腾讯研究成果登Nature子刊:scBERT攻克单细胞测序数据分析痛点
机器之心报道
新研究成果对精准医疗打开了新路。
AI 在科研领域再次展现了实力。最近,研究人员首次将 BERT 预训练和微调的范式引入单细胞转录组数据分析中。
9 月 27 日,腾讯在人工智能、生命科学跨学科应用领域的最新研究成果《scBERT as a Large-scale Pretrained Deep Language Model for Cell Type Annotation of Single-cell RNA-seq Data》(《基于大规模预训练语言模型的单细胞转录组细胞类型注释算法》),登上了国际顶级学术期刊《Nature》子刊《Nature Machine Intelligence》。
腾讯在论文中创新性地提出关于单细胞注释的「scBERT」算法模型,受到评审高度认可。专家表示,该成果对于单细胞转录组测序数据分析领域未来研究具有深远意义。
单细胞测序技术是生命科学领域的一项革命性技术。可以细粒度地观察和刻画各个物种中组织、器官和有机体中单细胞分子图谱(细胞表达),便于更好地了解肿瘤微环境,以达到精细分析病因、精准匹配治疗方案的效果,对于「精准医疗」具有极高的应用价值。
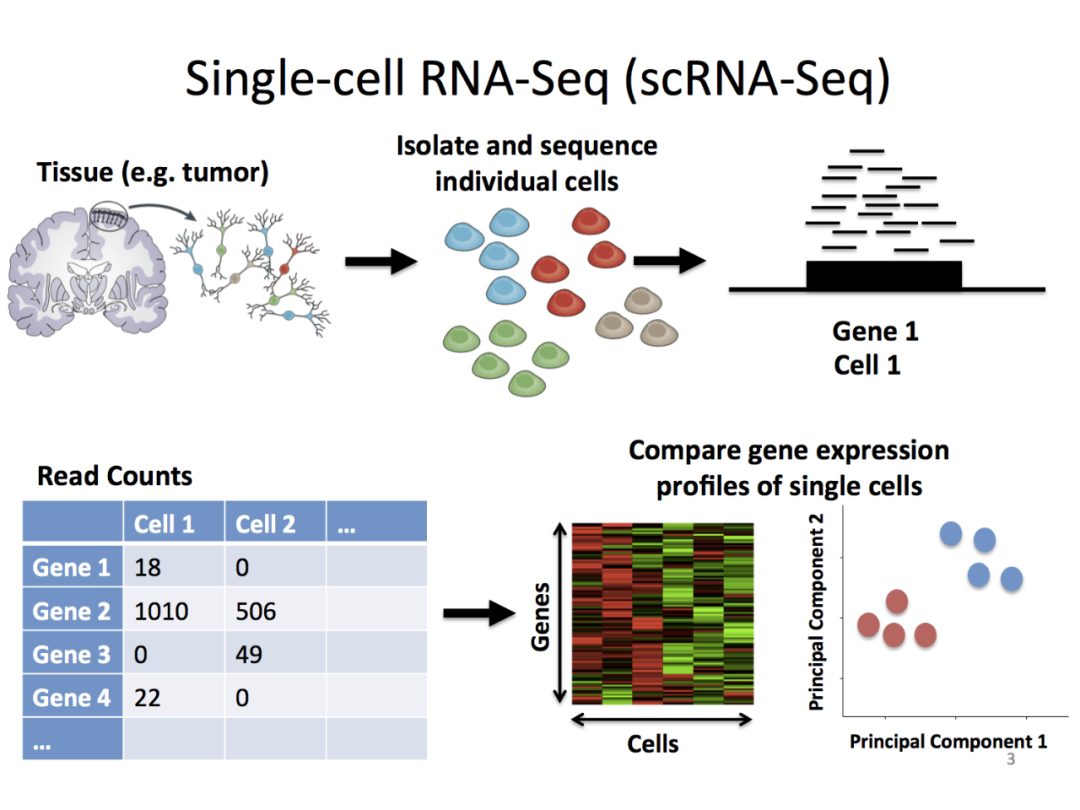
值得注意的是,受数据样本量小、人工干预多、过度依赖 marker gene(已报道的特异性基因)等因素的影响,单细胞测序细胞类型注释技术一直面临着泛化性、可解释性、稳定性均比较低的问题,现存的算法难以有更广泛的应用。
针对以上问题,新研究首次提出「基于大规模预训练语言模型的单细胞转录组细胞类型注释算法」,即「scBERT」模型,首次将「transformer」(自然语言处理算法经典计算单元)运用到单细胞转录组测序数据分析领域。该模型基于 BERT 范式,将细胞中基因的表达信息转化成可被计算机理解、学习的「语言」,并对细胞进行精准标注。
BERT 在 NLP 领域革命性地应用了自监督预训练 - 微调的范式:通过 Transformer 为基本单元构成的大规模语言模型在海量文本数据上学习通用的语言知识,随后将该模型迁移至不同下游任务中,对模型参数进行微调,建立准确、高性能的模型。该方法在 NLP 领域取得广泛的成功。
类似的,单细胞转录组也可以抽象为每个细胞内部基因转录的语言(表达谱),其中不同的基因之间存在共表达或者差异表达的模式,也可以理解为转录的语法(基因相互作用),类比于不同单词在一个句子里的关联关系。
当前的单细胞转录分析方法,由于引入大量人工操作而倾向于过拟合,易受批次效应影响降低泛化性。腾讯等机构提出的方法充分利用大规模公开无标注的数据集,使得模型在预训练时见过不同来源、不同组织和不同测序技术的单细胞数据,更倾向于学到跨数据集、跨批次和跨组织的单细胞表达通用知识。
如果能将这种通用知识迁移给下游特定任务,则可以降低对下游任务精标注数据的依赖,通过微调少量参数即可获得较为准确的模型。并且在多种组织和样本中具有较强的泛化性。
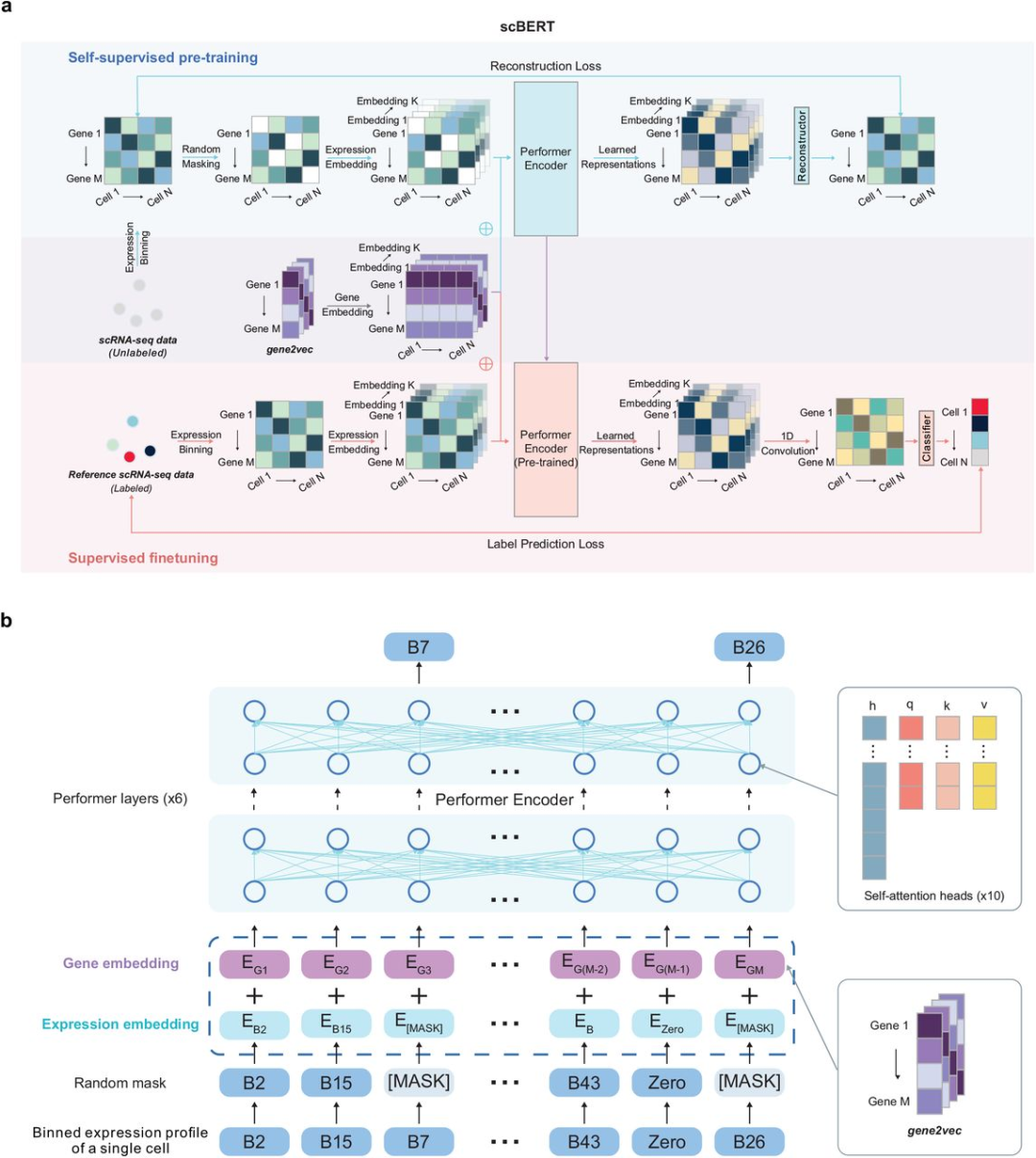
在模型中,针对单细胞测序数据特点,研究人员提出了 gene embedding 和 expression embedding,把每个单细胞表达谱特异性转化为模型的输入。在自监督预训练阶段,模型通过随机对非零表达值进行 mask,随后通过基于 Performer 的编码器编码,将输出结果与未 mask 的模型输入计算重构损失。
训练过程中,预训练好的模型参数被用于微调任务中模型相应参数的初始化,从而把大规模自监督学习到的单细胞表达通用知识传递给下游任务。在下游任务中,编码器输出传递给细胞类型分类器,通过基于少量有类型标签数据的训练,从而微调模型参数,获得精确的细胞类型注释模型。
该方法实现了端到端优化,从原始表达谱出发,仅通过归一化,而不经过其他任何前处理和人工经验筛选基因,以数据驱动的方式建立了整套自动化注释工具。
模型基于 Performer 单元具有强大的表征能力,通过自注意力机制学习到基因和基因之间的相互关系,并且对单细胞整个表达谱进行复杂的整体表征,因此仅仅通过模式识别的方式,而不输入 marker gene 即可取得超越所有 SOTA 算法的效果,并且对于高相似性的亚型也具有良好的识别能力。
模型的自监督预训练对性能具有显著的提升,也降低了后续对精标注数据的依赖。据介绍,腾讯提出的方法全程不经过降维和特征选择,使得全基因组所有基因共同组成的表达谱被模型充分学习,并且可以通过自注意力机制学习到基因之间的相互作用,以及每个基因对预测结果的贡献程度。
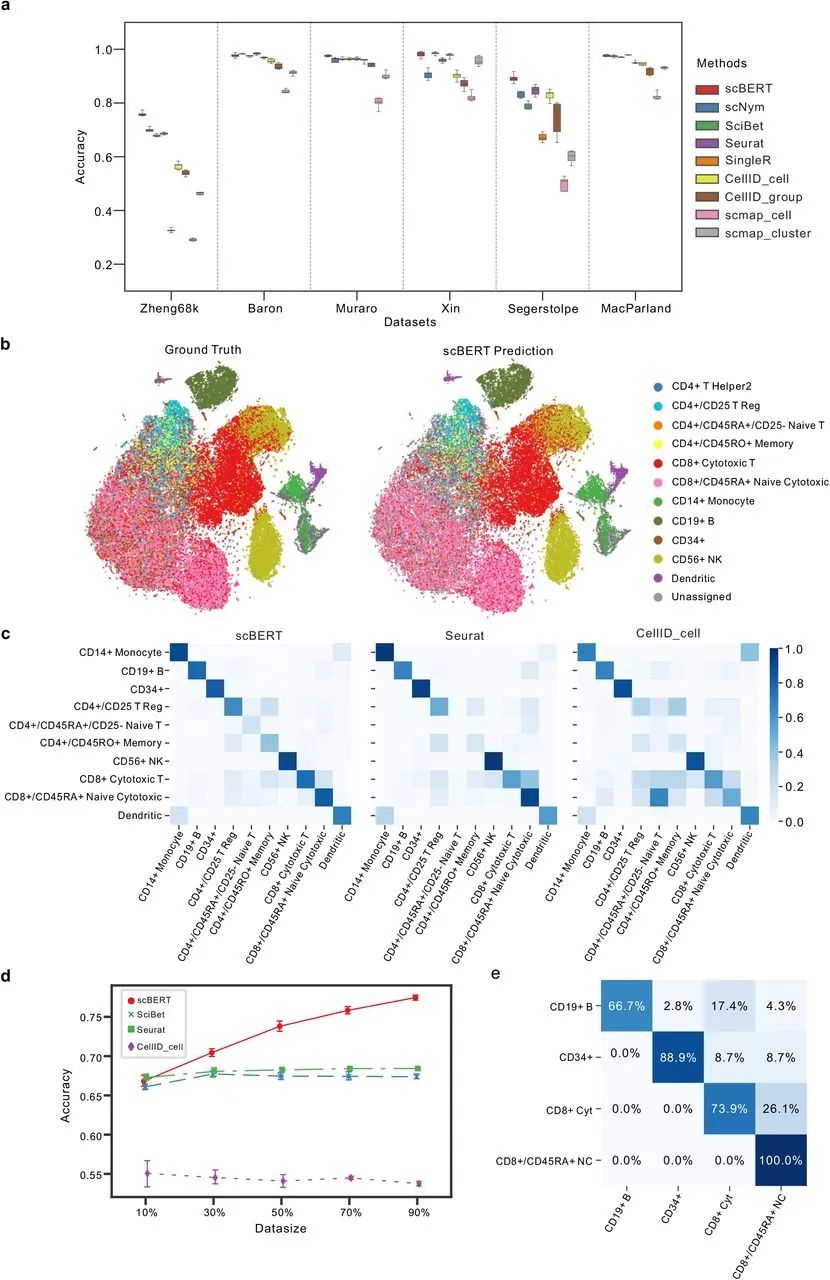
为了保证全基因组内基因级别的可解释性,scBERT 在预训练数据上没有做任何的降维或筛选处理,最大程度上保留数据本身的特性和信息。此外,该模型复用了大规模的公开数据集,包含不同实验来源、批次和组织类型的单细胞数据,以保证模型能学习到更为「通用」的知识,精准捕获单个基因的表达信息及两两基因之间的作用关系。
新模型可以定位到每个细胞的关键基因,富集分析证明了每种细胞类型对应的关键基因确实行使细胞特异性生物学功能。经统计分析和可视化验证,每种细胞类型对应的关键基因确实在该细胞类型中显著表达,其中包含已报道的 marker 基因以及未经报道的 novel marker gene。
从结果上来看,scBERT 实现了高解释性、高泛化性、高稳定性的单细胞类型注释技术。截至目前,通过了 9 个独立数据集、超过 50 万个细胞、覆盖 17 种主要人体器官和主流测序技术组成的大规模 benchmarking 测试数据集上,该算法模型的优越性均得以验证。其中,在极具挑战的外周血细胞亚型细分任务上,相较现有最优方法的 70% 准确度提升了 7%。
单细胞转录组测序技术在 2013 年被 Nature Method 评为 Method of the Year,而单细胞多组学技术 2020 年也被 Nature Method 评委 Method of the Year。单细胞 RNA 测序在过去十年中已被证明是生命科学领域的一项革命性技术。通过单细胞 RNA 测序可以以前所未有的粒度观察和刻画各个物种中组织、器官和有机体中单细胞分子图谱,对于探索生命的奥秘和数字化生命具有重要作用。
在应用价值层面,该技术能给细胞中的每个基因都印上专属「身份证」,用于临床单细胞测序数据,并辅助医生描述准确的肿瘤微环境、检测出微量癌细胞,从而实现个性化治疗方案或者癌症早筛。同时,它对疾病致病机制分析、耐药性、药物靶点发现、预后分析、免疫疗法设计等领域都具有极其重要的作用。
据了解,《Nature Machine Intelligence》只关注对该领域具有重要影响的科研成果。因其严格的评审标准,每年收录论文数量平均仅 60 篇左右。目前该期刊在计算机科学 - 人工智能领域和跨学科应用领域影响因子排名第一(IF: 25.898)。
此前,腾讯 AI Lab 团队科研成果曾多次入选《Nature Communications》、ACL-IJCNLP 等国际权威期刊,实验室强调研究与应用并重发展。未来,腾讯会继续基于自身先进 AI 技术的积累,与下游临床、制药和生命科学基础研究领域进行密切合作,为行业贡献更多价值。
未来,腾讯会继续基于自身先进 AI 技术的积累,与下游临床、制药和生命科学基础研究领域进行密切合作,为行业贡献更多价值。
参考链接:
https://www.biorxiv.org/content/10.1101/2021.12.05.471261v3

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com


