专访 | 文因互联:从「金融数据」到「金融知识」
机器之心原创
作者:邱陆陆
存储了一份财务报表的计算机存下了一条「数据」,而持有这份财务报表的分析师拥有了一份「信息」。其间的区别是,分析师可以通过阅读财务报表得到相关的「知识」并依此作出投资决策。
存储了三万份财务报表的计算机同样存下了三万条「数据」,而持有三万份财务报表的分析师却不再拥有三万份「信息」。原因十分简单:计算机的内存是线性的,人的处理分析能力却不是——即使有三万份报表摆在我的眼前,我也只能眼睁睁看着其中的大部分停留在「数据」的状态无能为力。
除非……计算机可以帮助我吗?哪怕我们并不说同一种语言,计算机并不能「理解」人类所谓的语义是什么。只要它把数据按照一定规则、以一种人类能理解的方式进行组织,我们是否也可以从三万份「数据」里获得等量的「信息」与「知识」?
这就是文因互联希望完成的工作:对纷繁复杂的数据进行处理,归纳总结出金融知识和逻辑,辅助解决各种金融场景下的问题。
承担这样的转换工作的,是文因研发数百个能力模块。有从非结构化数据提取结构化信息点的模块,能够通过自然语言理解技术把 pdf、word 格式的报告、研报、新闻,转换结构化信息;也有利用知识图谱技术对信息进行融合、归纳与演绎的模块;也有利用自然语言生成与摘要技术转换信息形式的模块。如何把用户的需求拆解成算法可解决的问题?又用什么样的方法解决它们?其中会遇到哪些困难?文因互联的首席科学家郑锦光博士以及主任科学家马建强,向机器之心详细地介绍了这一过程。
从「机器自然语言」与「人类自然语言」到机器和人都能够理解的「知识图谱」
文因的知识图谱生成技术,完成的是从自然语言的报告到结构化数据,再从结构化数据生成知识图谱的工作。其中既需要处理大段的人类自然语言描述,也需要对大量的描述视觉元素的「机器自然语言」进行提取。
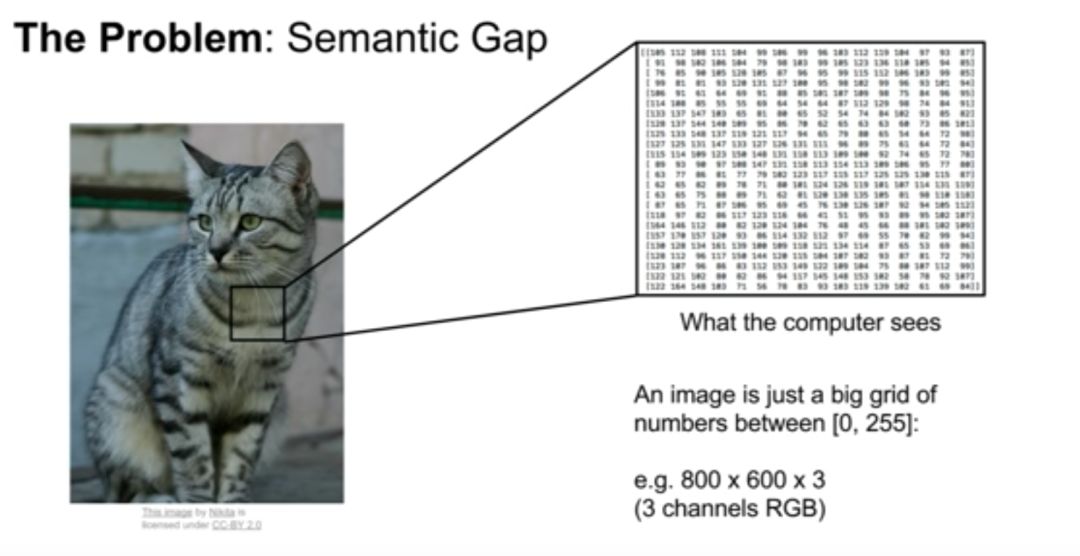
从文本到结构化数据的能力模块进行的是多种常见的自然语言处理(NLP)任务。这些任务包括单独的信息点抽取问题,关注报告中包含的公司基本信息,例如公司名称、高管名字、行业描述等。财务报告的复杂性除了体现在多样的人类自然语言表达上,也体现在展示形式的多样上——财务报告从来不是纯文本,其中还包含着大量用「机器自然语言」表示的图表,而这一类问题可以与计算机视觉问题做类比。
当计算机「看着」一张猫的图像时,它看不到猫这个概念,而只是看着一个庞大的、充满数字的矩阵。因此计算机视觉任务就是弥补「猫这个概念」与「猫所对应的庞大矩阵」之间的语义鸿沟。这个任务的难点在于,一些对图像非常微小的调整,就能给矩阵带来巨大的改变:比如,如果我们把猫的图像整体向左平移一个像素,这个对人类来说细小到肉眼无法识别的变化,对机器来说是天翻地覆的:矩阵里所有的数值都改变了,但是它仍然代表同一只猫?
类似地,pdf 文档表示的只是字符的位置信息,并没有字符相互之间的布局信息。例如当计算机「看着」一份 pdf 格式的报表时,它眼中的「表格」和人眼中的完全不同。在报告的阅读者眼里毫无区别的两条表格里的横线,可能是由完全不同的机器语言「翻译」而成的。一条可能是「把这个含有横线的小图片平铺 10 次」,另一条可能是「用黑色占满从坐标 1 到坐标 2 的空间」,这样的表达还可能有几百种。

文因开发了一个专门的能力模块来解决表格提取问题,这个模块能够识别文档中几百种用来表达表格的「机器自然语言」,从视觉角度还原文档的篇章结构与上下文信息,最终生成统一的结构化数据。
生成结构化数据后,通过对不同文本中描述的实体、关系与指标进行对齐,就可以构建相应的知识图谱。而实体识别、关系发现与指标对齐等一直是自然语言处理领域中获得较多关注的问题:比如如何判断 A 公司的董事长「王石」和 B 公司的股东「王石」是否为同一个人?这需要对其简历与相关信息做深入分析与比对。又比如财务数据中「其他流动资产」和「流动资产其他项目」、「归属于母公司股东的净利润」和「归属于上市公司所有者的净利润」都是表达方式不同的同一个指标。
郑锦光提到,文因的数据库里,已经提取了超过一万七千条上市公司信息、超过三十七万多条高管信息以及超过四万条业务与产品描述。还有成对、成组出现的信息变动分析问题:从海量的文本里,找出分析师可能关心的三百余个财务指标是否出现变动、变动趋势以及变动原因。
人工智能领域的黑猫和白猫
在机器学习的领域里,解决不同问题的思路常常是相同的,然而解决同一个问题的路径又是多样的,究竟哪一种模型最合适,是一个因任务类型而异、因数据量而异、也因需求的精度与效率而异的问题。在文因的系统里,我们经常能看到同样一个任务在不同的场景下采用不同的模型情况,「黑猫白猫,抓到老鼠就是好猫。」
比如说同样是关系抽取,采用的方法可能是基于统计学习的,也可能是基于规则的,甚至还可能是二者结合的。
在冷启动阶段,基于规则的方法「发现」了众多实体之间的关系类型,并且为每个关系类型积累了大量实例。然后机器学习的方法把不同实例之中暗含的抽象关系学习出来,再投入更多的数据之中。最后,在成熟阶段,规则系统和机器学习系统相互配合,相辅相成地共同完成关系抽取任务。
为什么有了大量数据之后,仍然要结合基于规则的系统呢?马建强是这样解释这个问题的,「基于规则的系统虽然因为缺少衡量标准而在学界较少被提起,但在工业界却有广泛的应用。它像是一个小而细密的筛子,虽然能挡住的面积很小而漏掉的很多,但能够确通过的东西一般都是想要的(较高精确率,较低召回率)。相比之下,基于学习的系统更像一张面积大但网眼也更粗的渔网,筛选的范围很大,但捞上来的难免有杂物(较低精确率,较高召回率)。所以业界喜欢将二者结合起来,以达到最佳的效果。」
「每一个问题我们都尝试了许多种模型。」郑锦光表示,「有的方法可能适用于通用数据集,而另外一些方法可能更贴合领域专业数据集。我们有一整套数据收集和校验的体系,积累了大量数据,然后在自己的数据集上尝试了多种多样的方法,以求找到效果最好的那一种。比如在命名实体识别问题上效果最好的是 LSTM + CRF 方法。而在实体消歧上,我们用到了我在博士阶段的研究成果:基于信息熵和语义相似度的消歧。」
这里提到的实体消歧,又是一个结合了多种方法以获得更好效果的例子。信息熵是对于信息量的一种量化方式,例如想要确定一个人的身份,名字提供了一定的信息量,但是因为重名的存在,无法确定其唯一性。身份证号的信息量就非常高,因为它具有唯一性,但是不容易获得。
在财务报表的例子里,一位高级管理人员的名字只提供了有限的信息,但是财务报表里不只有姓名信息,如果把比如「名字+出生日期」或者「名字+工作经历」这样不同的信息进行累积和叠加,逐渐地,身份的唯一性就能够被精确地标识了。进行实体消歧时,就对不同文本中可能重合的实体周围出现的信息进行基于信息熵的语义相似度的计算,完成消歧。
从图谱到产品:除了有分析师一样的知识,还要有分析师一样回答问题的能力,甚至有胜于分析师的回答速度
如果只是单纯地想拥有数据,能回答简单的信息查询问题,那么建立一个数据库以及一个基于检索的问答系统就足够了。之所以用比数据库复杂更多的知识图谱形式进行数据结构化以及问答,就是为了能够将复杂问题的答案也一步到位地呈现在用户面前。
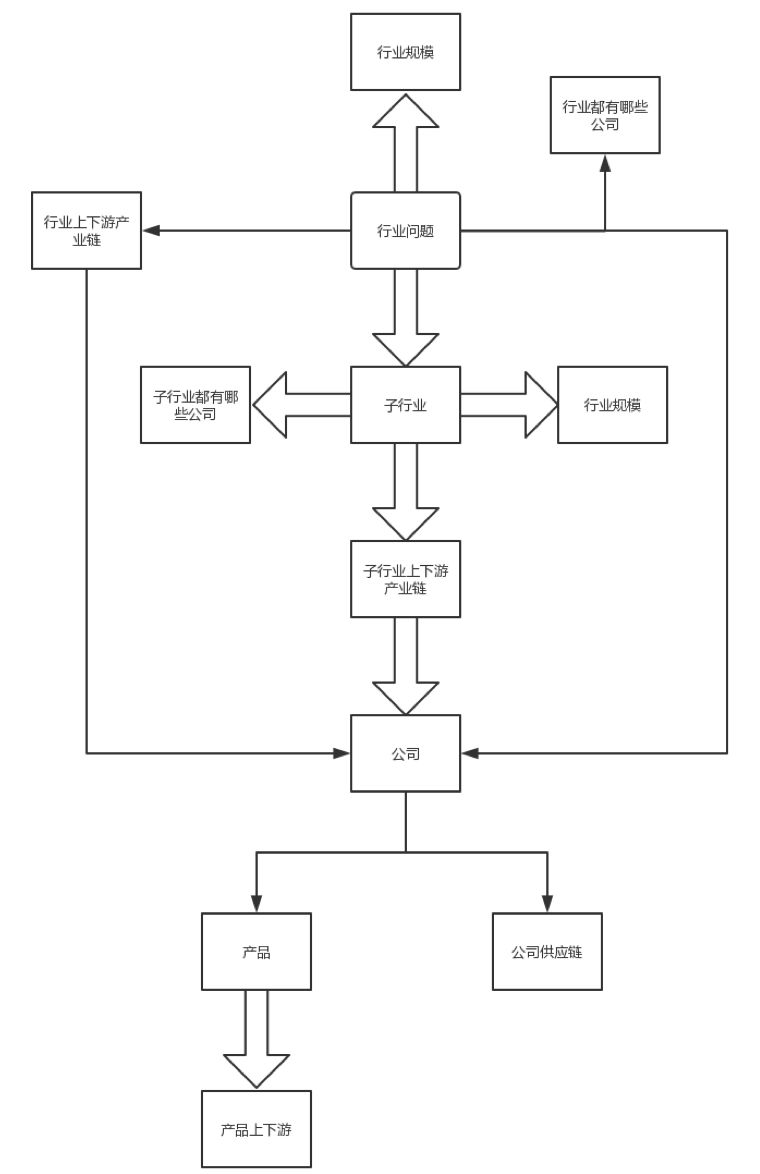
在金融问答场景下,除了事实类问题(比如某公司股价/资本积累率/实际控制人)之外,最常见的还有三类问题:第一类是关于行业里有哪些公司(某公司的相似企业有哪些),第二类是行业规模,第三类是行业的产业上下游。这时,知识图谱方法相较于检索式方法的优势,体现在能够从有复杂条件的问句里提取出多种条件,并从图谱中找到满足条件的「精确」答案。
在文因的智能问答系统里,从用户问出一个自然语言的问题到收到一个自然语言的答案,要经历三个过程:意图识别、查询规划(query planning)以及答案生成。
「意图识别」用到了分词、词性分析(POS tagging)、实体识别、句法分析(syntactic parsing)、语义分析(semantic parsing)等基础的自然语言模块。
在「意图识别」之后,「查询规划」负责生成类似数据库查询语言中的 SQL 语句。这时,只要文因的知识图谱里(包括了行业、子行业、子行业上下游与产业链以及公司实体等多层实体与关系)有相关的信息,获取答案本身就变成了技术相对成熟的数据查询问题。最后,「答案生成」会利用规则与模版进行语言组织来回答相关的问题。
除了封装好的问答系统,企业用户也可以从「文因云」上,自行选择所需的能力模块拼接成所需的产品:
数据咨询公司将「研报搜索」功能融入自己的产品中,能够让其数据产品的用户在搜索研报之外,还具有搜索研报的特定图表和部分区域,这相当于将分析师的工作前置,融入搜索之中;有大量公告发布需求的金融业核心机构,使用「公告摘要」功能,能够快速地得到一份由机器提取关键信息点并按照规定制式组织语言而成的摘要,这是帮助机构员工节省时间与迅速提高效率的手段。
「根据不同场景与服务的需求,模块经过相应的调整与拼装,就能组成有效解决问题的应用,赋能企业用户」,马建强总结道。

本文为机器之心原创,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:editor@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com


