荐读:五月最值得阅读的15篇人工智能文章


在过去一个月中,15篇最值得阅读的AI文章(附链接):
1、沃森的创造者想教人工智能一个新把戏:常识
2011年,超级计算机“深蓝”的继任者“沃森”在问答游戏《危险边缘!》中击败多名人类冠军,自此名声大噪。
近年来,沃森的创造者大卫·费鲁奇(David Ferrucci)努力向他的新发明解释一个儿童故事,并试图让沃森理解将植物放在阳光下能保持健康这一常识。
因为科学家们坚信,从语言理解到机器人技术,常识是推动一切进步的关键。
费鲁奇还提出了一个看似简单却很难回答的问题:“我们能让机器真正理解它们所阅读的内容吗?”
链接:https://www.wired.com/story/watsons-creator-teach-ai-new-trick-common-sense/
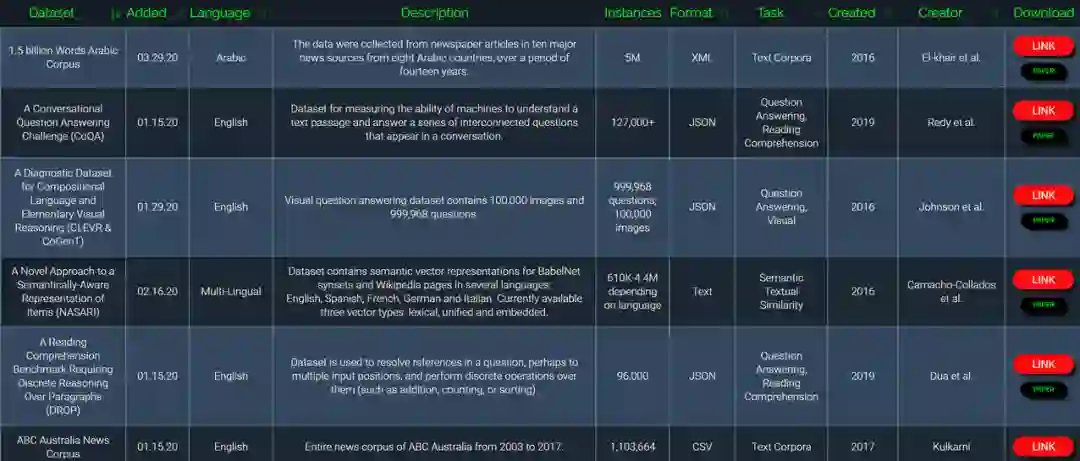
2、公布元数据集:一种用于少镜头学习的数据集
少镜头分类是一种分类方法,其中训练集包含的类与测试时可用的类完全不同。在这种特殊情况下,培训过程构建了一个模型,该模型可以仅用几个示例对新类进行分类。
现在,使用Meta Dataset,一个由Google创建的新数据集,就可以创建这种模型。
链接:https://ai.googleblog.com/2020/05/announcing-meta-dataset-dataset-of.html
3、人工智能可以更好地检测仇恨言论
Facebook 人工智能部门的研究人员发布了这篇文章,解释他们如何在脸书上对抗仇恨言论。这是他们需要完成的复杂而重要的任务之一。
为此,他们使用了本文中列出的各种人工智能技术。现在,这些技术可以主动检测出 88.8% 的已被删除的仇恨言论内容。
链接:https://ai.facebook.com/blog/ai-advances-to-better-detect-hate-speech/
4、当训练数据受性别影响时,AI 在疾病诊断方面表现更差
在构建人工智能系统时,消除数据偏差是我们应考虑的最重要的事情之一。尤其是当我们要为某个医疗系统创建人工智能系统时,消除数据偏差显得尤为重要。
在本文中,作者讨论了数据集中缺少不同数据的危险和这种错误所带来的巨大影响,还揭示了一个令人惊讶的现象:当数据有性别之差时,疾病诊断AI将发挥失常。
链接:https://www.statnews.com/2020/05/25/ai-systems-training-data-sex-bias/
5、一个又大又坏的 NLP 数据库
这实际上是一个包含大量 NLP 数据集的站点,它就像一个工程师的游乐场,其中包含了各式各样的 NPL 数据库,点击链接即可查看!
6、40 年后,英伟达用 AI 重新创造了 PAC-MAN
自从 PAC-MAN 第一次在日本走红并火遍全球以来,四十年过去了。而现在,由 AI 提供的复古经典已经重生:NVIDIA Research 经过 5 万集游戏的训练,开发出了一款强大的新型人工智能模型 NVIDIA GameGAN。
这是一种生成式对抗网络,可以生成一个功能齐全的 PAC-MAN 版本,且无需底层游戏引擎。这意味着,即使不了解基本游戏规则,人工智能也可以用令人信服的结果重现游戏。酷炸了!

7、人工智能的能耗惊人
训练人工智能系统需要大量的处理能力,而大量的处理能力等于大量的能量消耗,这反过来又对环境有害。
这就是为什么来自麻省理工学院的天才们开发了一种新的自动化人工智能系统,该系统不仅提高了计算效率,还减少了AI系统的碳足迹。
链接:https://scitechdaily.com/artificial-intelligence-consumes-a-startling-amount-of-power-mit-system-reduces-the-carbon-footprint/
8、旧工具,新技巧:为数据科学家提升计算笔记本体验
计算笔记本是一个研究从事代码、数据和可视化工作的人所进行的丰富互动的独特融合的理想领域。在这篇文章中,来自微软的一个团队讨论了计算笔记本的一些问题,并给出了如何改进的建议。
文中所讨论的问题是从半结构化访谈中收集的,然后该团队对150多名数据科学家进行了调查,为了在笔记本电脑中通过示例实现编程,研究人员选择使用微软程序合成(Microsoft Program Synthesis)。
链接:https://www.microsoft.com/en-us/research/blog/old-tools-new-tricks-improving-the-computational-notebook-experience-for-data-scientists/
9、构成动画师Pose Animator
GitHub上的这篇文章详细解释了如何使用该工具:根据PoseNet和FaceMesh的识别结果,绘制一个二维矢量图,并对其包含的曲线进行实时动画处理。它借鉴了计算机图形学中基于骨架的动画思想,并将其应用于矢量角色。
链接:https://github.com/yemount/pose-animator/
10、TensorFlow 2.2.0发布
TensorFlow 2.2.0在2.1.0版本出世的四个月后发布,本文提出新版本的主要特点和改进方面,比如一种新的用于CPU/GPU/TPU的TF 2分析器。它提供设备和主机性能分析,包括输入管道和TF操作,并尽可能提供优化建议。
链接:https://blog.exxactcorp.com/tensorflow-2-2-0-released/
11、OpenAI首次推出带有1750亿参数的GPT -3语言模型
GPT-3是一个无监督机器学习训练的自回归模型,它以少量镜头学习为重点,在推理运行时提供任务的演示。该模型来自OpenAI,是一个带有1750亿的参数,内存700Gb的NLP模型。
实验表明,GPT-3可以很好地生成新闻文章和任务,比如在句子中使用新单词或执行算术,但在常识推理方面,它可能会有不足。
链接:https://venturebeat.com/2020/05/29/openai-debuts-gigantic-gpt-3-language-model-with-175-billion-parameters/
12、Facebook AI, AWS合作伙伴将发布新的PyTorch库
这一消息来自Facebook和AWS:他们合作开发了新的PyTorch库,目标是大规模的弹性和容错模型培训,以及高性能的PyTorch模型部署。
链接:https://ai.facebook.com/blog/facebook-ai-aws-partner-to-release-new-pytorch-libraries-/
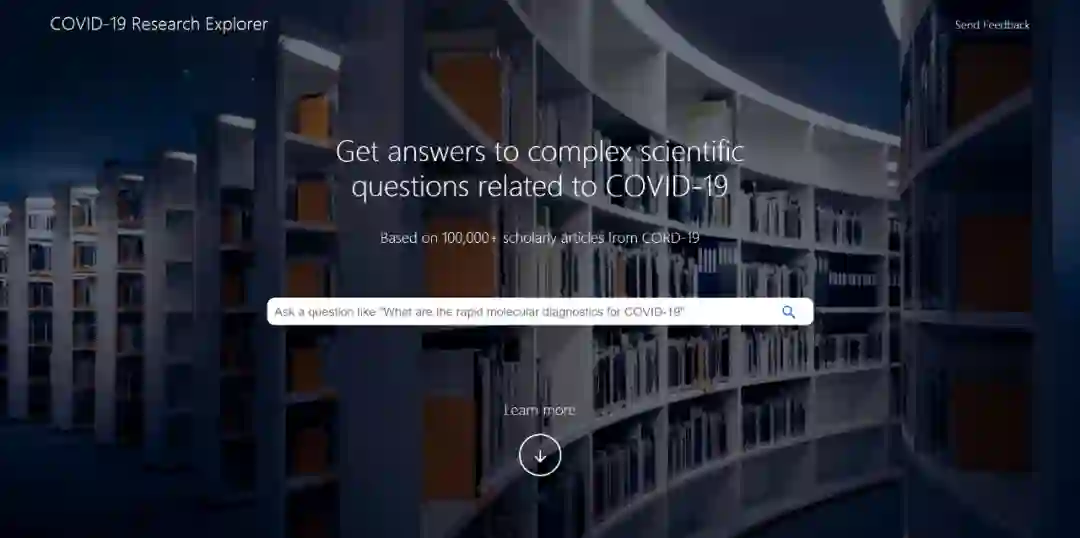
13、COVID-19研究探险家
谷歌的人工智能团队发布了一个新工具,该工具能够帮助研究人员遍历大量的冠状病毒论文、期刊和文章。
COVID-19 research explorer工具是一个语义搜索界面,位于COVID-19开放研究数据集(CORD-19)之上。赶快点击链接试一试!
链接:https://covid19-research-explorer.appspot.com/
14、TFRT:一个全新的TensorFlow runtime
目前,人们对TensorFlow最大的抱怨可能是它的速度。这就是为什么随着2.2.0谷歌一起出现了TFRT——一个全新的运行时刻,它将取代现有的TensorFlow runtime,与MLIR紧密集成,负责在目标硬件上高效地执行内核。
链接:https://blog.tensorflow.org/2020/04/tfrt-new-tensorflow-runtime.html?m=1
15、关于人工智能中的积极心理学和伦理
在一个非常有趣的采访中,2.0 DAO Sovereign Nature Initiative的创意总监、联合创始人Florian Schmitt和AI伦理学家John C. Havens讨论了幸福的重要性以及AI如何塑造未来。
链接:https://blog.re-work.co/applications-of-gans-video-presentations/
资料来源:
https://rubikscode.net/2020/06/02/top-15-ai-articles-you-should-read-this-month-may-2020/