iOS 开发者 2019 面试总结
在投递简历之前,就是所谓的寒冬将至,开个年会都是守望寒冬,然后我身边的准备跳槽的大佬们,都是有几分凉意,不过我还好,总感觉一个人吃饱,全家不饿,😁O(∩_∩)O哈!没想那么多,直接就全身投入,找工作。现在做个回顾吧,为自己,也为路过的各位大侠。
先说一个问题,是寒冬吗?我真没觉得,说自己的一个亲身体会,不夸张的说,基本上是每天2家,且持续一个月,当然是距离可以接受,公司小中大都有的,我感觉不是互联网的寒冬,是自己的寒冬,有一句说的很好,人生就两季,努力是旺季,不努力是淡季!我感觉很有道理🤣~~~~
现在面试要求高在要会各种语言,另外要很深入,要够底层,要懂数据结构与算法之美(面试过的都会体会什么是真是一言难尽吧),看一些大佬,进入一个大厂,也写了自己的准备,我感觉真是有付出有回报的,也看出自己的一些不足吧!so,革命尚未成功,同志们仍需努力伐!!
知识点总结
因为自己水平有限,可能有些路过的大佬感觉比较简单,我也总结了下,请飘过~~还有一些答案仅供参考,如有错误,请不吝赐教,在此谢过😀---->
+(void)initinstance 与 +(void)load两个方法的区别于比较//小红书面试问题\
先看下面表格两者的区别,后续会继续介绍
| +load | +initialize | |
|---|---|---|
| 调用时机 | 被添加runtime时 | 收到第一条消息时,可能永远不调用 |
| 调用顺序 | 父类->子类->分类 | 父类->子类 |
| 调用次数 | 1次 | 多次 |
| 是否需要显示调用父类实现 | 否 | 否 |
| 是否沿用父类的实现 | 否 | 是 |
| 分类中的实现 | 类和分类都执行 |
相同点:
系统都执行一次。
假如父类和子类都被调用,父类在子类之前被调用
不同点:
load 方法会在加载类的时候就被调用,也就是 ios 应用启动的时候,就会加载所有的类,就会调用每个类的 + load 方法。
+initialize 这个方法会在 第一次初始化这个类之前 被调用,我们用它来初始化静态变量
load 会在main()函数之前调用。initialize 则在类实例化 或 类方法被调用时调用;
如果子类中没有initialize方法,则会再次调用父类的initialize方法,类别会覆盖主类的initialize,load则不会被覆盖
load顺序在 initialize之前;
• initialize 方法的调用看起来会更合理,通常在它里面写代码比在 + load 里写更好,因为它是懒调用的,也有可能完全不被调用。类第一次被加载时,
类接收消息时,运行时会先检查 + initialize 有没有被调用过。如果没有,会在消息被处理前调用
--->>>>
initialize 最终是通过 objc_msgSend 来执行的,objc_msgSend 会执行一系列方法查找,并且 Category 的方法会覆盖类中的方法
load 是在被添加到 runtime 时开始执行,父类最先执行,然后是子类,最后是 Category。又因为是直接获取函数指针来执行,不会像 objc_msgSend 一样会有方法查找的过程。
---->>>>
怎么实现单例, 2种方法实现//喜马拉雅面试问题\
//第一种方式:线程安全的单例2(不推荐 效率低)
+ (instancetype)shareSingleton2 {
@synchronized(self) {
if (!singleton) {
singleton = [[self alloc]init];
}
}
return singleton;
}
//第二种方式 线程安全的单例
+ (instancetype)shareSingleton {
static dispatch_once_t onceToken;
dispatch_once(&onceToken, ^{
singleton = [[self alloc]init];
});
return singleton;
}
然而仅仅知道这些是不够的,说了上面的,面试官会继续问单例,怎么实现的,加锁了吗?单例什么时候释放?然后你就会一脸懵~有同感的举个手🤣
单例,怎么实现的,加锁了吗?单例什么时候释放
其实在上面的两个单例的创建中,@synchronized是一个锁,后面会讲到,就是说第一种是通过加锁的方式来实现,而第二种解析如下:
GCD创建:dispatch_once中dispatch_once_t类型为typedef long
• onceToken= 0,线程执行dispatch_once的block中代码
• onceToken= -1,线程跳过dispatch_once的block中代码不执行
• onceToken= 其他值,线程被线程被阻塞,等待onceToken值改变
用途:限制创建,提供全局调用,节约资源和提高性能。参考
常见的应用场景:
• UIApplication
• NSNotificationCenter
• NSFileManager
• NSUserDefaults
• NSURLCache
• NSHTTPCookieStorage
那么单例是怎么销毁的呢?如下:
方法一:
+(void)attemptDealloc{
[_instance release]; //mrc 需要释放,当然你就不能重写release的方法了.
_instance = nil;
}
方法二:
1. 必须把static dispatch_once_t onceToken; 这个拿到函数体外,成为全局的.
2.
+(void)attempDealloc{
onceToken = 0; // 只有置成0,GCD才会认为它从未执行过.它默认为0.这样才能保证下次再次调用shareInstance的时候,再次创建对象.
[_instance release];
_instance = nil;
}
数据持久化
下面说下数据持久化吧?如果是在2年前,你说了数据持久化有NSUserDefaults,plist,归档,CoreData巴拉巴拉,感觉这位童靴还阔以,但是现在就有点low了😆,你懂得~
面试大佬会问有几种?然后每种有什么不同?什么能存储什么不能存储?每个在具体使用应该注意什么?等等,问到你怀疑人生😭
属性列表(plist存储)通常叫做plist文件,用于存储在程序中不经常修改、数据量小的数据,不支持自定义对象存储,支持数据存储的类型为:Array,Dictionary,String,Number,Data,Date,Boolean,通常用来存放接口名、城市名、银行名称、表情名等极少修改的数据
plist文件是将某些特定的类,通过xml的方式保存在目录中。
偏好设置(NSUserDefaults)
用于存储用户的偏好设置,同样适合于存储轻量级的用户数据,数据会自动保存在沙盒的Libarary/Preferences目录下,本质上就是一个plist文件,所以同样的不支持自定义对象存储,支持数据存储的类型为:Array,Dictionary,String,Number,Data,Date,Boolean,可以用做检查版本是否更新、是否启动引导页、自动登录、版本号等等,需要注意的是NSUserDefaults是定时的将缓存中的数据写入磁盘,并不是即时写入,为了防止在写完NSUserDefaults后,程序退出导致数据的丢失,可以在写入数据后使用synchronize强制立即将数据写入磁盘
如果这里你没有调用synchronize方法的话,系统会根据I/O情况不定时刻地保存到文件中。所以如果需要立即写入文件的就必须调用synchronize方法。
PS: 在这里说了小问题,就是有面试官会问,你在开发中用NSUserDefaults有没有什么坑?你可以这样答:比如你存储一个值时,没有进行及时的调用synchronize方法,然后此时程序就crash了或者强制杀死,那么你再下次去取值的时候,就会取不到你之前存储的值,路过的大佬可以试下~~😜
归档序列化存储
归档可以直接将对象存储为文件,也可将文件直接解归档为对象,相对于plist文件与偏好设置数据的存储更加多样,支持自定义的对象存储,归档后的文件是加密的,也更加的安全,文件存储的位置可以自定义。
遵守NSCoding或者NSSecureCoding协议
沙盒存储
可以提高程序的体验度,为用户节约数据流量,主要在用户阅读书籍、听音乐、看视频等,在沙盒中做数据的存储,主要包含文件夹:Documents: 最常用的目录,存放重要的数据,iTunes同步时会备份该目录Library/Caches: 一般存放体积大,不重要的数据,iTunes同步时不会备份该目录Library/Preferences: 存放用户的偏好设置,iTunes同步时会备份该目录tmp: 用于存放临时文件,在程序未运行时可能会删除该文件夹中的数据,iTunes同步时不会备份该目录
Core Data
Core Data是框架,并不是数据库,该框架提供了对象关系的映射功能,使得能够将OC对象转换成数据,将数据库中的数据还原成OC对象,在转换的过程中不需要编写任何的SQL语句,在Core Data中有三个重要的概念:
NSPersistentStoreCoordinator:持久化存储协调器,在NSPersistentStoreCoordinator中包含了持久化存储区,在持久化存储区中包含了数据表中的很多数据,持久化存储区的设置通常选择NSSQLiteStoreType,也就是选择SQLite数据库
NSManagedObjectModel:托管对象模型,用于描述数据结构的模型
SQLite3
SQLite是轻量级的数据库,占用资源很少,最初是用于嵌入式的系统,在iOS中使用SQLite,需要加入"libsqlite3.tbd"依赖库并导入头文件。不应该频繁的打开关闭数据库,有可能会影响性能, 应在启动程序时打开数据库,在退出程序是关闭数据库
FMDB
FMDB以OC的方式封装了SQLite的C语言API,减去了冗余的C语言代码,使得API更具有OC的风格,更加的面向对象,相对于Core Data框架更加的轻量级,FMDB还提供了多线程安全的数据库操作方法,在FMDB中有三个重要的概念:
FMDatabase:一个FMDatabase就代表一个SQLite数据库,执行sql语句
FMResultSet:执行查询后的结果集
FMDatabaseQueue:用于在多线程中执行多个查询或更新,安全的
===
紧接着说下CoreData吧?它总是比你知道的还要多?
CoreData中的多线程问题
主要推荐的实施方案,也是最优方案,如下:
1.使用一个NSPersistentStoreCoordinator,以及两个独立的Contexts,一个context负责主线程与UI协作,一个context在后台负责耗时的处理,用Notifications的方式通知主线程的NSManagedObjectContext进行mergeChangesFromContextDidSaveNotification操作
2.后台线程做读写更新,而主线程只读
3.CoreData中的NSManagedObjectContext在多线程中不安全,如果想要多线程访问CoreData的话,最好的方法是一个线程一个NSManagedObjectContext,每个NSManagedObjectContext对象实例都可以使用同一个NSPersistentStoreCoordinator实例,这个实例可以很安全的顺序访_问永久存储,这是因为NSManagedObjectContext会在便用NSPersistentStoreCoordinator前上锁。ios5.0为NSManagedObjectContext提供了initWithConcurrentcyType方法,其中的一个NSPrivateQueueConcurrencyType,会自动的创建一个新线程来存放NSManagedObjectContext而且它还会自动创建NSPersistentStoreCoordinator,
CoreData里面还带有一个通知NSManagedObjectContextDidSaveNotification,主要监听NSManagedObjectContext的数据是否改变,并合并数据改变到相应context。
面试官问的Context是那两种?这个面试官问的应该是用到的那两个Type?
答:NSConfinementConcurrencyType NSMainQueueConcurrencyType
//创建并行的NSManagedObjectContext对象
[[NSManagedObjectContext alloc] initWithConcurrencyType:NSPrivateQueueConcurrencyType];
ps:NSConfinementConcurrencyType (或者不加参数,默认就是这个)NSMainQueueConcurrencyType (表示只会在主线程中执行)
接着谈谈数据库的优化问题,可以通过以下几点进行优化
FMDB事务批量更新数据库速度问题。(亲测可以呀---740条数据用和不用事务效率差别20倍+)
写同步(synchronous)
在SQLite中,数据库配置的参数都由编译指示(pragma)来实现的,而其中synchronous选项有三种可选状态,分别是full、normal、off
设置为synchronous OFF (0)时,SQLite在传递数据给系统以后直接继续而不暂停一条SQL语句插入多条数据
在事务中进行插入处理。
数据有序插入。
再说下什么是事务?\英语流利说总监面试问题//
事务:
作为单个逻辑工作单元执行的一系列操作,而这些逻辑工作单元需要具有原子性,一致性,隔离性和持久性
是并发控制的基本单元。所谓的事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单元。例如,银行转账工作:从一个账号扣款并使另一个账号增款,这两个操作要么都执行,要么都不执行。所以,应该把它们看成一个事务。
事务是一种机制,用于维护数据库的完整性
事务基本特征:
原子性(Atomicity):事务的个元素是不可分的,事务是一个完整的操作,一个操作序列,要么都执行,要么都不执行
一致性(Consistemcy):事务完成时,数据必须是一致的,保证数据的无损
隔离性(Isolation):多个事务彼此隔离,事务必须是独立的,任何事务都不应该受影响
持久性(Durability):事务完成之后,它对于系统的影响是永久的,该修改即使出现系统故障也将一直保留,真实的修改了数据库
五种 Mach-O 类型的浅要分析
这个面试题针对我自己的简历,可略过~
在制作Framework时,可以设置framework中的Mach-O Type,不手动修改的默认配置即为 Dynamic Library,在SDK中默认使用的是 Relocatable Object File
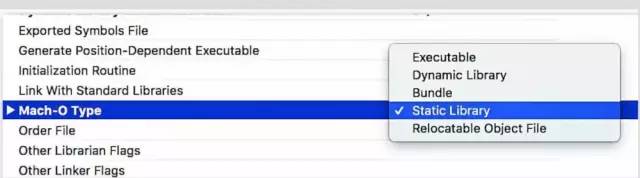
Executable: 可执行二进制文件
dynamic Library 动态库
Bundle :非独立二进制文件,显示加载
static Library 静态库
Relocatable Object File: 可重定位的目标文件,中间结果
Relocatable Object File 是组装静态库和动态库的零件,而静态库和动态库就是可执行二进制文件的组件。这里用了零件和组件的概念,零件是不可缺少的,组件则是可选的
Dynamic Library 更灵活;复用性更强;且就安全来说,统一放置在 Payload/Framework 目录下的自建的动态库,不参与应用的加壳操作,安全性稍逊一筹
Relocatable Object File 以及 Static Library 都是在编译后直接合并到最后的可执行文件中的,缺点相对不够灵活,但安全性稍强。
如果要偏向静态的方案,应该选择 Relocatable Object File 还是 Static Library?
使用 Relocatable Object File 可以减少二进制文件的大小
动态库和静态库的区别:
如果使用动态库,需要考虑的是:
对于启动速度的影响。
对于保密要求高的线下渠道 SDK,可能会被从 .app/ 中单独拿出来,反编译研究具体实现。静态库则比较安全一点。
内存管理
Objective-C的内存管理主要有三种方式ARC(自动内存计数)、手动内存计数、内存池。
1). 自动内存计数ARC:由Xcode自动在App编译阶段,在代码中添加内存管理代码。
2). 手动内存计数MRC:遵循内存谁申请、谁释放;谁添加,谁释放的原则。
3). 内存释放池Release Pool:把需要释放的内存统一放在一个池子中,当池子被抽干后(drain),池子中所有的内存空间也被自动释放掉。内存池的释放操作分为自动和手动。自动释放受runloop机制影响。
有一个很经典的面试题,考察自动释放池的如下:
for (int i = 0; i < MAXFLOAT; i++) {
NSString *string = @"stdy";
string = [string lowercaseString];
string = [string stringByAppendingString:@"123"];
NSLog(@"--%@", string);
}
上述的这种写法,会使内存慢慢增加,如何解决呢,面试官想要的答案就是用自动释放池,你也可以改成其他的,但不是面试官要的,你懂的[😂],修改如下:
for (int i = 0; i < MAXFLOAT; i++) {
@autoreleasepool {
NSString *string = @"stdy";
string = [string lowercaseString];
string = [string stringByAppendingString:@"123"];
NSLog(@"--%@", string);
}
}
什么时间会创建自动释放池?*
从程序启动到加载完成是一个完整的运行循环,然后会停下来,等待用户交互,用户的每一次交互都会启动一次运行循环,来处理用户所有的点击事件、触摸事件,运行循环检测到事件并启动后,就会创建自动释放池。
子线程的 runloop 默认是不工作,无法主动创建,必须手动创建。
自定义的 NSOperation 和 NSThread 需要手动创建自动释放池。比如:自定义的 NSOperation 类中的 main 方法里就必须添加自动释放池。否则出了作用域后,自动释放对象会因为没有自动释放池去处理它,而造成内存泄露。
但对于 blockOperation 和 invocationOperation 这种默认的Operation ,系统已经帮我们封装好了,不需要手动创建自动释放池。
@autoreleasepool 当自动释放池被销毁或者耗尽时,会向自动释放池中的所有对象发送 release 消息,释放自动释放池中的所有对象。
如果在一个vc的viewDidLoad中创建一个 Autorelease对象,那么该对象会在 viewDidAppear 方法执行前就被销毁了。
什么会造成离屏渲染
GPU屏幕渲染有两种方式:
(1)On-Screen Rendering (当前屏幕渲染)
指的是GPU的渲染操作是在当前用于显示的屏幕缓冲区进行。
(2)Off-Screen Rendering (离屏渲染)
指的是在GPU在当前屏幕缓冲区以外开辟一个缓冲区进行渲染操作。
下面的情况或操作会引发离屏渲染:
为图层设置遮罩(layer.mask)
将图层的layer.masksToBounds / view.clipsToBounds属性设置为true
将图层layer.allowsGroupOpacity属性设置为YES和layer.opacity小于1.0
为图层设置阴影(layer.shadow *)。
为图层设置layer.shouldRasterize=true
具有layer.cornerRadius,layer.edgeAntialiasingMask,layer.allowsEdgeAntialiasing的图层
文本(任何种类,包括UILabel,CATextLayer,Core Text等)。
使用CGContext在drawRect :方法中绘制大部分情况下会导致离屏渲染,甚至仅仅是一个空的实现。
优化:
1、圆角优化
方案1 :使用贝塞尔曲线UIBezierPath和Core Graphics框架画出一个圆角
方案2 :使用CAShapeLayer和UIBezierPath设置圆角
2、shadow优化
对于shadow,如果图层是个简单的几何图形或者圆角图形,我们可以通过设置shadowPath来优化性能,能大幅提高性能
其他优化:
当我们需要圆角效果时,可以使用一张中间透明图片蒙上去使用ShadowPath指定layer阴影效果路径
使用异步进行layer渲染(Facebook开源的异步绘制框架AsyncDisplayKit)
设置layer的opaque值为YES,
减少复杂图层合成尽量使用不包含透明(alpha)通道的图片资源
尽量设置layer的大小值为整形值
直接让美工把图片切成圆角进行显示,这是效率最高的一种方案很多情况下用户上传图片进行显示,
可以让服务端处理圆角使用代码手动生成圆角Image设置到要显示的View上,
利用UIBezierPath(CoreGraphics框架)画出来圆角图片
网络通信
• 1、应用层 协议有:HTTP FTP TFTP SMTP SNMP DNS TELNET HTTPS POP3 DHCP
• 2、表示层 数据的表示、安全、压缩,格式有:JPEG、ASCll、DECOIC、加密格式等(数据格式化,代码转换,数据加密),没有协议
• 3、会话层 建立、管理、终止会话,没有协议
• 4、传输层 定义传输数据的协议端口号,以及流控和差错校验。协议有:TCP UDP,数据包一旦离开网卡即进入网络传输层
• 5、网络层 进行逻辑地址寻址,实现不同网络之间的路径选择。协议有:ICMP IGMP IP(IPV4 IPV6) ARP RARP
• 6、数据链路层 建立逻辑连接、进行硬件地址寻址、差错校验 等功能。(由底层网络定义协议)将比特组合成字节进而组合成帧,用MAC地址访问介质,错误发现但不能纠正。协议有:SLIP CSLIP PPP MTU ARP[链接:https://baike.baidu.com/item/A ... addin]RARP
• 7、物理层 建立、维护、断开物理连接。以二进制数据形式在物理媒体上传输数据(由底层网络定义协议)协议有:ISO2110 IEEE802 IEEE802.2
===
TPC/IP协议是传输层协议,主要解决数据如何在网络中传输
HTTP是应用层协议,主要解决如何包装数据
我们在传输数据时,可以只使用(传输层)TCP/IP协议,但是那样的话,如果没有应用层,便无法识别数据内容,如果想要使传输的数据有意义,则必须使用到应用层协议,应用层协议有很多,比如HTTP、FTP、TELNET等,也可以自己定义应用层协议
TCP和UDP使用该协议从一个网络传送数据包到另一个网络。把IP想像成一种高速公路,它允许其它协议在上面行驶并找到到其它电脑的出口。TCP和UDP是高速公路上的“卡车”,它们携带的货物就是像HTTP,文件传输协议FTP这样的协议等。
===========
什么是Socket?
Socket其实并不是一个协议 而是一个通信模型。它是为了方便大家直接使用更底层协议(TCP | UDP)而存在的抽象层
Socket是对 TCP/IP协议的封装,Socket本身并不是协议,而是一个调用的接口(API),主要用来一台电脑的两个进程通信,
Socket在网络通信中,它涵盖了网络层、传输层、会话层、表示层、应用层,因为其信时候用到了IP和端口,仅这两个就表明了它用到了网络层和传输层,而且它无视多台电脑通信的系统差别,所以它涉及了表示层,一般Socket都是基于一个应用程序的,所以会涉及到会话层和应用层
什么是WebSocket,解决了什么问题?//英语流利说面\
WebSocket是应用层第七层上的一个应用层协议,它必须依赖 HTTP 协议进行一次握手 ,握手成功后,数据就直接从 TCP 通道传输,与 HTTP 无关了
Websocket的数据传输是frame形式传输的,比如会将一条消息分为几个frame,按照先后顺序传输出去。这样做会有几个好处:
• 1) 大数据的传输可以分片传输,不用考虑到数据大小导致的长度标志位不足够的情况。
• 2 )和http的chunk一样,可以边生成数据边传递消息,即提高传输效率。总之:WebSocket 的实现分为握手,数据发送/读取,关闭连接。
什么是心跳?
心跳就是用来检测TCP连接的双方是否可用
客户端发起心跳Ping(一般都是客户端),假如设置在10秒后如果没有收到回调,那么说明服务器或者客户端某一方出现问题,这时候我们需要主动断开连接。
HTTP 的几种请求方式?以及区别 \英语流利说//
英语流利说总监问了一个HTTP的PUT请求,下面看下各个请求的不同之处吧
HTTP1.0定义了三种请求方法:GET, POST 和 HEAD方法。
HTTP1.1新增了五种请求方法:OPTIONS, PUT, DELETE, TRACE 和 CONNECT 方法。
HTTP协议使用的是URI,是一种表示资源标志,那么对应的HTTP Verb就是各种对资源的操作,GET,PUT,DELETE等,明确这些,再往下看。可参考
HTTP: Hyper Text Transfer Protocol,超文本传输协议URI: Universal Resource Identifier,统一资源标识符URL: Universal Reversource Locator,统一资源定位符
简单地说,URI是在某一规则下能把资源独一无二地标识出来,URL是特殊的URI,即用定位的方式实现URI
GET 请求指定的页面信息,并返回实体主体。
HEAD 类似于get请求,只不过返回的响应中没有具体的内容,用于获取报头。
PUT:从客户端向服务器传送的数据取代指定的文档的内容, 用PUT来达到更改资源,需要client提交资源全部信息,如果只有部分信息,不应该使用PUT
DELETE:请求服务器删除指定的页面。
OPTIONS:允许客户端查看服务器的性能。
HTTPS
一般面试官问了你HTTP之后就会问你HTTPS了,真是一个都不能少伐?
HTTPS(Hyper Text Transfer Protocol over Secure Socket Layer), 是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL
HTTPS的通信过程,盗一张图
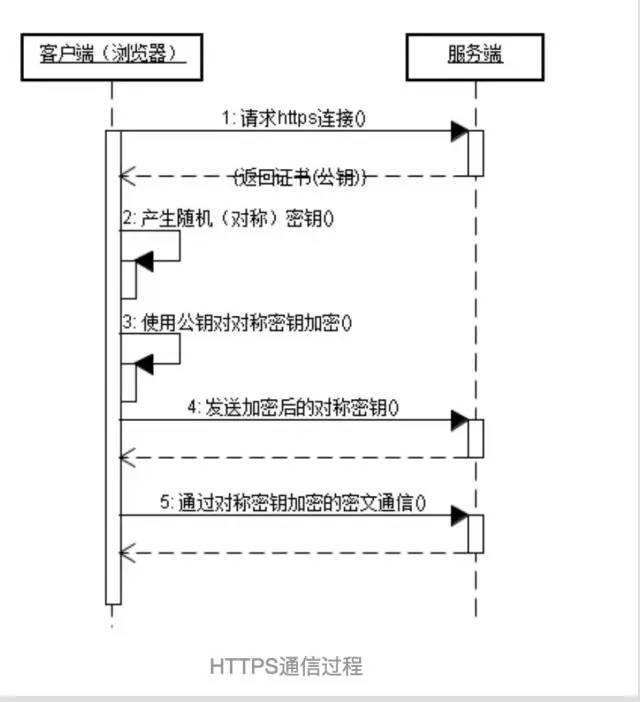
HTTPS通信过程:
客户端请求https链接,服务端返回公钥
客户端产生随机对称密钥
客户端用公钥对对称密钥加密
客户端发送加密后的对称密钥
客户端发送通过对称密钥加密的密文通信
===
HTTPS与HTTP的区别:
超文本传输协议HTTP协议被用于在Web浏览器和网站服务器之间传递信息。
HTTP协议以明文方式发送内容,不提供任何方式的数据加密
HTTPS:安全套接字层超文本传输协议HTTPS, 在HTTP的基础上加入SSL协议,SSL依靠证书来验证服务器的身份,并为浏览器和服务器之间的通信加密
https协议需要到ca申请证书,一般免费证书很少,需要交费。
http是超文本传输协议,信息是明文传输,https 则是具有安全性的ssl加密传输协议。
http和https使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
http的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比http协议安全。
两个小问题
1)如何保证公钥不被篡改?
解决方法:将公钥放在数字证书中。只要证书是可信的,公钥就是可信的。
(2)公钥加密计算量太大,如何减少耗用的时间?
解决方法:每一次对话(session),客户端和服务器端都生成一个"对话密钥"(session key),用它来加密信息。由于"对话密钥"是对称加密,所以运算速度非常快,而服务器公钥(非对称加密)只用于加密"对话密钥"本身,这样就减少了加密运算的消耗时间。
SSL协议
SSL: SSL协议的基本思路是采用公钥加密法, 采就是客户端先向服务器端索要公钥,然后用公钥加密信息,服务器收到密文后,用自己的私钥解密。
SSL协议的基本过程如下:
客户端向服务器端索要并验证公钥
双方协商生成”对话密钥”
双方采用“ 对话密钥”进行加密通信c
NSTimer面试考点
先来说一下NSTimer在使用的时候内存泄漏的分析
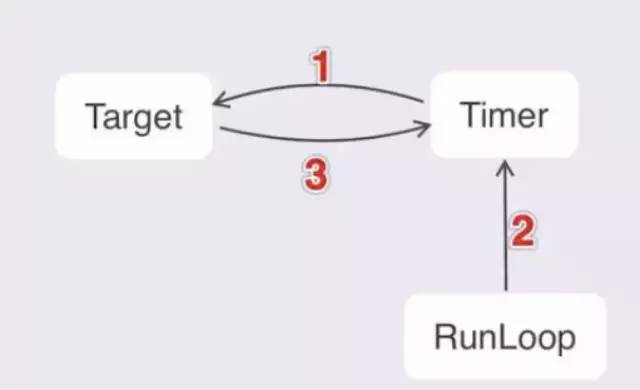
NSTimer必须与RunLoop搭配使用,因为其定时任务的触发基于RunLoop,NSTimer使用常见的Target-Action模式。由于RunLoop会强引用timer,timer会强引用Target,容易造成循环引用、内存泄露等问题
loop 强引用timer, timer 强引用 target,如果不能释放,会造成内存泄漏,有一个面试官问如果在target中传入weak的self,那么可以解决循环引用问题吗?答案是否,
Target强引用or弱引用Timer并不是问题的关键,问题的关键是:一定要在Timer使用完毕调用invalidate使之失效(手动调用or系统自动调用),Timer从RunLoop中被移除并清除强引用,这个操作可打破引用1、2,而引用3是强弱引用已经不重要了
NSTimer一共有三种初始化方案:init开头的普通创建方法、timer开头的类工厂方法、scheduled开头的类工厂方法。前两者需要手动加入RunLoop中,后者会自动加入当前RunLoop的DefaultMode中
以上我只是整理说了一些核心的点,其他部分可阅读这里
对于NSTimer,面试官还会问,它是否是时间准确呢?大家可能都知道是时间不准确的,因为受RunLoop的影响,那么GCD中也有延时,如果用GCD来做延时,那时间准确吗?
答案是GCD的time是准确的,GCD 的线程管理是通过系统来直接管理的。GCD Timer 是通过 dispatch port 给 RunLoop 发送消息,来使 RunLoop 执行相应的 block,如果所在线程没有 RunLoop,那么 GCD 会临时创建一个线程去执行 block,执行完之后再销毁掉,因此 GCD 的 Timer 是不依赖 RunLoop 的。
KVC和KVO
在这里只说一个问题,kvo 里面什么时候修改属性的stter方法的?
中间类在被观察的属性的setter方法中,在改变属性值的前后分别添加了willChangeValueForKey:和didChangeValueForKey:。使其在通过KVC标准改变属性值时可以被观察到,并向观察者发送消息。
AFNetworking的工作原理,2.0和3.0的线程区别?
AFNetworking 2.0 线程 使用的是常驻线程,自己创建线程并添加到runloop中,AFN每次进行的网络操作,开始、暂停、取消操作时都将相应的执行任务扔进了自己创建的线程的 RunLoop 中进行处理,从而避免造成主线程的阻塞。
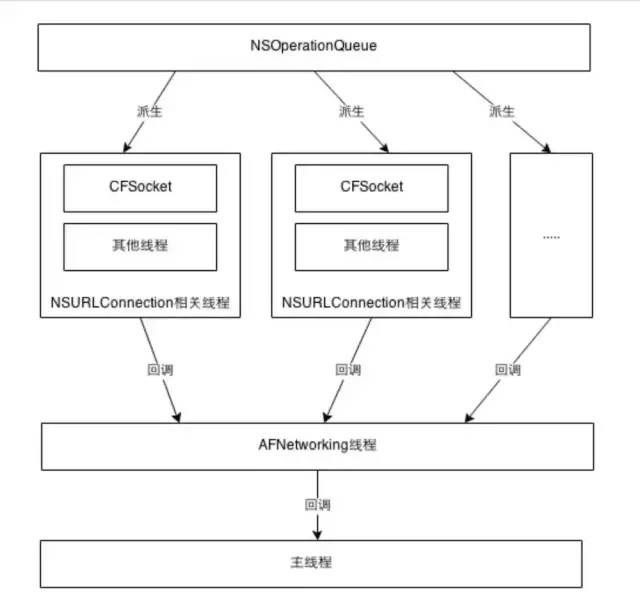
每一个请求对应一个AFHTTPRequestOperation实例对象(以下简称operation),每一个operation在初始化完成后都会被添加到一个NSOperationQueue中。由这个NSOperationQueue来控制并发,系统会根据当前可用的核心数以及负载情况动态地调整最大的并发 operation 数量,我们也可以通过setMaxConcurrentoperationCount:方法来设置最大并发数。注意:并发数并不等于所开辟的线程数。具体开辟几条线程由系统决定。
也就是说此处执行operation是并发的、多线程的。
AF中常驻线程的实现
使用单例创建线程
添加到runloop中,且加了一个NSMachPort,来防止这个新建的线程由于没有活动直接退出。【 使用MachPort配合RunLoop进行线程保活】
AF3.x为什么不再需要常驻线程?
NSURLConnection的一大痛点就是:发起请求后,这条线程并不能随风而去,而需要一直处于等待回调的状态。
NSURLSession发起的请求,不再需要在当前线程进行代理方法的回调!可以指定回调的delegateQueue,这样我们就不用为了等待代理回调方法而苦苦保活线程了。
同时还要注意一下,指定的用于接收回调的Queue的maxConcurrentOperationCount设为了1,这里目的是想要让并发的请求串行的进行回调。
为什么要串行回调?
- (AFURLSessionManagerTaskDelegate *)delegateForTask:(NSURLSessionTask *)task {
NSParameterAssert(task);
AFURLSessionManagerTaskDelegate *delegate = nil;
[self.lock lock];
//给所要访问的资源加锁,防止造成数据混乱
delegate = self.mutableTaskDelegatesKeyedByTaskIdentifier[@(task.taskIdentifier)];
[self.lock unlock];
return delegate;
}
这边对 self.mutableTaskDelegatesKeyedByTaskIdentifier 的访问进行了加锁,目的是保证多线程环境下的数据安全
面试官可能会问你:为什么AF3.0中需要设置self.operationQueue.maxConcurrentOperationCount = 1;而AF2.0却不需要?
--->>>
AF3.0的operationQueue是用来接收NSURLSessionDelegate回调的,鉴于一些多线程数据访问的安全性考虑,设置了maxConcurrentOperationCount = 1来达到串行回调的效果
--->>>
AF2.0的operationQueue是用来添加operation并进行并发请求的,所以不要设置为1。
MRC环境下在assign、retain、copy下属性的set方法
直接上代码了-->>
//assign环境下
-(void)setName:(NSString *)name{
_name = name;
}
//retain环境下
-(void)setName:(NSString *)name{
if (_name != name) {
[_name release];
_name = [name retain];
}
}
//copy环境下
-(void)setName:(NSString *)name{
if (_name != name) {
[_name release];
_name = [name copy];
}
}
深拷贝,浅拷贝
浅copy,类似strong,持有原始对象的指针,会使retainCount加一。
深copy,会创建一个新的对象,不会对原始对象的retainCount变化。
面试官可能会问,如果对一个可变数组进行深拷贝,则会对可变数组里面的元素也会进行重新复制一份吗?答:不会,深拷贝,可变数组就是一个箱子,如果进行深拷贝,则会再拷贝出一个新的箱子,但箱子里面的元素不会拷贝出新的。
iOS中的几种锁
互斥锁
用于多线程编程,防止两条线程同时对同一公共资源进行读写的机制。NSLock,pthread_mutex, @synchronized
递归锁
递归锁有一个特点,就是同一个线程可以加锁N次而不会引发死锁。
NSRecursiveLock, 2.pthread_mutex(recursive):
自旋锁:
是用于多线程同步的一种锁,线程反复检查锁变量是否可用。由于线程在这一过程中保持执行,因此是一种忙等待。一旦获取了自旋锁,线程会一直保持该锁,直至显式释放自旋锁。
OSSpinLock
信号量:一种同步方式
信号量可以有更多的取值空间,用来实现更加复杂的同步,而不单单是线程间互斥。
dispatch_semaphore:
条件锁:
就是条件变量,当进程的某些资源要求不满足时就进入休眠,也就是锁住了。当资源被分配到了,条件锁打开,进程继续运行。
NSCondition, NSConditionLock
遵循NSLocking协议,使用的时候同样是lock,unlock加解锁,wait是傻等,waitUntilDate:方法是等一会,都会阻塞掉线程,signal是唤起一个在等待的线程,broadcast是广播全部唤起。
读写锁:
//加读锁
pthread_rwlock_rdlock(&rwlock);
//解锁
pthread_rwlock_unlock(&rwlock);
//加写锁
pthread_rwlock_wrlock(&rwlock);
//解锁
pthread_rwlock_unlock(&rwlock);
@synchronized结构在工作时为传入的对象分配了一个递归锁,其他内容可参阅文档
SDWebImage 缓存原理
对于常用的三方库,一般面试官都会问到,因为篇幅较长,我只说一些比较核心的点,
SDWebImage 使用的是NSCache进行缓存的,为什么用NSCache进行缓存呢,
int main(int argc, const char * argv[]) {
@autoreleasepool {
//创建一个NSCache缓存对象
NSCache *cache = [[NSCache alloc] init];
//设置缓存中的对象个数最大为5个
[cache setCountLimit:5];
//创建一个CacheTest类作为NSCache对象的代理
CacheTest *ct = [[CacheTest alloc] init];
//设置代理
cache.delegate = ct;
//创建一个字符串类型的对象添加进缓存中,其中key为Test
NSString *test = @"Hello, World";
[cache setObject:test forKey:@"Test"];
//遍历十次用于添加
for (int i = 0; i < 10; i++)
{
[cache setObject:[NSString stringWithFormat:@"Hello%d", i] forKey:[NSString stringWithFormat:@"World%d", i]];
NSLog(@"Add key:%@ value:%@ to Cache", [NSString stringWithFormat:@"Hello%d", i], [NSString stringWithFormat:@"World%d", i]);
}
for (int i = 0; i < 10; i++)
{
NSLog(@"Get value:%@ for key:%@", [cache objectForKey:[NSString stringWithFormat:@"World%d", i]], [NSString stringWithFormat:@"World%d", i]);
}
[cache removeAllObjects];
for (int i = 0; i < 10; i++)
{
NSLog(@"Get value:%@ for key:%@", [cache objectForKey:[NSString stringWithFormat:@"World%d", i]], [NSString stringWithFormat:@"World%d", i]);
}
NSLog(@"Test %@", test);
}
return 0;
}
上面的代码创建了一个NSCache对象,设置了其最大可缓存对象的个数为5个,当我们要添加第六个对象时NSCache自动删除了我们添加的第一个对象并触发了NSCacheDelegate的回调方法,
添加第七个时也是同样的,删除了缓存中的一个对象才能添加进去,一下情况NSCache会删除缓存:
• NSCache缓存对象自身被释放
• 手动调用removeObjectForKey:方法
• 手动调用removeAllObjects
• 缓存中对象的个数大于countLimit,或,缓存中对象的总cost值大于totalCostLimit
• 程序进入后台后
• 收到系统的内存警告
异步方式在ioQueue上执行删除操作,所有IO操作使用一个串行队列来执行,避免加锁释放锁的复杂,还有就是使用NSOperation作为一个标识用来取消耗时的磁盘查询任务。内存缓存就直接删除NSCache对象的数据,磁盘缓存就直接获取文件的绝对路径后删除即可
if (fromDisk) {
//异步方式在ioQueue上执行删除操作
dispatch_async(self.ioQueue, ^{
//使用key构造一个默认路径下的文件存储的绝对路径
//调用NSFileManager删除该路径的文件
[_fileManager removeItemAtPath:[self defaultCachePathForKey:key] error:nil];
//有回调块就在主线程中执行
if (completion) {
dispatch_async(dispatch_get_main_queue(), ^{
completion();
});
}
});
//不需要删除磁盘数据并且有回调块就直接执行
} else if (completion){
completion();
}
删除磁盘中过期的图片,以及当缓存大小大于配置的值时,进行缓存清理
- (void)backgroundDeleteOldFiles {
Class UIApplicationClass = NSClassFromString(@"UIApplication");
if(!UIApplicationClass || ![UIApplicationClass respondsToSelector:@selector(sharedApplication)]) {
return;
}
UIApplication *application = [UIApplication performSelector:@selector(sharedApplication)];
__block UIBackgroundTaskIdentifier bgTask = [application beginBackgroundTaskWithExpirationHandler:^{
// Clean up any unfinished task business by marking where you
// stopped or ending the task outright.
[application endBackgroundTask:bgTask];
bgTask = UIBackgroundTaskInvalid;
}];
// Start the long-running task and return immediately.
[self deleteOldFilesWithCompletionBlock:^{
[application endBackgroundTask:bgTask];
bgTask = UIBackgroundTaskInvalid;
}];
}
多线程
iOS中有哪些多线程方案?
常用的有三种: NSThread NSOperationQueue GCD
1、NSThread 是这三种范式里面相对轻量级的,但也是使用起来最负责的,
你需要自己管理thread的生命周期,线程之间的同步。线程共享同一应用程序的部分内存空间,
它们拥有对数据相同的访问权限。你得协调多个线程对同一数据的访问,
一般做法是在访问之前加锁,这会导致一定的性能开销。
2、NSOperationQueue 以面向对象的方式封装了用户需要执行的操作,
我们只要聚焦于我们需要做的事情,而不必太操心线程的管理,同步等事情,
因为NSOperation已经为我们封装了这些事情。
NSOperation 是一个抽象基类,我们必须使用它的子类。
3、 GCD: iOS4 才开始支持,它提供了一些新的特性,以及运行库来支持多核并行编程,
它的关注点更高:如何在多个cpu上提升效率。
总结:
- NSThread是早期的多线程解决方案,实际上是把C语言的PThread线程管理代码封装成OC代码。
- GCD是取代NSThread的多线程技术,C语法+block。功能强大。
- NSOperationQueue是把GCD封装为OC语法,额外比GCD增加了几项新功能。
* 最大线程并发数
* 取消队列中的任务
* 暂停队列中的任务
* 可以调整队列中的任务执行顺序,通过优先级
* 线程依赖
* NSOperationQueue支持KVO。这就意味着你可以观察任务的状态属性。
但是NSOperationQueue的执行效率没有GCD高,所以一半情况下,我们使用GCD来完成多线程操作。
面试题:多个网络请求完成后执行下一步?
第一种方式:使用dispatch_group
-(void)Btn2{
NSString *str = @"http://www.jianshu.com/p/6930f335adba";
NSURL *url = [NSURL URLWithString:str];
NSURLRequest *request = [NSURLRequest requestWithURL:url];
NSURLSession *session = [NSURLSession sharedSession];
dispatch_group_t downloadGroup = dispatch_group_create();
for (int i=0; i<10; i++) {
dispatch_group_enter(downloadGroup);
NSURLSessionDataTask *task = [session dataTaskWithRequest:request completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {
NSLog(@"%d---%d",i,i);
dispatch_group_leave(downloadGroup);
}];
[task resume];
}
dispatch_group_notify(downloadGroup, dispatch_get_main_queue(), ^{
NSLog(@"end");
});
}
创建一个dispatch_group_t, 每次网络请求前先dispatch_group_enter,请求回调后再dispatch_group_leave,对于enter和leave必须配合使用,有几次enter就要有几次leave,否则group会一直存在。当所有enter的block都leave后,会执行dispatch_group_notify的block。
第二种方式可以采用信号量dispatch_semaphore_t
-(void)Btn3{
NSString *str = @"http://www.jianshu.com/p/6930f335adba";
NSURL *url = [NSURL URLWithString:str];
NSURLRequest *request = [NSURLRequest requestWithURL:url];
NSURLSession *session = [NSURLSession sharedSession];
dispatch_semaphore_t sem = dispatch_semaphore_create(0);
for (int i=0; i<10; i++) {
NSURLSessionDataTask *task = [session dataTaskWithRequest:request completionHandler:^(NSData * _Nullable data, NSURLResponse * _Nullable response, NSError * _Nullable error) {
NSLog(@"%d---%d",i,i);
count++;
if (count==10) {
dispatch_semaphore_signal(sem);
count = 0;
}
}];
[task resume];
}
dispatch_semaphore_wait(sem, DISPATCH_TIME_FOREVER);
dispatch_async(dispatch_get_main_queue(), ^{
NSLog(@"end");
});
}
dispatch_semaphore信号量为基于计数器的一种多线程同步机制。如果semaphore计数大于等于1,计数-1,返回,程序继续运行。如果计数为0,则等待。dispatch_semaphore_signal(semaphore)为计数+1操作,dispatch_semaphore_wait(sema, DISPATCH_TIME_FOREVER)为设置等待时间,这里设置的等待时间是一直等待。
对于以上代码通俗一点就是,开始为0,等待,等10个网络请求都完成了,dispatch_semaphore_signal(semaphore)为计数+1,然后计数-1返回,程序继续执行。(这里也就是为什么有个count变量的原因,记录网络回调的次数,回调10次之后再发信号量,使后面程序继续运行)。
什么是dispatch_barrier_async(栅栏函数)?
dispatch_barrier_sync(dispatch_queue_t queue, ^{
})在它前面的任务执行结束后它才执行,它后面的任务要等它执行完成后才会开始执行,
避免数据竞争
sync和async
sync:同于当前线程, 可以是主线程也可以是子线程
async:就是不同于当前线程, 可以是主线程也可以是子线程
XMPP是什么?XMPP进行传输时,需要传大量的数据,如何减少数据?
XMPP:
1)XMPP 是一种基于XML的协议,XMPP是一个分散型通信网络
2)XMPP是一种基于标准通用标记语言的子集XML的协议,它继承了在XML环境中灵活的发展性,XMPP有超强的扩展性。XMPP中定义了三个角色,客户端,服务端,网关。通信能够在这个三者的任意两个之间双向发生,而他们的传输是XML流
3)XMPP工作原理:所有从一个客户端到另一个客户端的消息和数据都要通过服务端
4)XMPP允许建立并行的TCP套接字链接对所有连接上的客户端和服务器端。持久的套接字的连接使得XMPP能够更有效的支持高级的具有存在能力的应用在带宽和处理资源的使用中。
小结:
而XMPP的核心部分就是一个在网络上分片断发送XML的流协议。这个流协议是XMPP的即时通讯指令的传递基础,也是一个非常重要的可以被进一步利用的网络基础协议。所以可以说,XMPP用TCP传的是XML流。
=======
如何减少数据?
如果是大量的数据,对于XML,需要对传的信息进行简化,比如command, message中的信息要简化,
使用别的数据传输协议,比如protocol Buff(可以传输binary 二进制数据),格式可以用json
Swift问题
swift语言和OC语言的本质区别是什么?
答:本质区别是Swift是静态语言,而OC是动态语言,面试回去路上,才想到问题的最好的答案😂----
问题:子类不能重写父类的extension的方法?怎么解决呢?
解决方法如下:
//父类中
@objc extension MOBBaseViewController {
//要重写的方法
public func testExt() {
print("----------");
}
}
-----
//子类中
import UIKit
class MOBClassifyViewController: MOBBaseViewController {
override func viewDidLoad() {
super.viewDidLoad()
// Do any additional setup after loading the view.
}
//重写父类extension方法
override func testExt(){
print(">>>>>>>>>>>>")
}
}
因为extension中的方法是私有的,so子类访问不到,因此要用public修饰下,@objc有以下两点说明:
• fileprivate 或者 private 保证方法私有 能在同一个类 或者 同一个文件(extension)中访问这个方法 如果定义为private 那么只能在一个类中访问 不能在类扩展中访问
• 允许这个函数在“运行时”通过oc的消息机制调用
NSString跟Swift String的区别和使用场景
NSString和String的共同点
String保留了大部分NSString的api比如
.hasPrefix
.lowercaseString
.componentsSeparatedByString
.substringWithRange 等等
所以很多常规操作在开发中使用两者之一都是可以的,
NSString和String的不同点
NSString是引用类型。Swift String是值类型
var nsString: NSString = NSString()
var swiftString:String = String()
var nsString: NSString = "dsx"
var swiftString:String = "dsx"
两者都可以使用自己的类名来直接进行初始化,下面的方法也是初始化,虽然写法相同,但是NSString的意思是初始化了一个指针指向了这个字符串,但Swift String的意思则是把字符串字面量赋值给变量
NSString需要用append或者stringWithFormat将两个字符串拼接,Swift String只需要用 + 即可
Swift String 可以实现字符串遍历
for character in "My name is dsx".characters {
print(character)
}
计算字符串长度,NSString直接使用 字符串.length 就可以获得字符串的长度,swift真正的类似于.length的方法就是取出characters属性(数组)然后.count
比较字符串相等的方式
et strA: NSString = ""
let strB: NSString = ""
let strC: NSString = "dsx"
let strD: NSString = "dsx"
// NSString 字符串相等
if(strA.isEqualToString(strB as String)){
print("yes");
}
// String的相等
if (strC == strD){
print("yes");
}
NSString可以同基本数据类型见转化
var strA: NSString = "12306"
var strB: NSString = "0.618"
var numOfInt = strA.integerValue;
var numOfDouble = strB.doubleValue;
String可以通过isEmpty属性来判断该字符串是否为空,是string独有的
String独有的字符串插入字符功能
var strA:String = "My name is dx"
strA.insert("s", atIndex: strA.characters.indexOf("x")!);
print(strA) // My name is dsx
仅仅可以插入单个字符不能插字符串,如果里面写成ss 就会报错Cannot convert value of type 'String' to expected argument type 'Character'
作者:天下林子
链接:https://www.jianshu.com/p/1e752f5678f1
本公众号转载内容已尽可能注明出处,如未能核实来源或转发内容图片有权利瑕疵的,请及时联系本公众号进行修改或删除【联系方式QQ : 3442093904 邮箱:support@cocoachina.com】。文章内容为作者独立观点,不代表本公众号立场。版权归原作者所有,如申请授权请联系作者,因文章侵权本公众号不承担任何法律及连带责任。
---END---




