干货 | 元旦,一起NLP!(下)
AI 科技评论按:本文作者田宇菲,本文首发于公众号紫冬科协(ID:asta201409),AI 科技评论授权转载。
0.Roadmap
1. 模型 | 语言模型与词嵌入
2. 模型 | LSTM
3. 盘点 | 那些顶级会议
4. 模型 | Seq2Seq 和 Attention机制
看上去和CV存在不小的差别。以我粗浅地理解,主要原因有以下两点:
1)对输入的处理不同。
我们知道,计算机不认识一个单词,不懂得它的意思,也不知道它和哪些词意思相关联,和另外哪些词经常一起出现。
所以,对于自然语言的处理需要首先将词语表示为向量的形式(Word2Vec, GloVe等),再把一个个词向量拼接为句子(Recursive & Recurrent NN等),甚至在需要的时候把句子拼接起来,处理整段甚至整篇文章的矩阵(CNN为主)。
相比之下,图片不需要经过复杂处理,便可作为各种模型的输入矩阵。
2)模型选择的区别。
例如,在CV中CNN被广泛应用,而在NLP中RNN、LSTM用的更多。GAN和VAE也是同样的关系。
这是由于自然语言的特殊性质:从我们口中“冒”出的一个词往往受到前文的影响,同时影响了后文的词语选择。
一、语言模型与词嵌入
传统的语言模型基于自然语言规则(所谓经验主义),而现代的语言模型基于统计(所以理性主义),数据表明,基于统计的语言模型准确率好于基于规则的语言模型。
1)N-gram Model
下图是最基本的统计语言模型。这是一个计算"I like deep learning."这句话出现概率的例子。
从中我们可以看出,第i个词出现的概率,取决于它周围的N个词(假设我们已经拥有了Corpus作为词频和关联的先验知识),我们称这种模型为 N-gram Model。

虽然N越大,模型越准确,但是我们不能承受计算量以指数爆炸式增长。一般用N=2~5。
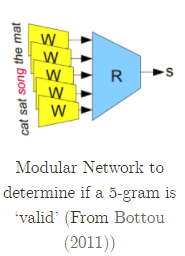
2)New Representation With DL
可以使用机器学习中的不同分类器来估计语言模型的条件概率。这里我们关注基于神经网络模型的方法,这一类方法可以统称为神经网络语言模型(Neural Network Language Model,NNLM)。
NNLM中以前馈神经网络语言模型最为经典,具体内容可参考 Bengio 2003年发表在JMLR上的论文:
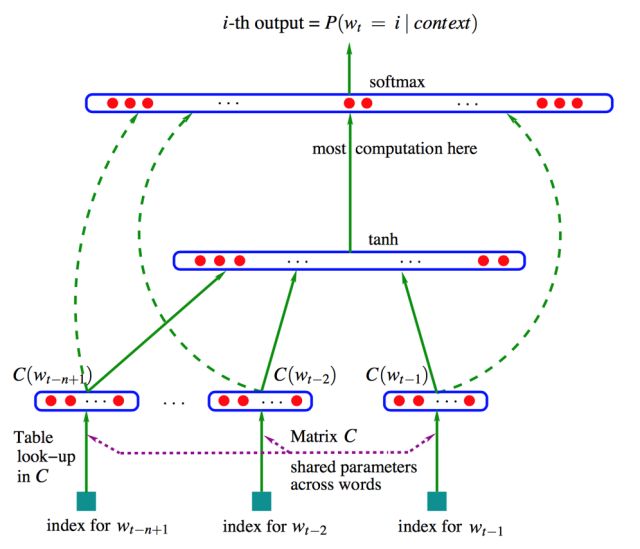


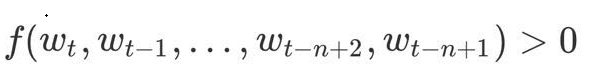
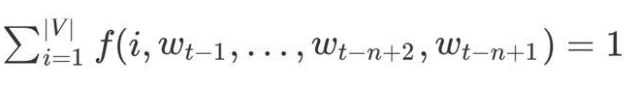

模型可分为特征映射和计算条件概率分布两部分,让我们来看一下条件概率的计算:

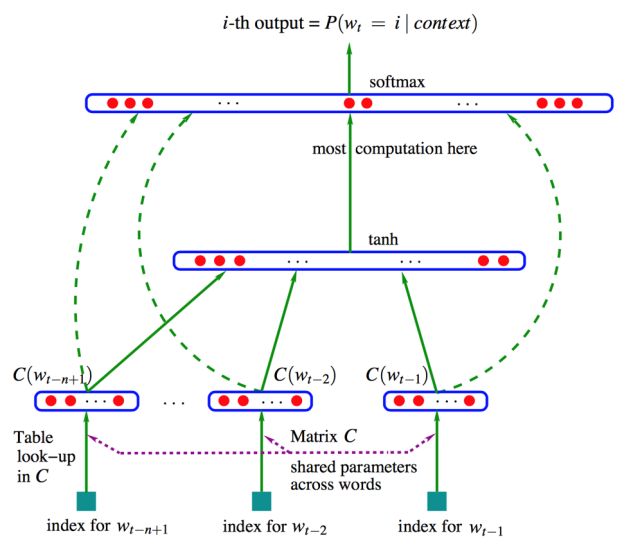

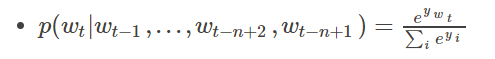

终于可以开始训练了



参考资料:神经网络语言模型(NNLM)
3)想知道词嵌入的效果?
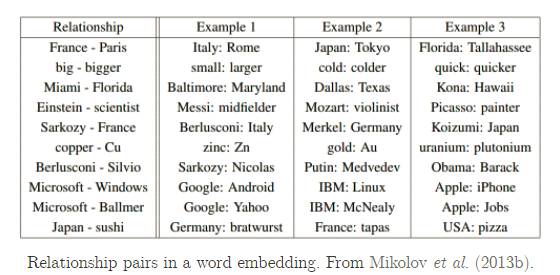
作者从https://deeplearning4j.org/word2vec上扒来了几张图,可以直观地看一看 Word2Vec 模型的效果。下图罗列出了在词集 V 中,和“Sweden”中距离最近的9个词:
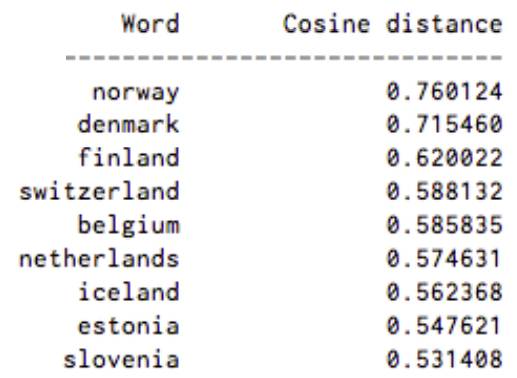
评判标准为两个单词的余弦距离。
空间的维数在通常在50~300之间。
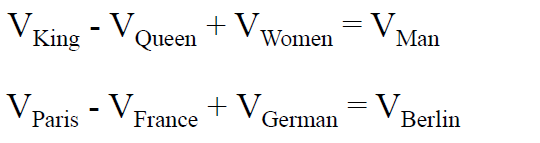
King 和 Queen 的距离,等于 Man 和 Women 的距离。Paris 和 France 的距离,等于 Berlin 和 German 的距离。
下面的图例展示了类似的功能:
二、 模型 | 你们想知道的LSTM
Recurrent Neural Networks
在您阅读这篇文章时候,您那聪明绝顶的大脑都是基于已经拥有的对先前所见词的理解来推断当前词的真实含义。它不会将所有的东西都全部丢弃,然后用空白的大脑进行思考。
传统的神经网络并不能做到这点,而RNN 解决了这个问题。RNN 是包含循环的网络,允许信息的持久化。
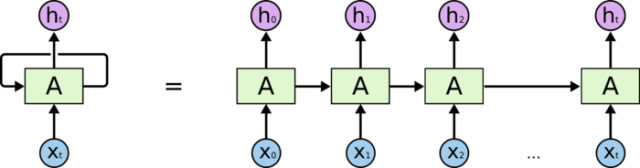
在上面的示例图中,左边代表一个RNN神经网络的模块,A 。它正在读取某个输入 x_i,并输出一个值 h_i。循环可以使得信息可以从当前步传递到下一步。
这些循环使得 RNN 看起来非常神秘。然而,如果你仔细想想,这样也不比一个正常的神经网络难于理解。RNN 可以被看做是同一神经网络的多次复制,每个神经网络模块会把消息传递给下一个。所以,如果我们将这个循环展开,就得到了右边。
然鹅,假设一个人说了这样一段话:“I grew up in France... (此处省略100 words)...I speak fluent French”。RNN很可能会因为间隔距离太远,而忽视了第一句话的重要性,不能正确预测French这个词。这就是长期依赖的问题。
而我们接下来要介绍的LSTM则可以解决这个问题。LSTM 是一种特别的 RNN,比标准的 RNN 在很多的任务上都表现得更好。因为它可以学习长期依赖信息。
Long Short-Term Memory
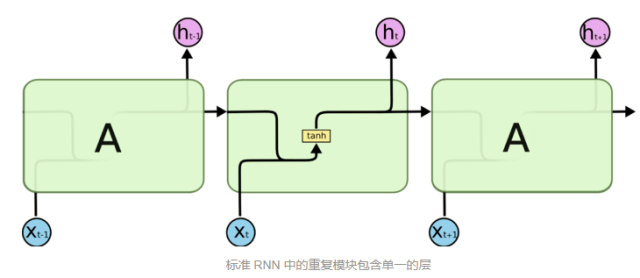
LSTM 通过刻意的设计来避免长期依赖问题。上图是一个普通RNN模块,所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。
下图为改进了的LSTM模块,虽然 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
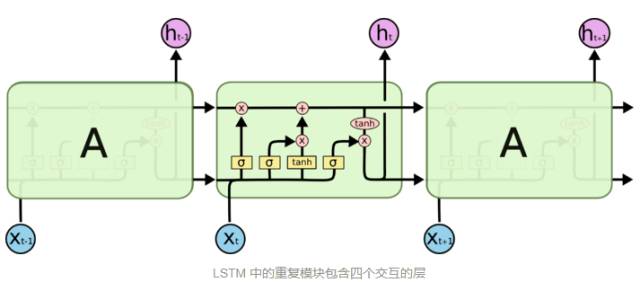
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。
下面我们来逐步理解LSTM的门:
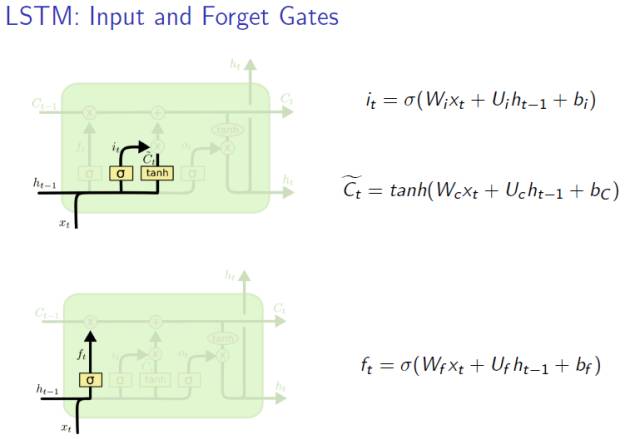
Forget Gate
每进入一个新细胞,忘记门都会帮我们决定从细胞状态中丢弃什么信息。
该门会读取 h_{t-1} 和 x_t,输出一个在 0 到 1 之间的数值给每个在细胞状态 C_{t-1} 中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
Input Gate
下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。sigmoid 层称 “输入门层” 决定什么值我们将要更新。
然后,一个 tanh 层创建一个新的候选值向量,\tilde{C}_t,会被加入到状态中。下一步,我们会讲这两个信息来产生对状态的更新。
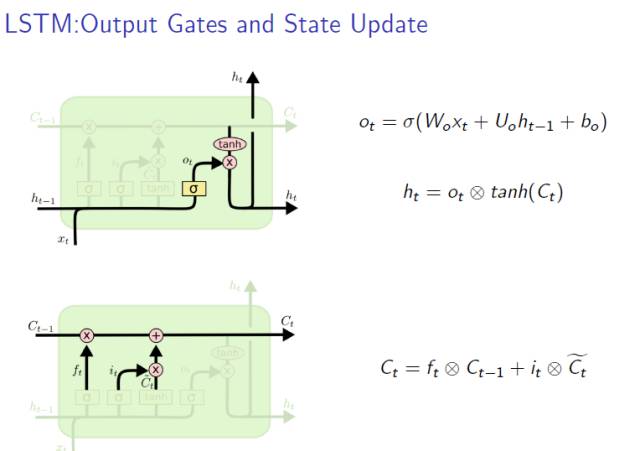
Output Gate
最终,我们需要确定输出什么值。这个输出将会基于我们的细胞状态,但是也是一个过滤后的版本。
首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
Gate Update
现在是更新旧细胞状态的时间了,C_{t-1} 更新为 C_t。我们把旧状态与 f_t 相乘,丢弃掉我们确定需要丢弃的信息。接着加上 i_t * \tilde{C}_t。这就是新的候选值,根据我们决定更新每个状态的程度进行变化。
以上内容全部翻译、节选自Christopher Olah 的博文
除此之外,LSTM还有许多变体,可以在上面的链接中找到~
三、 盘点 | 那些顶级会议
Conference:
1) ACL: Annual Meeting of the Association for Computational Linguistics
2) NIPS: Neural Information Processing Systems
3) AAAI: American Association for Artificial Intelligence
4) EMNLP: Empirical Methods on Natural Language Processin
5) IJCAI: International Joint Conference on Artificial Intelligence
6) ICML: International Conference on Machine Learning
7) ICLR: International Conference on Learning Representations
8) COLT: Conference On Learning Theory
四、 模型 | 相当不错的Seq2Seq
Sequence to Sequence技术,突破了传统的固定大小输入问题框架,开通了将经典深度神经网络模型(DNNs)运用于翻译与智能问答这一类序列型(Sequence Based,项目间有固定的先后关系)任务的先河,并被证实在英语-法语翻译、英语-德语翻译以及人机短问快答的应用中有着不俗的表现。
举个栗子:
在对话机器中:我们提(输入)一个问题,机器会自动生成(输出)回答。这里的输入和输出显然是长度没有确定的序列(sequences)。
同样,对于翻译这种应用,难道我们要让每一句话都有一样的字数吗,比如五言、七言之类的 = =
问世
Seq2Seq被提出于2014年,最早由两篇文章独立地阐述了它主要思想,分别是Google Brain团队的《Sequence to Sequence Learning with Neural Networks》和Yoshua Bengio团队的《Learning Phrase Representation using RNN Encoder-Decoder for Statistical Machine Translation》。这两篇文章针对机器翻译的问题不谋而合地提出了相似的解决思路,Seq2Seq由此产生。
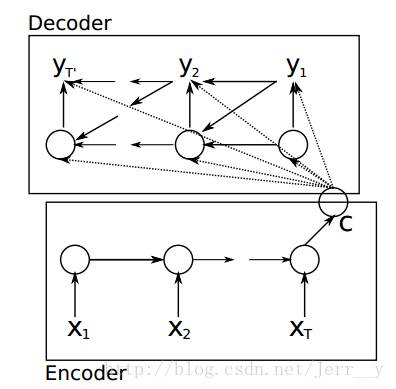
Encoder-Decoder
Encoder-Decoder框架应用场景异常广泛。所以在这里详细说明一下:
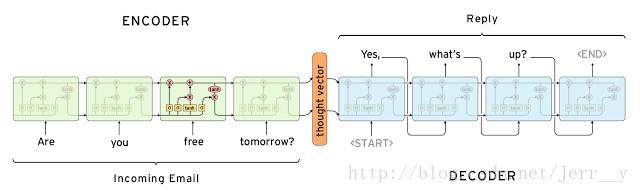
根据Cho et al.的论文,其中 Encoder 部分就是一个RNNCell (RNN, LSTM, GRU, etc.)。如下图,每个 timestep, 我们向 Encoder 中输入一个词向量,直到句子的最后一个输入X_T。然后,Encoder 输出整个句子的语义向量 c(一般 c=h(X_T))。因为 RNN 的特点就是把前面每一步的输入信息都考虑进来了,理论上这个 c 就能够把整个句子的信息都包含了。
在 Decoder 中,我们根据 Encoder 得到的句向量 c, 一步一步地把蕴含在其中的信息分析出来,得到目标语言序列。
接下来是可以跳过的数学部分
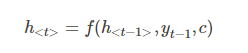
根据 h<t> 我们就能够求出 yt 的条件概率:
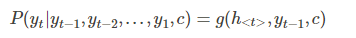
f 函数结构应该是一个 RNNCell 结构或者类似的结构(原文中用的是 GRU,LSTM的变体);g 函数一般是 softmax 。
我们可以先这样来理解:在 Encoder 中我们得到了一个涵盖了整个句子信息的实数向量 c ,现在我们给 Decoder 输入一个启动信号 y0(如特殊符号<START>), 然后Decoder 根据 h<0>,y0,c ,就能够计算出 y1 的概率分布了,同理,根据 h<1>,y1,c 可以计算y2 的概率分布…以此类推直到预测到结束的特殊标志 <END>,才结束预测。
Attention Mechanism 注意力机制
Attention机制肥肠好理解,您的日常生活中充满了它。比如过马路,你的Attention会被更多地分配给红绿灯和来往的车辆上,虽然此时你看到了整个世界;比如你遇到了自己的爱豆,你的Attention会更多的分配在此时神光四射的Idol身上,除了Ta之外的整个世界对你来说跟不存在是一样的…..
同样的,为了让机器能够focus在更重要的东西上,所以就有了 Attention Model,它的出现让机器的表现大大地提升了。
来看一个栗子:
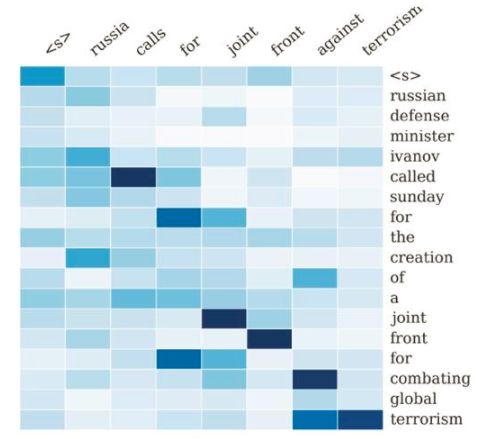
图片来自论文 A Neural Attention Model for Sentence Summarization
这个例子中,我们要总结长句子为短句子,而要尽可能的保留重要信息。Encoder-Decoder框架的输入句子是:“russian defense minister ivanov called sunday for the creation of a joint front for combating global terrorism”。对应图中纵坐标的句子。系统生成的摘要句子是:“russia calls for joint front against terrorism”,对应图中横坐标的句子。可以看出模型已经把句子主体部分正确地抽出来了。矩阵中每一列代表生成的目标单词对应输入句子每个单词的AM分配概率,颜色越深代表分配到的概率越大。
可以说Attention机制是前年提出的最重要的模型之一了,在深度学习和自然语言处理方向都有很好的应用。有兴趣的同学可以看看:attention-and-memory-in-deep-learning-and-nlp
应用领域
机器翻译,自动对话机器人,文档摘要自动生成,图片描述自动生成等等,在计算机视觉领域同样也很有用哦。
整理 I 编辑 I Figo
版权归原作者 I 如有侵权 I 请联系删除
文案|田宇菲
————— 新人福利 —————
关注AI 科技评论,回复 1 获取
【数百 G 神经网络 / AI / 大数据资源,教程,论文】
————— AI 科技评论招人了 —————
AI 科技评论期待你的加入,和我们一起见证未来!
现诚招学术编辑、学术兼职、学术外翻
详情请点击招聘启事
————— 给爱学习的你的福利 —————
上海交通大学博士讲师团队
从算法到实战应用,涵盖CV领域主要知识点;
手把手项目演示
全程提供代码
深度剖析CV研究体系
轻松实战深度学习应用领域!
详细了解请点击阅读原文
▼▼▼

————————————————————




