Airbnb 如何实现 Kubernetes 集群动态扩展

本文最初发布于 Airbnb 技术博客。
运营 Airbnb 基础设施的一项重要工作是,确保我们的云开支随着需求自动增长和下降。我们的流量每天波动很大,为此,我们的云资源占用应该能够动态扩展。
为了实现这种扩展,Airbnb 利用了 Kubernetes 这个开源的容器编排系统。我们还利用了 OneTouch,一个建立在 Kubernetes 之上的服务配置界面,在之前的 文章 中有更详细的描述。
在这篇文章中,我们将讨论如何使用 Kubernetes Cluster Autoscaler 动态调整集群大小,并重点介绍我们为 sig-autoscaling 社区 贡献的特性。这些改进增加了可定制性和灵活性,满足了 Airbnb 独特的业务需求。
在过去几年里,Airbnb 已经将几乎所有的在线服务从手工编排的 EC2 实例迁移到 Kubernetes。如今,我们在近百个集群中运行着数千个节点以适应我们的工作负载。然而,这种变化不是一夜之间发生的。在迁移过程中,随着更多的工作负载和流量转移到新技术栈,底层 Kubernetes 集群的配置得到了优化,也变得更加复杂。这种演变可以分为三个阶段:
阶段 1:同构集群,手动扩展
阶段 2:多集群类型,独立自动扩展
阶段 3:异构集群,自动扩展
在使用 Kubernetes 之前,服务的每个实例都运行在自己的机器上,当流量增加时需要手动扩展。每个团队的容量管理方式不一样,负载下降时,已分配的容量也很少会取消。
我们最初的 Kubernetes 集群设置相对简单。我们有少数几个集群,每个集群都有一个底层节点类型和配置,它们只运行无状态的在线服务。随着其中一些服务开始迁移到 Kubernetes,我们开始在多租户环境中运行容器化服务(一个节点上有许多 pod)。这种聚合减少了资源浪费,并将服务的容量管理整合到了 Kuberentes 控制平面上。在这个阶段,集群扩展是手动的,但相比之前仍然有显著的改进。

图 1:EC2 节点 vs Kubernetes 节点
集群配置的第二个阶段始于我们试图在 Kubernetes 上运行更多不同类型的工作负载,每个类型都有不同的需求。为了满足这些需求,我们创建了一个集群类型抽象。“集群类型”定义了集群的底层配置,集群类型相同的集群从节点类型到各种集群组件设置都相同。
集群类型越多集群也越多,我们的初始策略“手动管理每个集群的容量”很快就支撑不下去了。为了解决这个问题,我们在每个集群中添加了 Kubernetes Cluster Autoscaler。该组件根据 pod 请求自动调整集群大小——如果集群的容量耗尽了,就可以通过添加一个新节点来满足待处理的 pod 请求,此时,Cluster Autoscaler 就会启动一个节点。类似地,如果集群中有节点在很长一段时间内未得到充分利用,那么 Cluster Autoscaler 将从集群中删除这些节点。在我们的设置中,添加这个组件非常有效,为我们省却了大约 5% 的云开销,以及手动扩展集群的操作开销。

图 2:Kubernetes 集群类型
当 Airbnb 几乎所有的在线计算都转向 Kubernetes 时,集群类型的数量已经增加到 30 多个,而集群的数量则达到 100 多个。这种扩张使得 Kubernetes 集群管理变得非常繁琐。例如,集群的升级必须针对众多集群类型中的每一种单独进行测试。
在第三阶段,我们的目标是通过创建“异构”集群来整合集群类型。这些集群可以在一个 Kubernetes 控制平面上容纳许多不同的工作负载。首先,这大大降低了集群管理的开销,因为数量更少更通用的集群可以减少需要测试的配置数量。其次,现在 Airbnb 大部分都在 Kubernetes 集群上运行,集群效率为降低成本提供了一个重要杠杆。整合集群类型使我们能够在每个集群中运行不同的工作负载。工作负载类型聚合——有大有小——可以实现更好的装箱(bin packing)和效率,从而提高利用率。得益于工作负载的这种灵活性,我们有更多的空间在 Cluster Autoscaler 默认的扩展逻辑之外实施复杂的扩展策略。具体来说,我们的目标是实现与 Airbnb 具体业务逻辑相关的扩展逻辑。
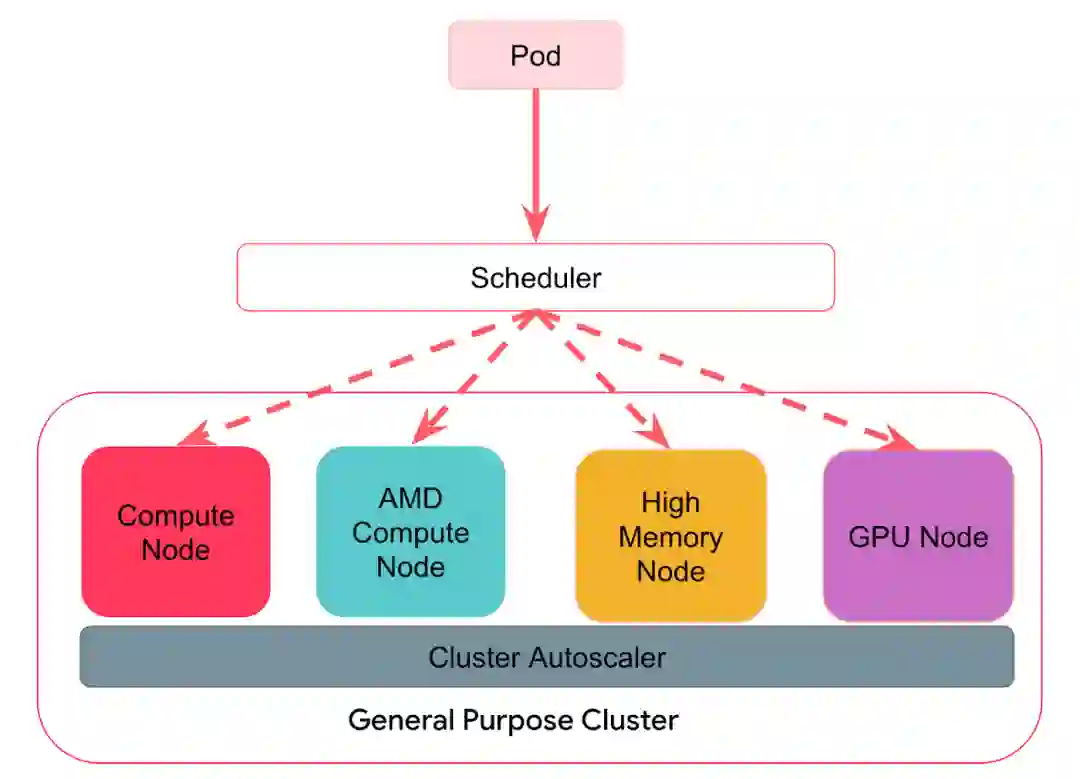
图 3:异构 Kubernetes 集群
随着我们对集群进行扩展和整合(实现异构集群,每个集群有多个实例类型),我们开始在扩展过程中实现特定的业务逻辑,并发现有必要对自动扩展行为做一些修改。下一节将描述我们对 Cluster Autoscaler 所做的一些改进,目的是使其更加灵活。
我们对 Cluster Autoscaler 所做的最重要的改进是提供了一种新的方法来确定要扩展的节点组。在内部,Cluster Autoscaler 维护着一个节点组列表(它们映射到不同的候选扩展),它会针对当前的 Pending(不可调度)pod 集进行调度模拟,过滤出不满足 pod 调度需求的节点组。如果有任何 Pending(不可调度)pod,Cluster Autoscaler 会尝试扩展集群以容纳这些 pod。任何满足所有 pod 需求的节点组都会被传递给一个名为 Expander 的组件。
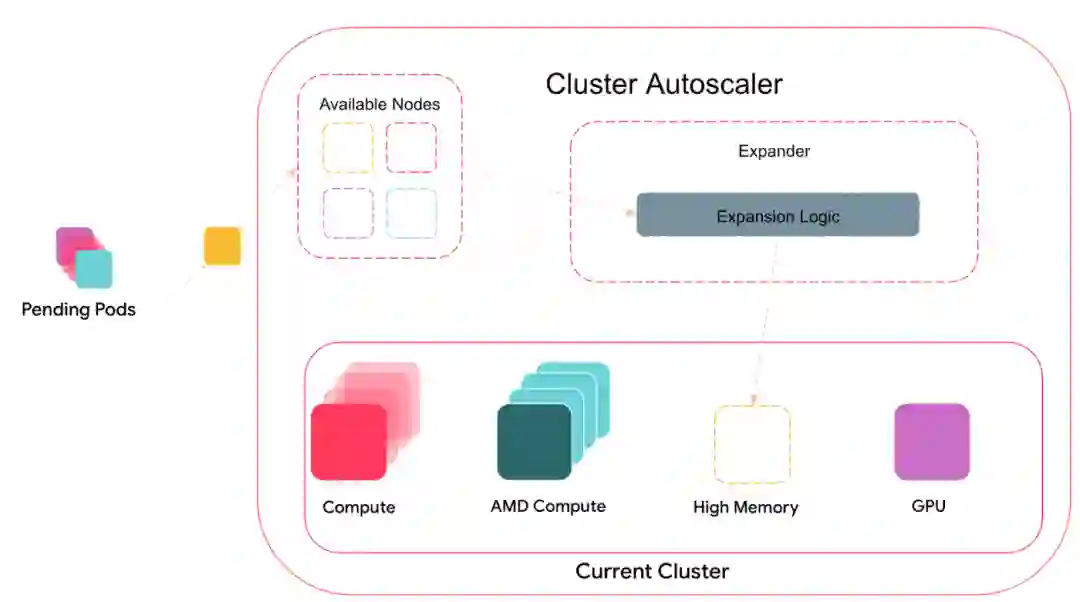
图 4:Cluster Autoscaler 和 Expander
Expander 负责根据操作要求进一步过滤节点组。Cluster Autoscaler 内置了许多不同的扩展器选项,每个选项都有不同的逻辑。例如,默认是随机扩展器,它从可用的选项中机会均等地随机选择。另一个选项,也是 Airbnb 历来使用的选项,是 优先级扩展器,它根据用户指定的分层优先级列表选择要扩展的节点组。
随着我们迈向异构集群逻辑,我们发现默认的扩展器不够成熟,无法满足我们以成本和实例类型选择为中心的更复杂的业务需求。
假如有这样一个情况,我们想实现一个加权优先级扩展器。目前,优先级扩展器只允许用户指定节点组的不同层级,这意味着它将始终以确定的方式按顺序扩展层级。如果一个层中有多个节点组,它将随机选择。在默认设置下,无法实现将两个节点组置于在同一层级的加权优先策略,在 80% 的时间内扩展一个,在 20% 的时间内扩展另一个。
除了目前支持的扩展器存在局限性之外,还有一些操作上的考虑:
Cluster Autoscaler 的发布管道非常严格,变更需要时间审核,然后再合并到上游。然而,我们的业务逻辑和所需的扩展策略在不断变化。开发一个今天可以满足需求的扩展器,可能无法满足我们未来的需求。
我们的业务逻辑是特定于 Airbnb 的,其他用户未必如此。任何我们针对自己的逻辑所做的修改,都不会对上游有什么贡献。
为此,我们希望 Cluster Autoscaler 中有一个新扩展器类型可以满足下列要求:
我们希望能有一个既可扩展又能为他人所用的东西。其他人在大规模使用默认的 Expander 时可能会遇到类似的限制,我们希望提供一个通用的解决方案,并向上游贡献功能。
我们的解决方案应该可以与 Cluster Autoscaler 一起部署,并允许我们更迅速地响应不断变化的业务需求。
我们的解决方案应该适合 Kubernetes Cluster Autoscaler 生态系统,这样我们就不必无限期地维护 Cluster Autoscaler 的一个分叉。
基于这些要求,我们提出了一个设计,将扩展职责从 Cluster Autoscaler 的核心逻辑中分离出来。我们设计了一个可插拔的“自定义扩展器”,它被实现为一个 gRPC 客户端(类似于 自定义云提供商)。这个自定义扩展器由两个部分组成。
第一个组件是一个内置于 Cluster Autoscaler 的 gRPC 客户端。这个 Expander 使用了与 Cluster Autoscaler 中其他 Expander 相同的接口,负责将 Cluster Autoscaler 中有效的节点组信息转换为定义好的 protobuf 模式(如下图所示),并接收 gRPC 服务器的输出,变回最终的选项列表,供 Cluster Autoscaler 扩展。
service Expander {rpc BestOptions (BestOptionsRequest) returns (BestOptionsResponse)}message BestOptionsRequest {repeated Option options;map<string, k8s.io.api.core.v1.Node> nodeInfoMap;}message BestOptionsResponse {repeated Option options;}message Option {// ID of node to uniquely identify the nodeGroupstring nodeGroupId;int32 nodeCount;string debug;repeated k8s.io.api.core.v1.Pod pod;}
第二个组件是 gRPC 服务器,这需要由用户自己编写。这个服务器的用意是作为一个单独的应用程序或服务来运行,在选择要扩展的节点组时,可以使用从客户端传过来的特定信息运行任意复杂的扩展逻辑。目前,通过 gRPC 传递的 protobuf 信息基于传递给 Cluster Autoscaler 中的 Expander 的信息稍微做了些转换。
从我们前面提到的例子来看,加权随机优先级扩展器的实现可以很简单,让服务器从优先级层级列表和配置图中读取加权百分比配置并作出相应的选择即可。

图 5:Cluster Autoscaler 和自定义 gRPC Expander
我们的实现包括一个故障安全选项。建议使用该选项,将 多个扩展器 作为参数传递给 Cluster Autoscaler。有了这个选项,如果服务器发生故障,Cluster Autoscaler 仍然能够使用后备扩展器进行扩展。
由于是作为一个独立的应用程序运行,扩展逻辑可以在 Cluster Autoscaler 之外开发。而且,由于 gRPC 服务器可以由用户根据自己的需要进行定制开发,所以这个解决方案也是可扩展的,对整个社区都很有用。
在内部,自 2022 年初开始,Airbnb 一直在使用这个新的解决方案来扩展我们所有的集群,没有任何问题。它使我们能够动态选择何时扩展某些节点组,以满足 Airbnb 的业务需求,实现了我们开发可扩展的自定义扩展器的最初目标。
在今年早些时候,我们的自定义扩展器 被上游的 Cluster Autoscaler 所接受,并将在下一个版本(v1.24.0)发布时推出。
在迁移到异构 Kubernetes 集群的过程中,我们发现了其他一些 Bug 以及 Cluster Autoscaler 的可改进之处。下面简要介绍一下这些情况:
提前中止没有容量的 AWS ASG:缩短 Cluster Autoscaler 调用 AWS EC2 端点来检查 ASG 是否有容量,进而判断它们试图扩展的节点是否准备就绪的等待时间。实现这一修改后,用户可以更快地实现准确扩展。以前,使用优先级的用户必须在每次尝试启动 ASG 之后等待 15 分钟,再尝试低优先级的 ASG。
缓存启动模板,减少 AWS API 调用:为 AWS ASG 启动模板引入缓存。这一修改让我们可以使用大量的 ASG,这对我们的广义集群策略至关重要。以前,对于空的 ASG(集群中当前没节点),Cluster Autoscaler 会反复调用 AWS 端点来获取启动模板,导致 AWS API 限流。
在过去的四年里,Airbnb 在 Kubernetes 集群配置上取得了长足的进步。将 Airbnb 最大的计算部分置于单个平台上,为提高效率提供了一个强有力的杠杆。现在,我们正专注于一般化我们的集群设置(考虑下“Cattle 而非 Pets”)。通过在 Cluster Autoscaler 中开发和使用更复杂的扩展器(以及修复 Autoscaler 的其他一些小问题),我们已经实现目标,以成本和混合实例类型为中心开发出特定于业务的复杂扩展策略,同时也为社区贡献了一些有用的特性。
要了解更多关于我们异构集群迁移的细节,请观看我们的 Kube-Con 演讲。今年,我们也会参加 KubeCon EU,欢迎来和我们交流!
查看英文原文:
https://www.infoq.cn/link?target=https%3A%2F%2Fmedium.com%2Fairbnb-engineering%2Fdynamic-kubernetes-cluster-scaling-at-airbnb-d79ae3afa132%3FaccessToken%3DeyJhbGciOiJIUzI1NiIsImtpZCI6ImRlZmF1bHQiLCJ0eXAiOiJKV1QifQ.eyJhdWQiOiJhY2Nlc3NfcmVzb3VyY2UiLCJleHAiOjE2NTQ5NDk4MTAsImZpbGVHVUlEIjoic1VVRnNhUEN3Tm9JMG93YyIsImlhdCI6MTY1NDk0OTUxMCwidXNlcklkIjo1MDA3OTEyfQ.OnBZWDBjAK4WxfHykQj5xEPw9I5O7XHxhG3hmNYcc0Q
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
河南赋红码事件程序员不背锅;马斯克:向TikTok和微信学习;华为宣布将调整绩效考核指标 | Q资讯

点个在看少个 bug 👇


