论文浅尝 - AAAI2020 | 从异质外部知识库中进行基于图的推理实现常识知识问答

会议:AAAI2020
论文链接:https://arxiv.org/pdf/1909.05311.pdf
摘要
常识问答旨在回答需要背景知识的问题,而背景知识并未在问题中明确表达。关键的挑战是如何从外部知识中获取证据并根据证据做出预测。最近的研究要么从昂贵的人类注释中生成证据,要么从结构化或非结构化知识库中提取证据,而这些无法同时利用这两种资源。在这项工作中,建议自动从异构知识源中提取证据,并根据提取的证据回答问题。具体来说,从结构化知识库(即ConceptNet)和Wikipedia纯文本中提取证据。为这两种来源的数据构造图以获得证据的关系结构。基于这些图,提出了一种基于图的方法,该方法包括基于图的上下文单词表示学习模块和基于图的推理模块。第一个模块利用图形结构信息来重新定义单词之间的距离,以学习更好的上下文单词表示形式。第二个模块采用图卷积网络将邻居信息编码为节点表示形式,并通过图注意力机制汇总证据以预测最终答案。CommonsenseQA数据集上的实验结果表明,对两种知识源的基于图的方法在强基准上带来了改进。此方法在CommonsenseQA数据集上实现了最先进的准确性(75.3%)。
介绍
在人工智能和自然语言处理中,推理是一项重要且具有挑战性的任务,这是“从原理和证据中得出结论的过程”。“证据”是燃料,“原理”是依靠燃料运行以进行预测的机器。大多数研究只将当前的数据点作为输入,忽略了背景知识中的重要证据。这篇文章研究的是常识问答,收集背景知识并使用这些知识推理出问题的答案。对于常识推理问题,常见的解决方案有
(1)根据人工标注的证据生成新的解释。
(2)从ConceptNet中获取结构化的知识。
(3)从Wikipedia获取相关文本知识。
从ConceptNet中获取的结构化的知识,包含着不同概念之间的关联信息,有助于机器进行推理,但覆盖率较低。纯文本数据可以提供高覆盖率的证据解释,可以形成对结构化知识的补充,目前的方法中都只针对同一种的知识来源,不能同时利用两种知识。
基于这种目的,本文提出从异质的外部知识库中自动收集证据,并基于这些证据实现常识知识问答。
方法
方法概述
方法可分为两部分:1)知识抽取;2)基于图的推理
(1)在知识抽取部分,自动地从ConceptNet抽取出图路径,并且从Wikipedia中抽取出相关的句子。利用两个源的关系结构,构建成图。(2)在基于图推理部分,提出了两个基于图的推理模块:基于图的上下文单词表示学习模块,和基于图的推理模块。方法概览如下图所示:
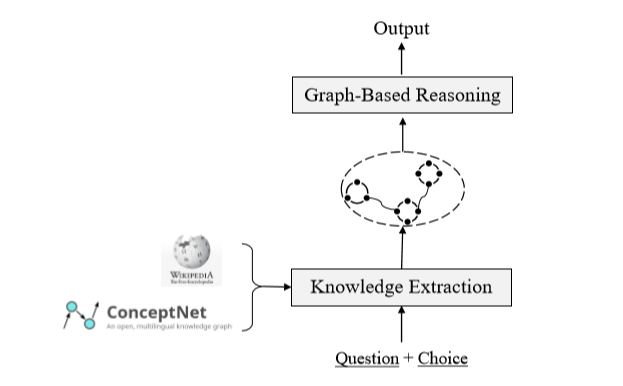
知识抽取
根据给定的问题和选项,使用本文的方法从ConceptNet和Wikipedia中获取相应的证据。
从ConceptNet抽取出结构化知识:
ConceptNet是一个大规模的常识知识库,有百万级的节点和边,ConceptNet中的三元组包含四个部分,两个节点、一个关系和一个关系权重,对于每个问题和选项,首先在给定的ConceptNet中确定对应的实体,然后搜索从问题实体到选项实体的路径(路径少于三次),并且将三元组合并成一个图,其中节点为三元组,边为三元组之间的关系。并且规定如果两个三元组有相同的实体,则为两个三元组添加连边。将组合成的图称之为Concept-Graph。并且根据ConceptNet中的关系模板,将三元组转换成自然语言文本。
从Wikipedia中抽取文本知识:
使用Spacy从Wikipedia中抽取了1.07亿条句子,并且使用Elastic Search tools为句子建立索引。首先对问题和选项进行预处理,删除给定问题和选项中的停用词,然后将这些词连接起来作为queries,在Elastic Search engine中进行搜索,这个引擎会根据queries和所有Wikipedia的句子进行匹配得分进行排序,选取topK个句子作为证据(实验中K取10)。为了获取Wikipedia证据中的结构信息,利用语义角色标注(SRL)为句子中每个谓词提取对应的要素(主语、宾语)。将要素和谓词作为图中的节点,谓词和参数之间的关系作为图的边,为了增强图的连通性,去掉停用词并根据规则为节点a,b间建立联系:1)节点a包含于节点b,且a中的单词数量大于3;2)节点a和节点b只有一个单词不同,并且a和b的单词数量都大于3。将组合成的图称之为Wiki-Graph。
基于图的推理
本文在抽取出的证据的基础上,提出了基于图的推理模型,如下图所示:
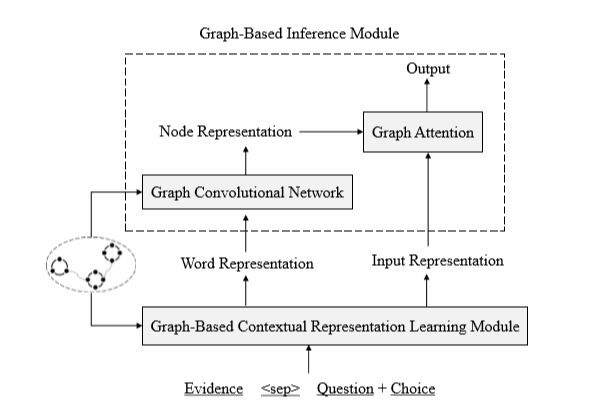
推理模块由两个小模块组成:1)基于图的上下文表示学习模块:使用图信息重新定义单词间的距离,学习到更好的上下文词的表示;2)基于图的推理模块:使用GCN和图注意力机制,获得节点的表示,用于最终的预测。
基于图的上下文表示学习:
由于预训练模型具有很强的文本理解能力,并且在各种自然语言处理任务上取得了较好的结果。本文使用XLNet,具有捕获远距离依赖的优势。获得每个单词的表示的简单方法是将所有的证据作为单个序列连接起来,并且将原始的输入,输入到XLNet中,但这将使得在不同证据中的同一个词分配一个较长的距离,因此利用图结构重新定义证据词之间的相对位置,这样会使得相关的词的相对位置比较近,获得更好的上下文的相关词表征。具体来说是使用拓扑排序根据构造的图结构对输入的证据进行重新排序,包括ConceptNet和Wikipedia所抽取出来的文本。将经过排序后的证据文本,和问题选项进行拼接作为XLNet的输入。通过将抽取的图转换成自然语言文本,实现了对两种异质知识来源信息的融合。
基于图的推理模块:
使用XLNet模型为预测提供了词级别的信息,此外,图还可以提供语义级别的信息,如关系中的主语、宾语。因此,本文对图级别的证据进行聚合,用作最后的预测。使用图卷积神经网络,将Concept-Graph和Wiki-Graph进行编码,得到节点表示。第i个节点表示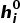
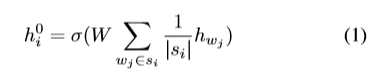
为实现基于图的推理,使用聚合和组合两个步骤实现信息的传播。从每个节点的邻居聚合信息,针对第i个节点,聚合得到信息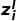
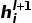
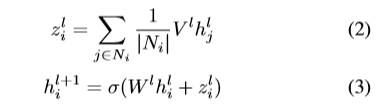
使用图注意力机制对图信息进行进一步处理。
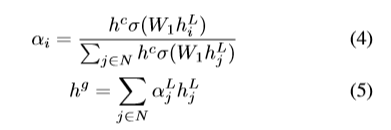
最后使用多层感知机(MLP)计算置信度分数,将输入的表示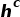
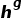

实验
实验设置:
数据集为CommonsenseQA,包含12102个例子,9741个用于训练,1221个用于验证,1140个用于测试。使用XLNet large cased作为预训练模型。每个选项的输入形式为“
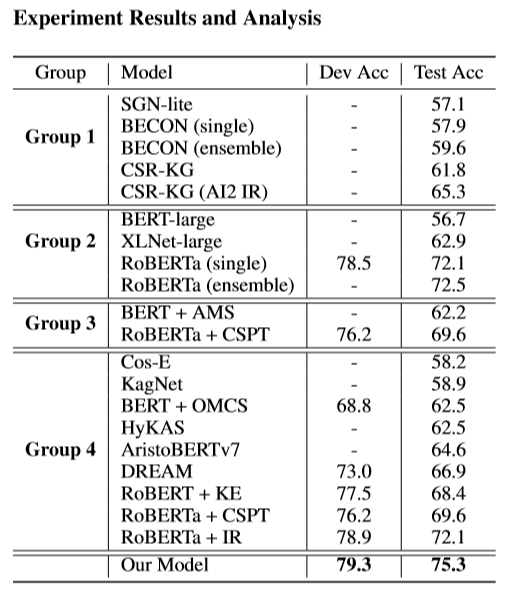
其中,Group 1:不使用描述或papers的模型;Group 2:不使用抽取出的知识的模型;Group 3:使用抽取出的知识的模型;Group 4:使用抽取出的非结构化知识的模型。从实验结果可以看出,异质外部知识和基于图的推理模型帮助本文的模型获得了显著的改进,取得较好的结果。
消融实验:
基于图推理模块的有效性。

实验结果表明,通过拓扑排序可以融合图结果蕴含的信息,改变词与词之间的相对位置,从而更好的表示词的上下文信息。
异质知识来源的有效性。
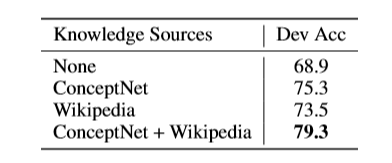
实验表明,单独结构化的知识和非结构化的文本都可以带来有效的提升,并且将两个结合在一起获得了更好的性能。
总结
本文解决的是常识问答问题。本文提出的方法由知识抽取和基于图的推理两大部分组成。在知识抽取部分,从异质的知识来源中抽取出来证据信息,并且将其构建了图,并利用了关系结构信息。在基于图的推理部分,提出了基于图的上下文词表示学习模块,以及基于图的推断模块。第一个模块使用了图结构信息对单词间的距离重定义,以学习到更好的上下文词表示。第二个模块使用了GCN将邻居信息编码到节点的表示中,然后使用图注意力机制进行证据的聚合,用于最终答案的推断。实验结果显示,本文的模型在CommonsenseQA leaderboard上实现了state-of-the-art。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。


