计算机视觉三大会议之——ECCV 2018 观看指南(含大量剧透+24篇论文代码)
极市平台是专业的视觉算法开发和分发平台,加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
计算机视觉三大会议之一的ECCV 2018已于9月8号在德国慕尼黑召开!正会将持续四日,oral & poster 论文将在这段时间轮番展示。本次会议共接收论文779篇,同时在会议上将举行11场tutorials和43场各个领域的workshops。同时优秀的论文还将在会议上进行口头报告,在四天的会议日程中将会有59个orals报告覆盖了从视觉学习、图形摄影、人类感知、立体三维以及识别等各个领域。我们来远程一探究竟吧!

根据网站上公布的论文题目,可以看到今年的研究热点依然围绕学习、网络等研究方式展开,但同时,检测、可视化和视觉方面的研究也占有重要的位置。接下来我们就提前来看看ECCV将为我们带来哪些精彩的研究前沿吧!
Oral
今年ECCV的主论坛将12个不同主题的分论坛分别安排到了10-13号四天的会议时间中,主要包括了视觉学习、计算摄影学、人类分析和感知、三维重建、优化与识别等领域。
视觉学习方向
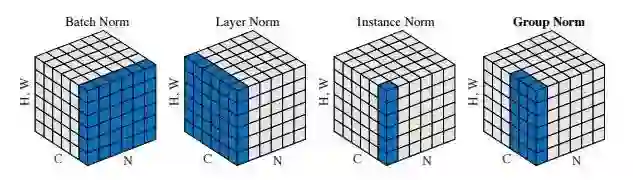
1.来自Facebook的Yuxin Wu和Kaiming提出的Group Normalization来解决Batch Normalizaiton存在的问题,将不同的通道分组归一化实现了优异的表现。
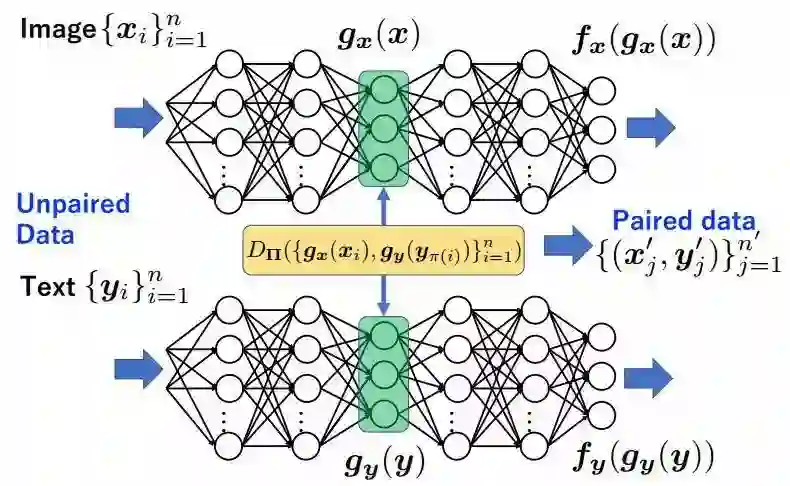
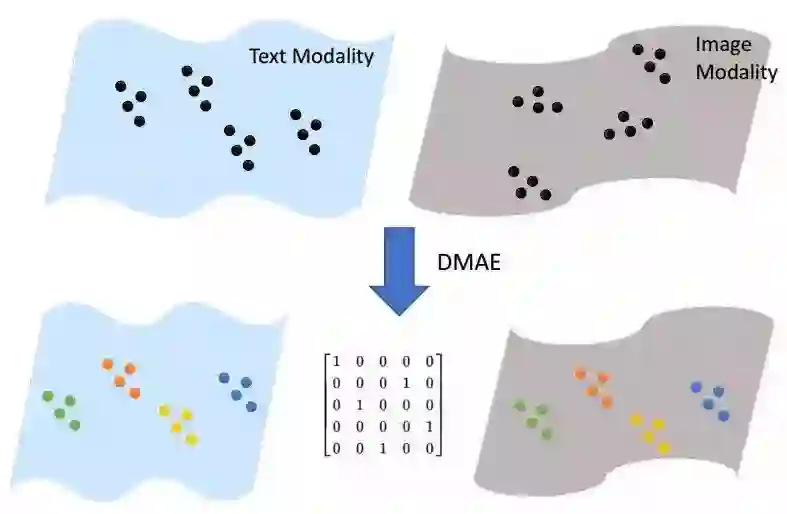
2.还有来自爱丁堡大学和日本理化研究所的研究人员提出的深度匹配自编码器,用于从非配对多模态数据中学习出共有的隐含空间。
3.同时来自约翰霍普金斯大学、斯坦福大学和谷歌联合研究的渐进式神经架构搜索,用于学习神经网络的结构。通过基于序列模型的优化策略实现了高于强化学习和进化算法近五倍的效率和8倍的总体计算提升。并在CIFAR-10和ImageNet上取得了很高的精度。
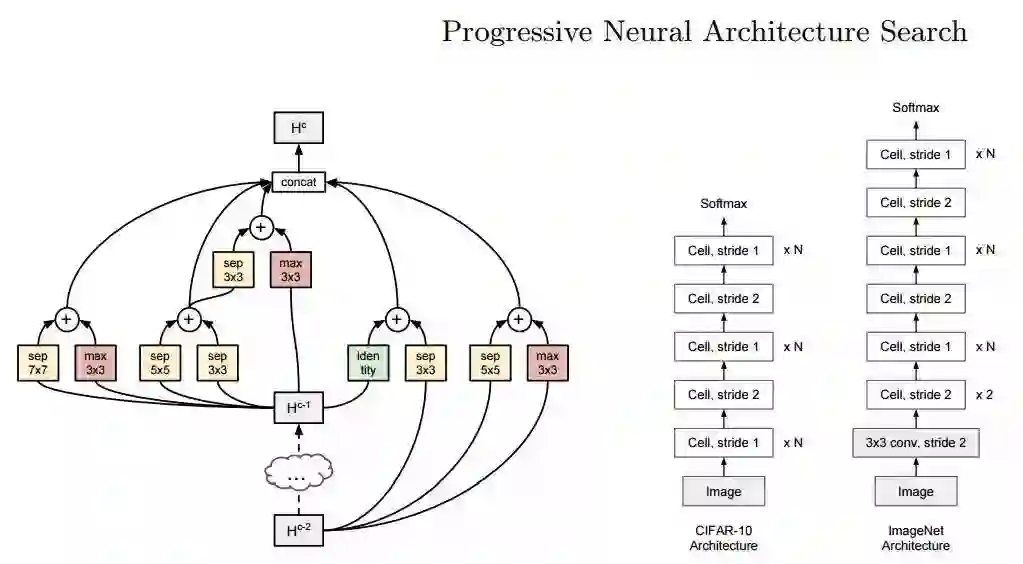
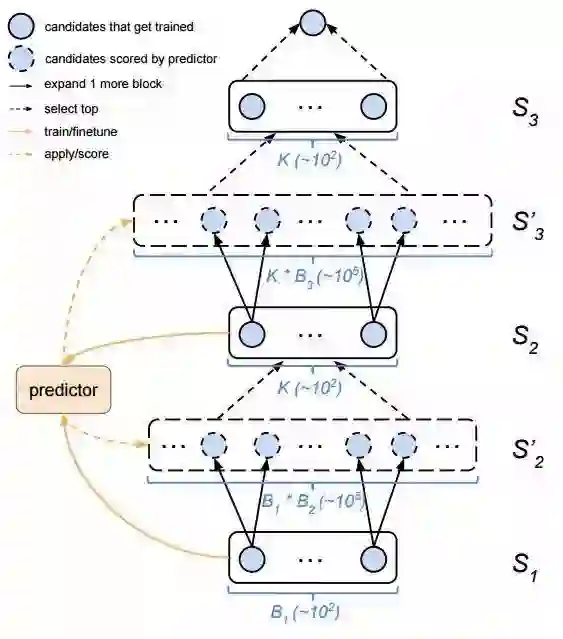
值得一提的是,除了来自于霍普金斯的刘晨曦和谷歌的Zoph外,论文作者还包括李飞飞和李佳等。据报道这篇文章与Neural Architecture Search with Reinforcement Learning和Large Scale Evolution of Image Classifiers等技术一起支撑了谷歌AutoML的发展。
计算摄影学方向
包括了从点光源、光场、可编程器件等研究热点
1.来自慕尼黑工大的研究人员利用相机卷帘快门的特性优化了直接稀疏里程计的后端,实现了近实时的准确VO方法。
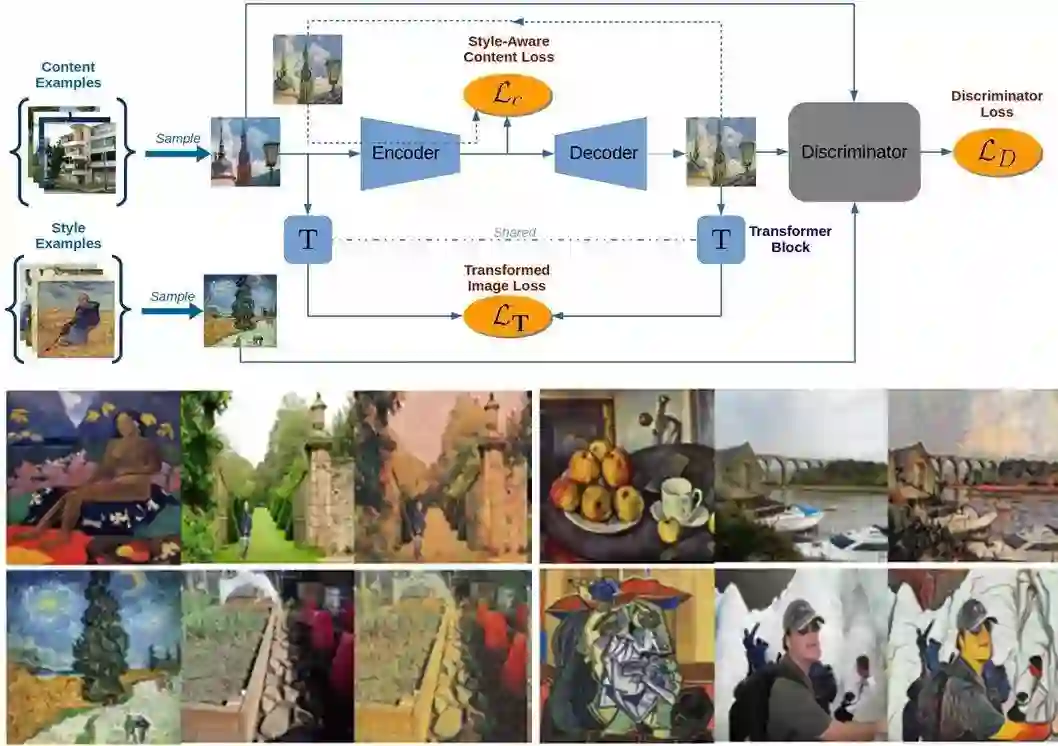
2.来自海德堡大学的研究人员提出了一种基于style-aware content的损失函数并联合自编码器训练出了实时高分辨率的风格迁移模型。使得生产的图像包含了更多更自然的美感。
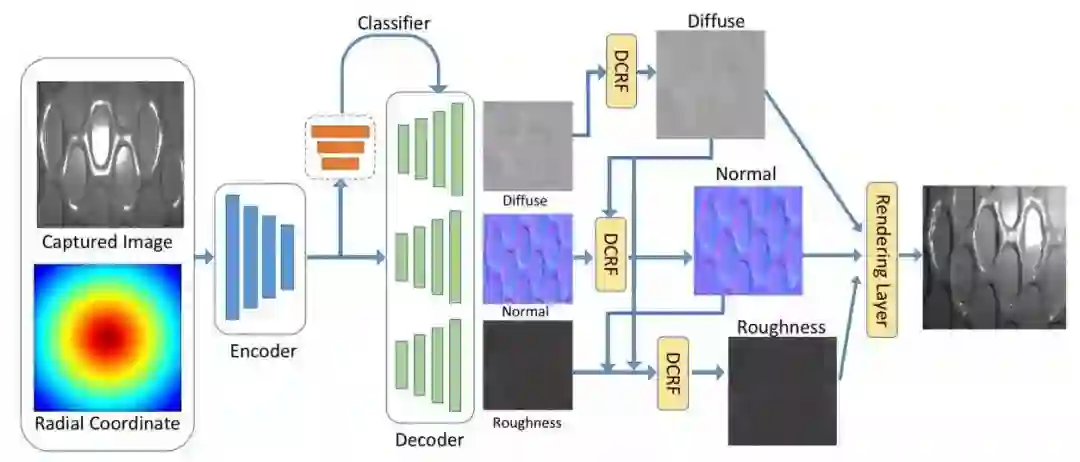
3.来自圣迭戈分校和Adobe的研究人员提出了一种利用单张手机照片获取不同材料表面变化的双边反射率函数,通过神经网络实现了对于SVBRDF的估计,为光度渲染带来了新的可能。
人类行为分析与感知
包括了人体及各部分的姿态估计、人脸人手追踪、行人识别、行为预测等方面。
1.来自布里斯托、卡塔尼亚和多伦多大学的研究人员们给出了一个用于研究人类行为习惯的第一人称数据库EPIC-KITCHENS,这一数据库记录了来自多个国家的参与者在厨房中的第一人称视角,包含了1150万帧图像和3.96万个动作分割与45.34万个bbox。这一数据集将用于第一人称的物体检测、行为识别和行为预测中去。
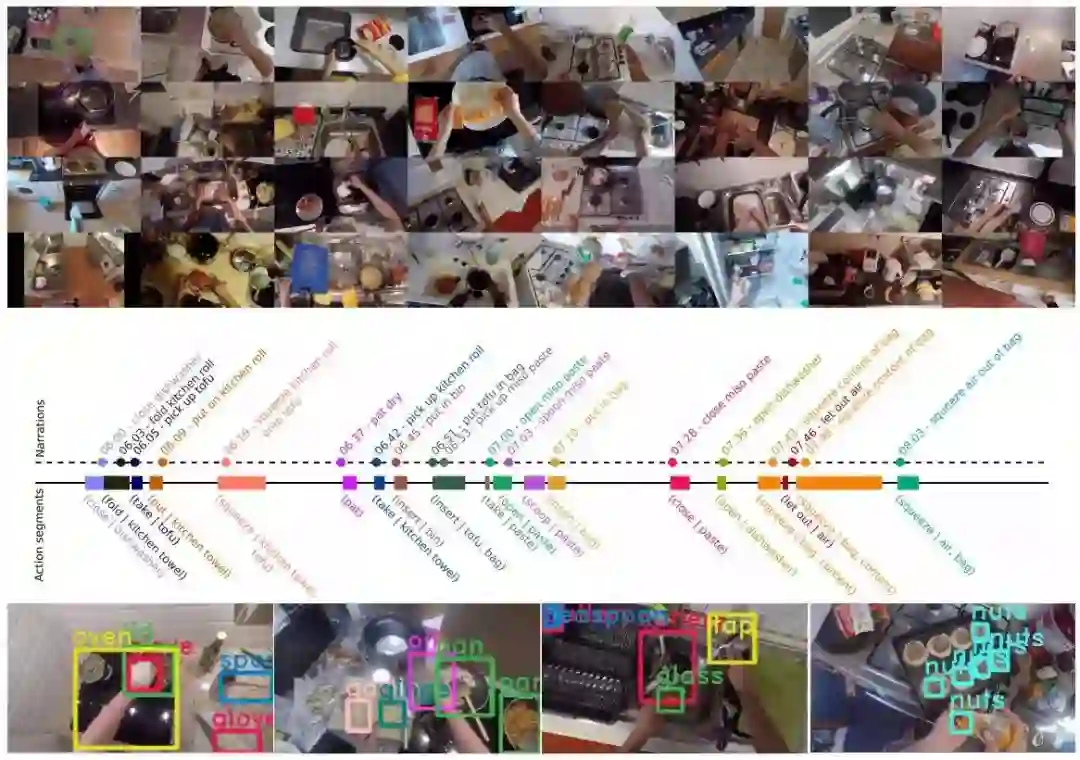
2.同样来自湖南大学和东京大学的研究人员提出了从第一人称视角来预测凝视注意力的模型。
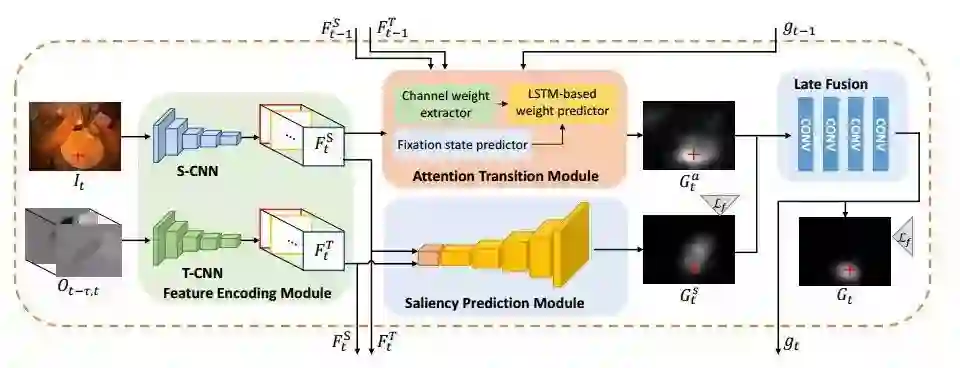
3.来自中山大学、商汤和视源的研究人员们提出了一种通过部分xx网络实现了实例人体分析,通过将实例人体解析任务分解成语义分割和基于边缘检测将语义部件归并到确定人物身上的两个子任务来实现。

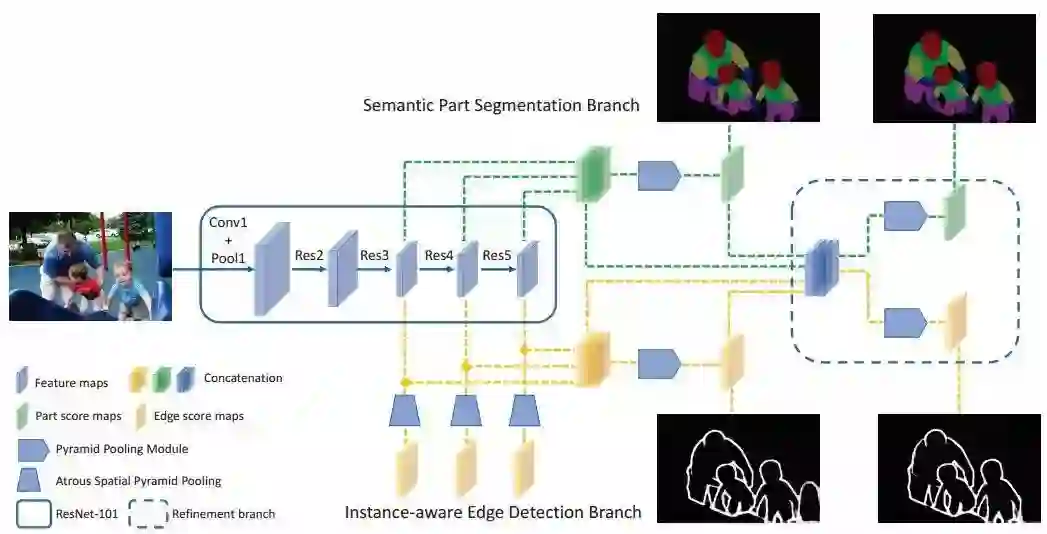
4.来自伯克利的研究人员提出了一种联合视频中图像和声音信息的网络用于融合多传感器的表达,利用自监督的方式训练出了一种可以预测视频帧和音频是否对齐的神经网络,并可用于视频声源定位、音-视识别和音轨分离等任务。

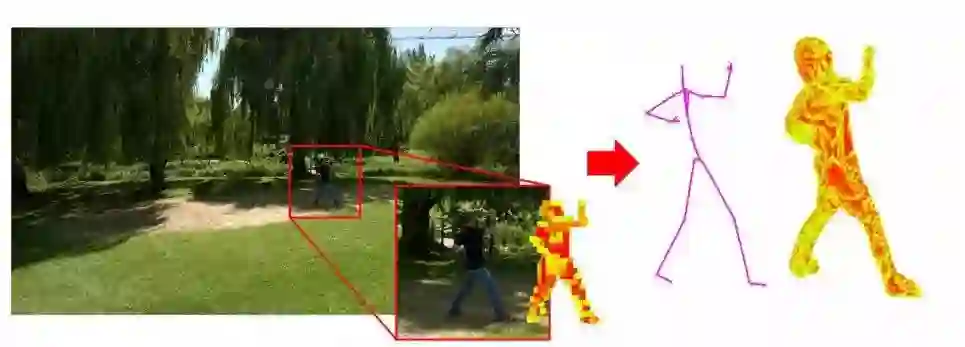
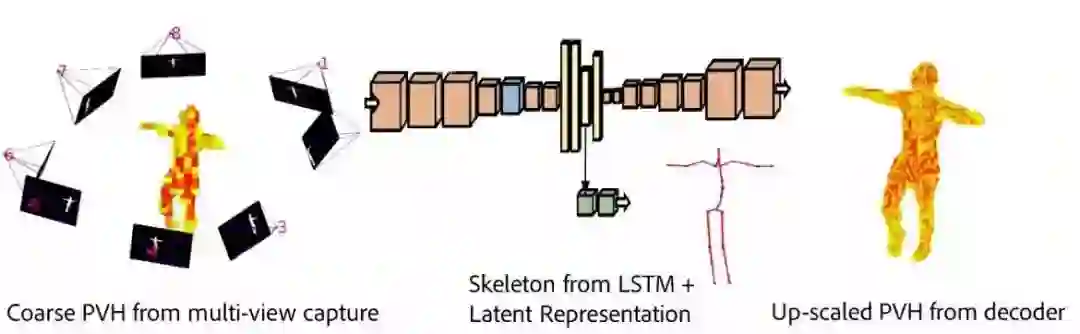
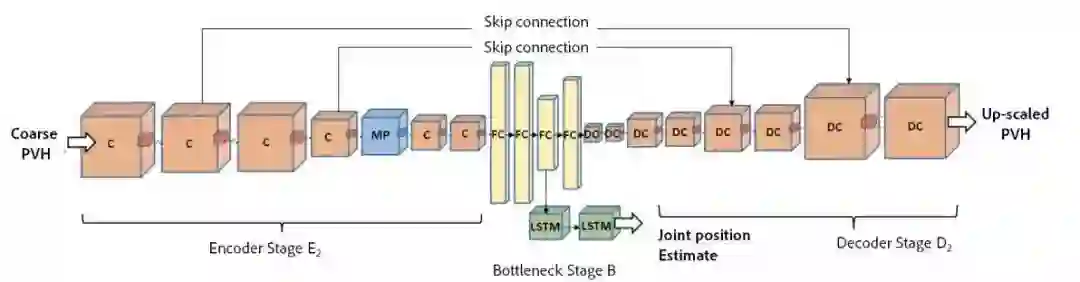
5.萨里大学和adobe的研究人员通过训练对称的卷积自编码器来学习出骨架关节位置的编码和身体的体积表示。能够准确恢复出关节位置的3D估计。
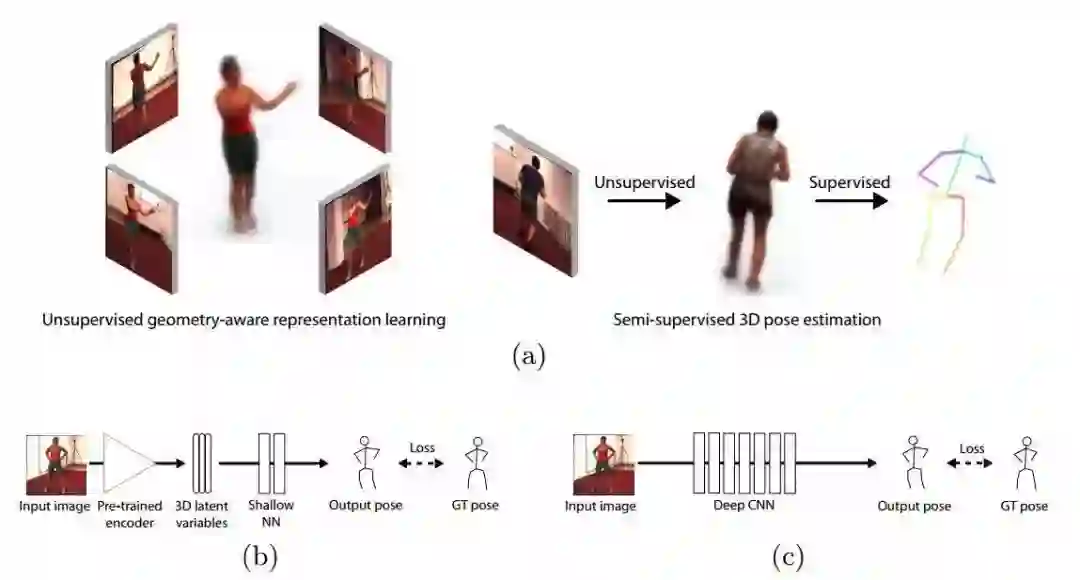
6.来自洛桑理工的研究人员也提出了一种非监督的3D人体姿态估计模型,通过自编码器可以从单一视角的图像预测另一个视角。由于它编码了3D几何表示,研究人员还将它用于半监督学习映射人体姿态。
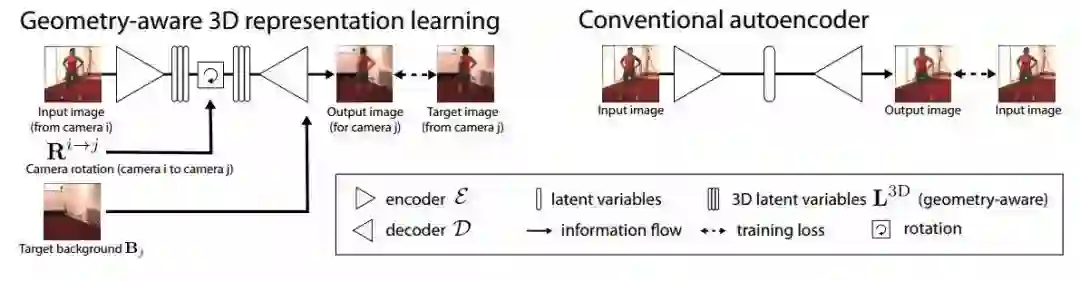

立体视觉三维重建方面
主要研究集中在几何、立体视觉和深度推理等方面。
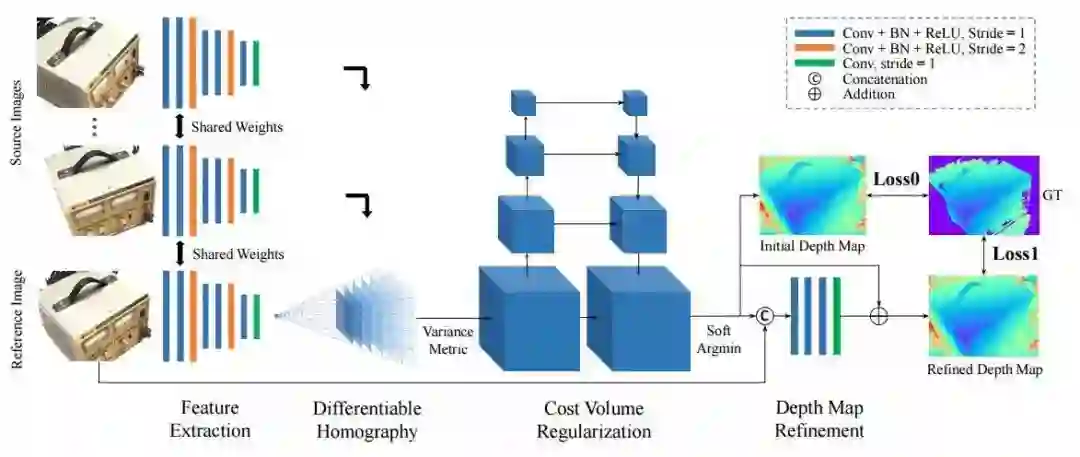
来自香港科技大学的研究人员提出了利用非结构化的图像作为输入,端到端地推算出参考图像的深图信息。其提出的NVSNet将相机参数编码为可微单应性变换来得到视椎体损失体积,建立起了2D特征抽取和3D损失正则化之间的关系。最终通过3D卷积来对初始点云规则化和回归来得到最终的输出结果。
为了解决点云预测中点的位置与物体全局几何形状不匹配的问题的问题,港中文提出了几何对抗损失优化单视角下点云的全局三维重建。利用多视角几何损失和条件对抗损失来对网络进行训练。
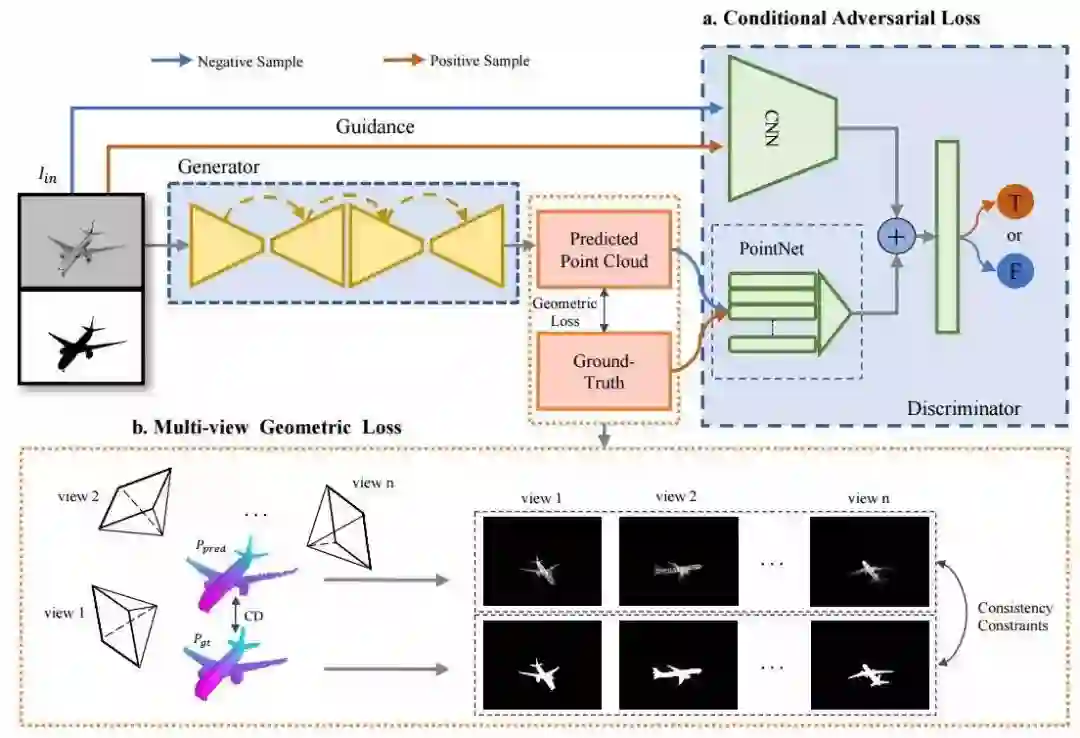
多视角几何损失使得网络学习重建多视角下有效的3D模型,而条件对抗损失则保证重建的3D物体符合普通图片中的语义信息。
除此之外还包括了普林斯顿的共面匹配方法、普林斯顿与谷歌共同完成的主动立体视觉网络以及慕尼黑工大提出的基于深度预测的单目稀疏直接里程计等研究工作。
匹配与识别方面
涵盖了目标检测、定位、纹理和位置精炼等方面的研究。
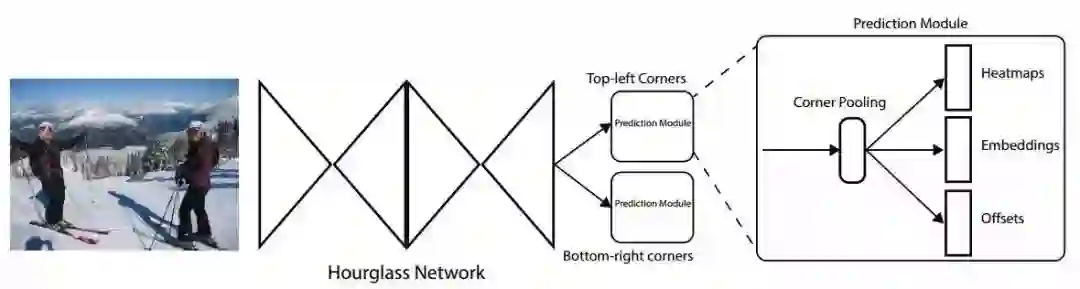
1.来自密歇根大学的研究人员提出了一种基于关键点对儿的目标检测方法CornerNet。它将目标检测任务转换为利用单个神经网络对bbox左上和右下角的检测。这种方法消除了对于锚框的依赖。并提出了一种称为角点pooling的层来提高对角点的定位能力。最终在COCO上达到了42.1%的mAP.

2.来自清华北大、旷视和头条的研究人员提出了一种目标检测中描述框定位置信度的方法IoU-Net,并利用定位置信度来改善目标检测中非极大值抑制,以产生更精确的预测框。同时提出了基于优化的框提炼方法。
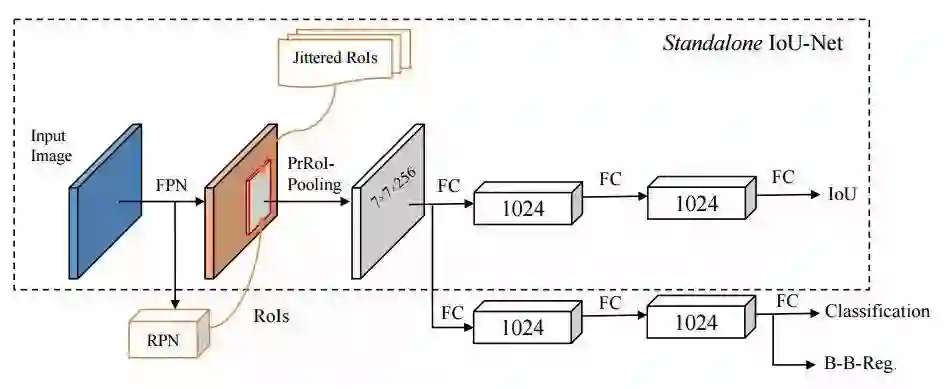
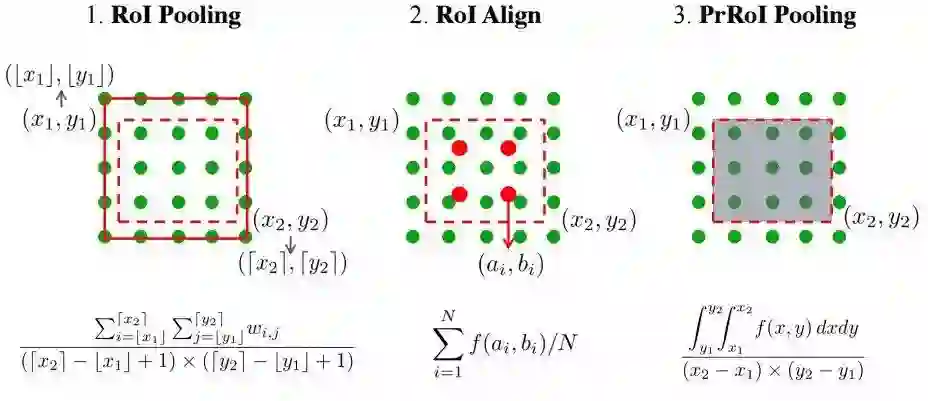
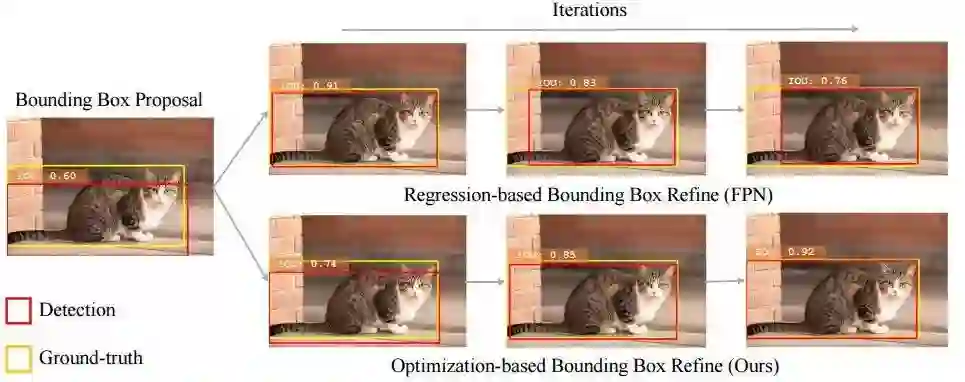
3.来自以色列理工学院的研究人员提出了一种基于上下文损失的图像迁移方法,适用于非对齐的数据。这种模型基于上下文和语义来定义损失。这一模型在卡通图像模拟、语义风格迁移和领域迁移中都表现除了很好的效果。


Tutorials
本届ECCV的tutorials同样是涉及了视觉领域各个方面的前沿内容,从对抗学习到3D重建,从行人识别到目标检测。一定能找到一个你需要的教程来深入学习。其中有Kaiming,rbg和Gkioxari等大神带来的视觉识别及其未来的系列教程。

还有神经网络训练中归一化方法的理论与实践、特征与学习的视觉定位。

还包括行人重识别的表达学习和基于步态&面部分析的识别方法。此外还包括快速三维感知重建和理解的tutorial。

更多内容请参阅,某些教程目前已经开放相关资料下载了:
https://eccv2018.org/program/workshops_tutorials/
Workshop
最后我们来概览一番每次会议都必不可少的workshops。本届ECCV包括了43个workshops,其中包含了11个各领域的挑战赛。值得一提的是,很多来自中国的队伍在很多挑战赛中都取得了不错的成绩。
今年的workshops 主要集中于识别、检测、自动机器(自动驾驶、无人机、机器人等)、人类理解分析、三维重建理解、几何/表示学习和早期视觉等领域。
如果希望了解更多的workshops,可以在这里找到更多的信息:
https://eccv2018.org/program/workshops_tutorials/
24篇开源的论文实现代码
1. Simple Baselines for Human Pose Estimation and Tracking (357 stras)
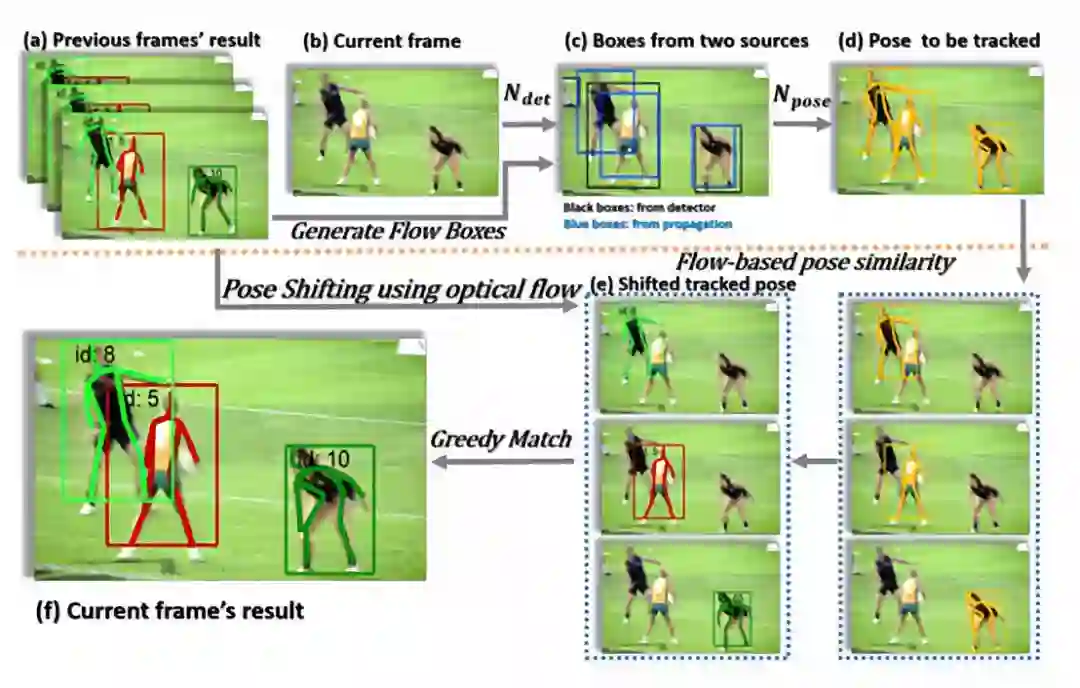
论文链接:https://arxiv.org/abs/1804.06208
代码链接:https://github.com/Microsoft/human-pose-estimation.pytorch#simple-baselines-for-human-pose-estimation-and-tracking
2. ICNet for Real-Time SemanticSegmentation on High-Resolution Images (344 stars)
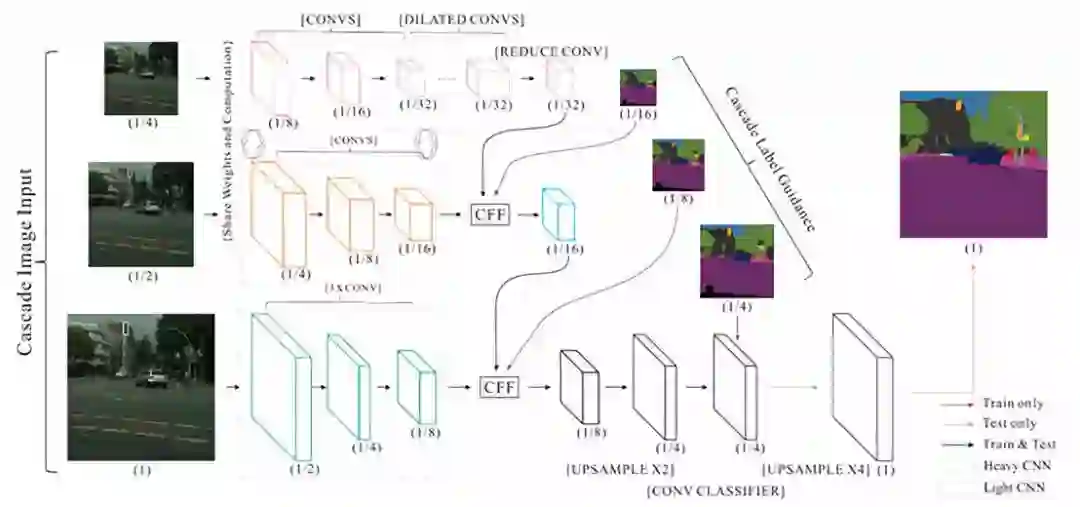
论文链接:
https://hszhao.github.io/projects/icnet/
代码链接:https://github.com/hszhao/ICNet
3. Instance-Batch Normalization Network (225stars)
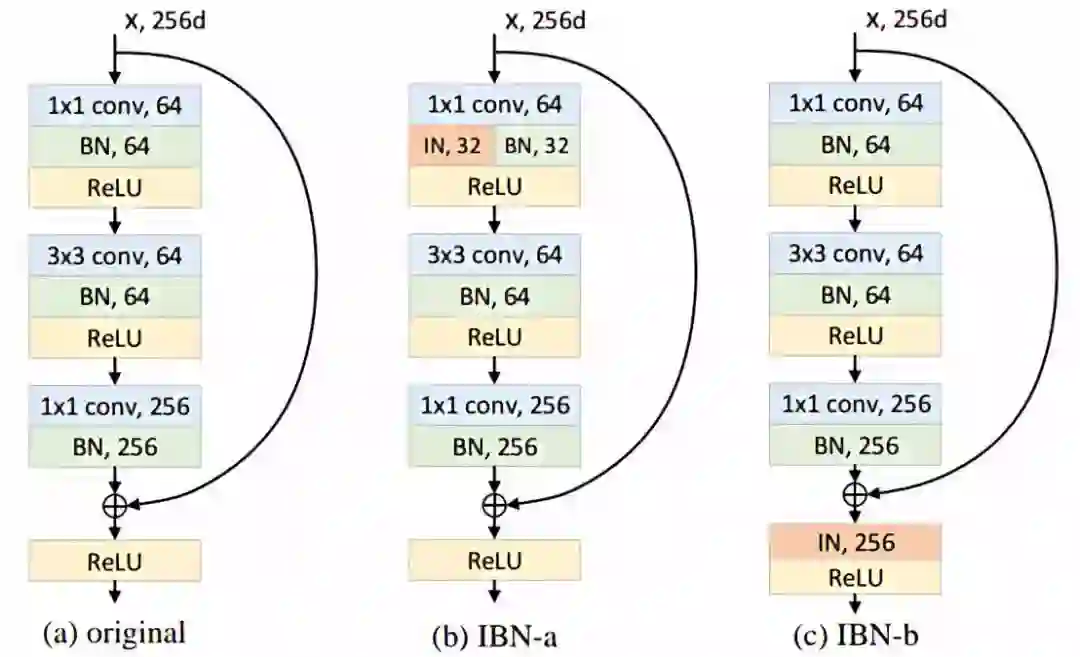
论文链接:https://arxiv.org/abs/1807.09441
代码链接:https://github.com/XingangPan/IBN-Net
4. Distractor-aware SiameseNetworks for Visual Object Tracking (225 stars)

论文链接:https://arxiv.org/pdf/1808.06048.pdf
代码链接:https://github.com/foolwood/DaSiamRPN
5. Pixel2Mesh: Generating3D Mesh Models from Single RGB Images (98 stars)
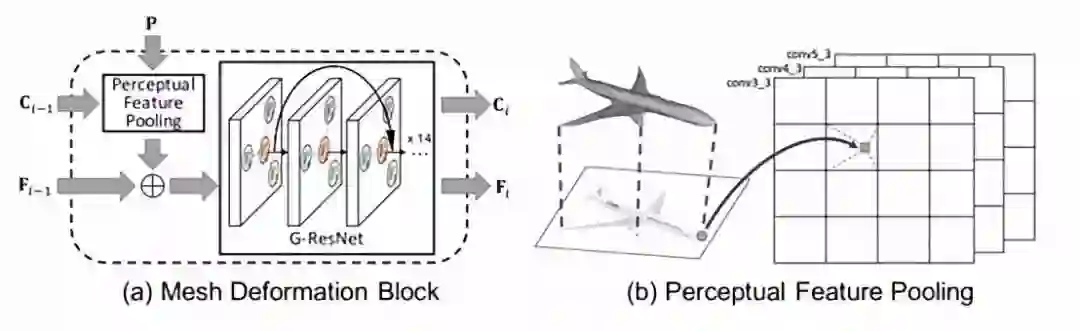
论文链接:https://arxiv.org/abs/1804.01654
代码链接:
https://github.com/nywang16/Pixel2Mesh
6. MVSNet: Depth Inferencefor Unstructured Multi-view Stereo(85 stars)

论文链接:https://arxiv.org/abs/1804.02505
代码链接:https://github.com/YoYo000/MVSNet
7. Macro-Micro AdversarialNetwork for Human Parsing (61stars)
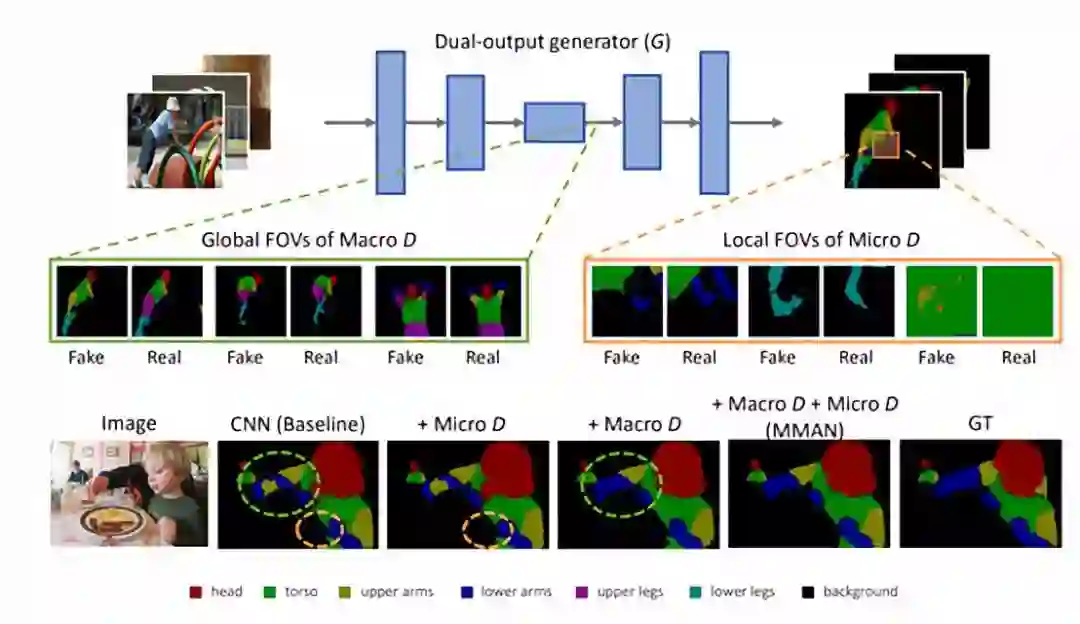
论文链接:https://arxiv.org/abs/1807.08260
代码链接:https://github.com/RoyalVane/MMAN
8. Learning Human-Object Interactions by GraphParsing Neural Networks (54 stars)
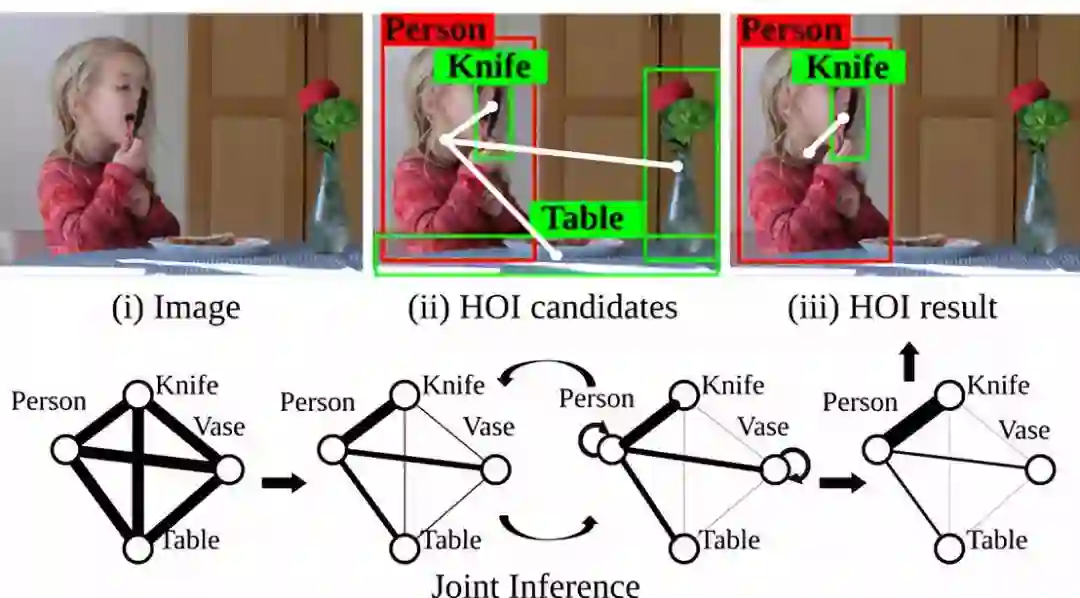
论文链接:http://web.cs.ucla.edu/~syqi/publications/eccv2018gpnn/eccv2018gpnn.pdf
代码链接:https://github.com/SiyuanQi/gpnn
9. Enhanced Super-Resolution GenerativeAdversarial Networks
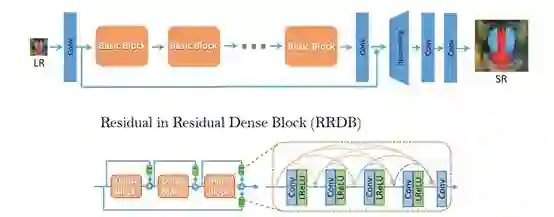
论文链接:https://arxiv.org/abs/1809.00219
代码链接:https://github.com/xinntao/ESRGAN
10. PSANet: Point-wise Spatial AttentionNetwork for Scene Parsing (34 stars)
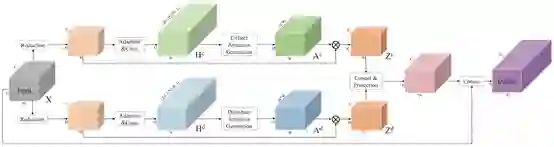
论文链接:
https://hszhao.github.io/projects/psanet/
代码链接:https://github.com/hszhao/PSANet
11.OM-CNN+2C-LSTM for video salinecy prediction
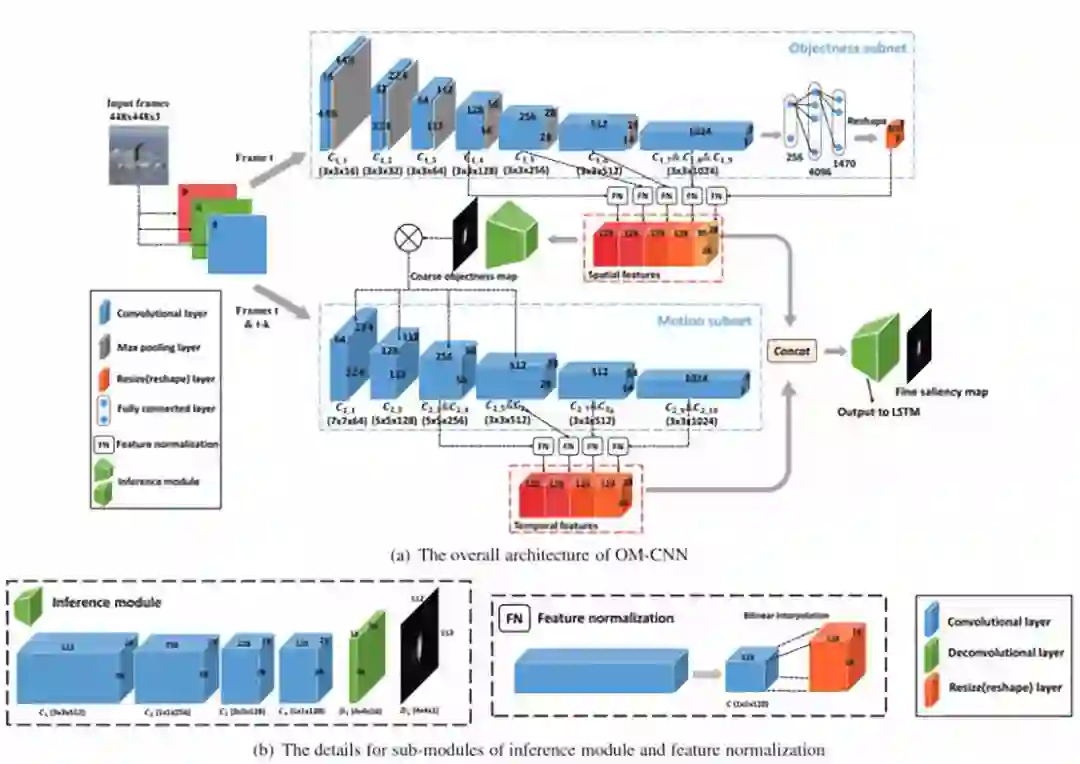
论文链接:https://arxiv.org/abs/1709.06316
代码链接:
https://github.com/remega/OMCNN_2CLSTM
12. Interpretable Intuitive Physics Model
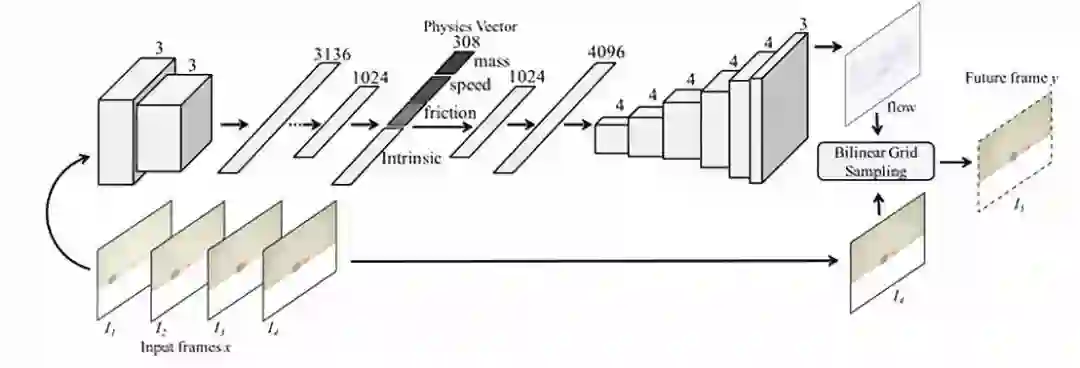
论文链接:https://www.cs.cmu.edu/~xiaolonw/papers/ECCV_Physics_Cameraready.pdf
代码链接:
https://github.com/tianye95/interpretable-intuitive-physics-model
13. Transferring GANs generating images fromlimited data
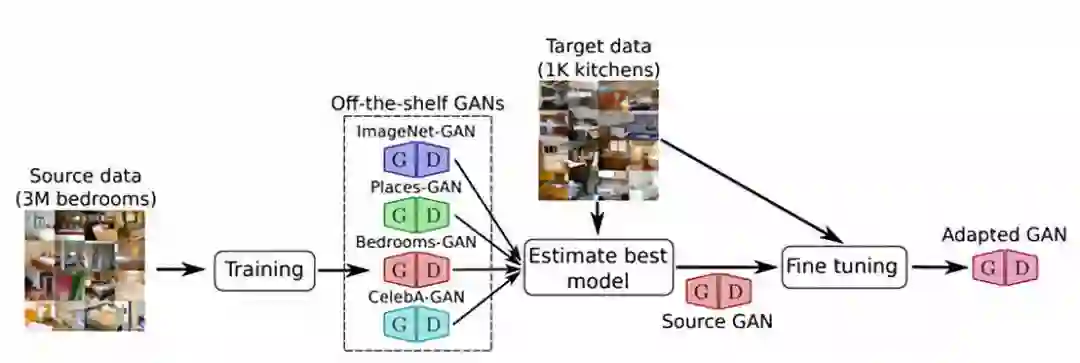
论文链接:https://arxiv.org/abs/1805.01677
代码链接:
https://github.com/yaxingwang/Transferring-GANs
14. Superpixel Sampling Networks
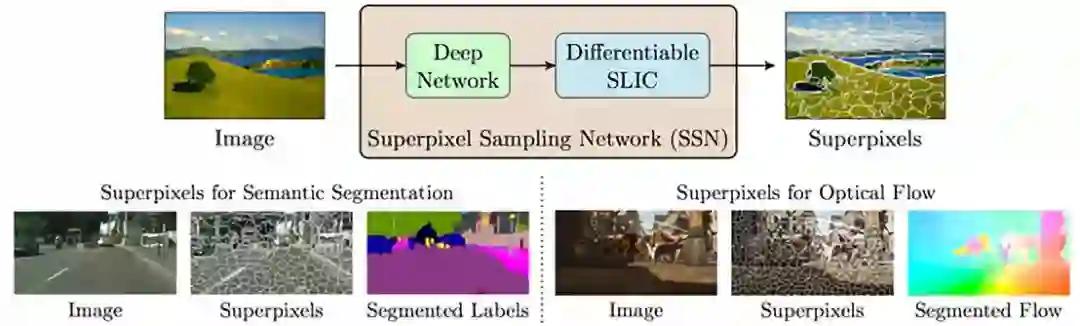
论文链接:https://varunjampani.github.io/ssn/
代码链接:
https://github.com/NVlabs/ssn_superpixels
15. A Trilateral Weighted Sparse Coding Schemefor Real-World Image Denoising

论文链接:https://arxiv.org/abs/1807.04364
代码链接:https://github.com/csjunxu/TWSC-ECCV2018
16. Deep Randomized Ensembles for MetricLearning
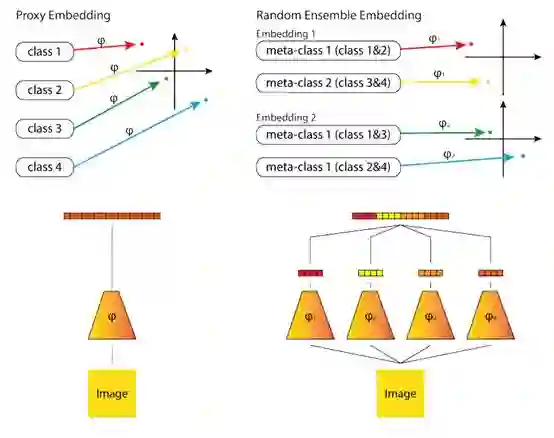
论文链接:https://arxiv.org/abs/1808.04469
代码链接:https://github.com/littleredxh/DREML
17. VISDrone2018: Challenge-ObjectDetection in Images

竞赛内容主页:http://www.aiskyeye.com/
实现代码:
https://github.com/zhpmatrix/VisDrone2018
18. Part-Aligned Bilinear Representations forPerson Re-identification
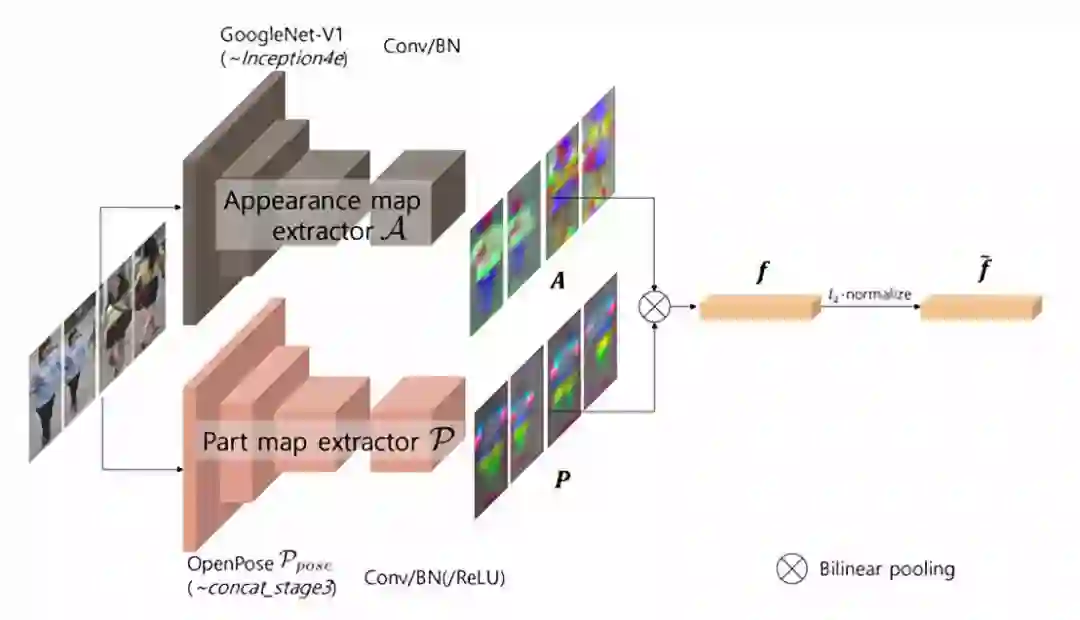
论文链接:
https://cv.snu.ac.kr/publication/conf/2018/reid_eccv18.pdf
代码链接:
https://github.com/yuminsuh/part_bilinear_reid
19. Inner Space Preserving - Generative PoseMachine (ISP-GPM)
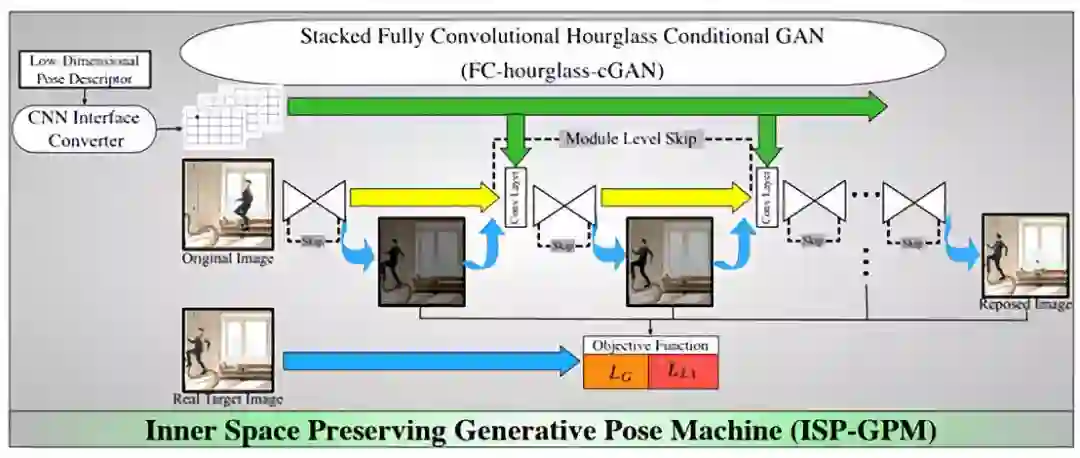
论文链接:https://arxiv.org/abs/1808.02104
代码链接:https://github.com/ostadabbas/isp-gpm
20. Rethinking the Form of Latent States inImage Captioning
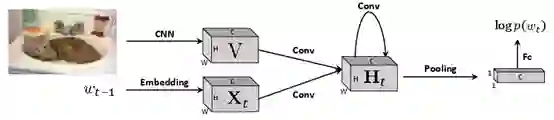
论文链接:https://arxiv.org/abs/1807.09958
代码链接:
https://github.com/doubledaibo/2dcaption_eccv2018
21. Diverse Conditional Image Generation byStochastic Regression with Latent Drop-Out Codes

论文链接:https://arxiv.org/abs/1808.01121
代码链接:
https://github.com/SSAW14/Image_Generation_with_Latent_Code
22. Learning Efficient Single-stage PedestrianDetectors by Asymptotic Localization Fitting
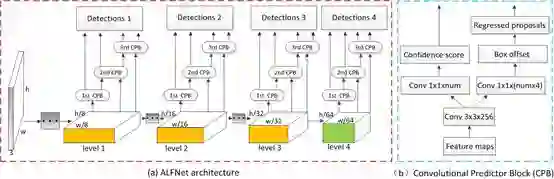
论文链接:
https://github.com/liuwei16/ALFNet/blob/master/docs/2018ECCV-ALFNet.pdf
代码链接:https://github.com/liuwei16/ALFNet
23. Statistically-motivated Second-orderPooling
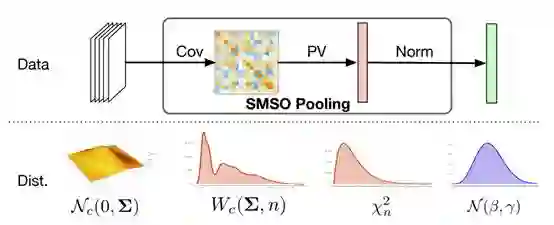
论文链接:https://arxiv.org/abs/1801.07492
代码链接:https://github.com/kcyu2014/smsop
24. Learning to Navigate for Fine-grainedClassification
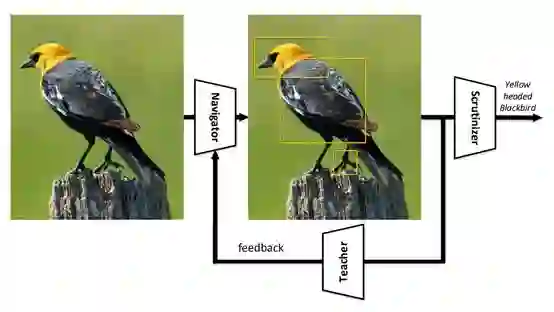
论文链接:https://arxiv.org/abs/1809.00287
代码链接:https://github.com/yangze0930/NTS-Net
每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击左下角“阅读原文”立刻申请入群~





