DiffGrad和AdaMod的DiffMod算法,使用另一个参数“len_memory”代替β3,可以将batch的总数传递它,更易于记忆和追踪。
关于作者
这篇文章的第一作者是Ding Jianbang,通讯作者是孙栩副教授,他本科毕业华中科技大学,2010年从东京大学博士毕业,曾在微软公司美国雷蒙德研究院实习。

他的研究方向为自然语言处理、机器学习、深度学习,曾担任EMNLP、IJCNLP等国际学术会议的领域主席。
之前的AdaBound优化器就是孙栩组的骆梁宸同学提出的。本文的第一作者也感谢了与骆梁宸等人参与的讨论。
传送门
博客讨论:
https://medium.com/@lessw/meet-adamod-a-new-deep-learning-optimizer-with-memory-f01e831b80bd
论文地址:
https://arxiv.org/abs/1910.12249v1
AdaMod源代码:
https://github.com/lancopku/AdaMod
DiffMod源代码:
https://github.com/lessw2020/Best-Deep-Learning-Optimizers/blob/master/adamod/diffmod.py
— 完 —
新年福利 | 抽奖送小度智能音箱
新年快乐!抽3位小伙伴送出小度在家1C红色版,点击“阅读原文”,即可在微博参与转发抽奖,周三10点开奖哦 ~


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !

