要找房,先用Python做个爬虫看看

本文为 AI 研习社编译的技术博客,原标题 :
I was looking for a house, so I built a web scraper in Python!
作者 | Fábio Neves
翻译 | Disillusion
校对 | 酱番梨 整理 | 菠萝妹
原文链接:
https://towardsdatascience.com/looking-for-a-house-build-a-web-scraper-to-help-you-5ab25badc83e
注:本文的相关链接请点击文末【阅读原文】进行访问
要找房,先用Python做个爬虫看看!

图片: trillionairesclub.net
再过几个月我就得离开我租的公寓去找一个新的了。尽管这段经历可能会很痛苦,特别是在房地产泡沫即将出现时,我决定将其作为提高Python技能的另一种激励!当一切完成时,我想做到两件事:
从葡萄牙(我居住的地方)一个主要房地产网站上搜集所有的搜索结果,建立一个数据库
使用数据库执行一些EDA,用来寻找估值偏低的房产
我将要抓取的网站是Sapo(葡萄牙历史最悠久、访问量最大的网站之一)的房地产门户。你应该能非常容易地修改代码以将其应用到其他网站。
在我们开始介绍代码片段之前,让我先将要做的事做一个概述。我将使用Sapo网站上一个简单的搜索结果页面,预先指定一些参数(如区域、价格过滤器、房间数量等)来减少任务时间,或者直接在Lisbon查询整个结果列表。
然后,我们需要使用一个命令来从网站上获得响应。结果将是一些html代码,然后我们将使用这些代码获取我们的表格所需的元素。在决定从每个搜索结果属性中获取什么之后,我们需要一个for循环来打开每个搜索页面并进行抓取。
这听上去很简单,我从哪儿开始?
与大多数项目一样,我们得导入所需模块。我将使用Beautiful Soup来处理我们将要获取的html。始终确保你试图访问的站点允许抓取。你可以通过添加“/robots.txt”到原始域来确定。在这个文件中,你可以看到哪些是允许抓取的指南。
from bs4 import BeautifulSoup
from requests import get
import pandas as pd
import itertools
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
一些网站会自动阻止任何类型的抓取,这就是为什么我将定义一个标题来传递get命令,这相当于使我们对网站的查询看起来像是来自一个实际的浏览器。当我们运行这个程序时,对页面的访问之间会有一个sleep命令,这样我们就可以模拟“更人性化”的行为,不会让网站每秒承受多个请求而过载。如果你抓取得太积极,你会被阻止访问,所以抓取的时候礼貌点是个不错的方针。
headers = ({'User-Agent':
'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36'})
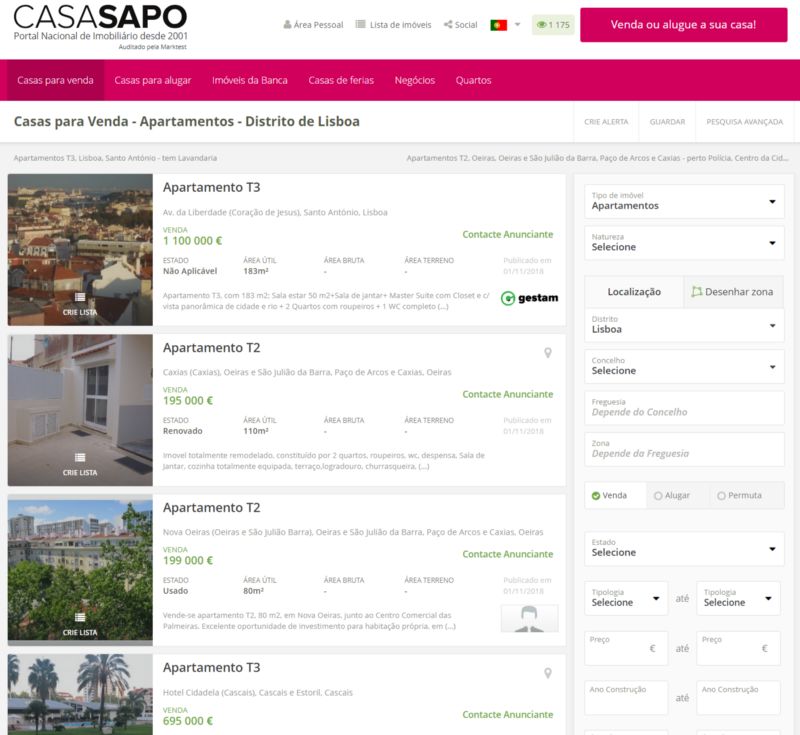
然后我们定义查询网站时使用的基本url。为此,我将搜索限制在里斯本并用创建日期排序。地址栏会快速更新,并给出参数sa=11表示里斯本, or=10表示排序,我将在sapo变量中使用这些参数。
sapo = "https://casa.sapo.pt/Venda/Apartamentos/?sa=11&or=10"
response = get(sapo, headers=headers)
casa.sapo.pt
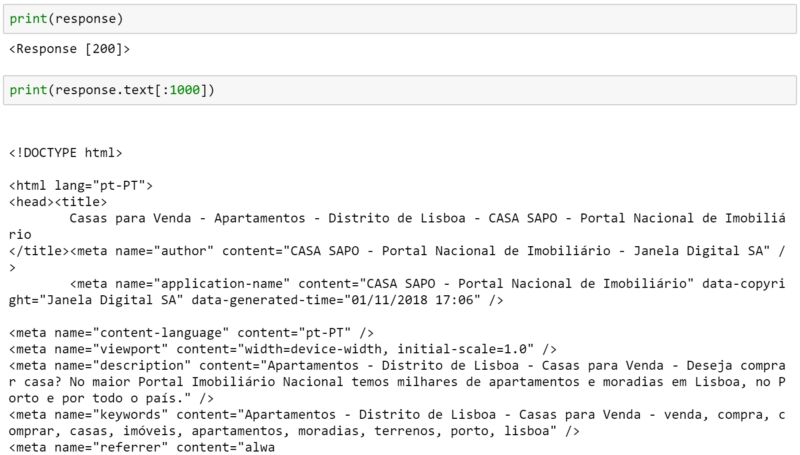
现在我们可以测试是否可以与网站通信。您可以从这个命令中获得一些代码,但如果你得到的是“200”,这通常表示你可以进行下一步了。你可以在这里看到相关代码列表。
我们可以打印响应和文本的前1000个字符。
先别害怕...看下去就会明白的!
好了,我们已经准备好开始探索我们从网站上得到的东西。我们需要定义Beautiful Soup对象,它将帮助我们阅读这个html。这就是BS所做的:它从响应中选取文本,并以一种能让我们更容易浏览结构和获取内容的方式解析信息。
是时候开工了!
html_soup = BeautifulSoup(response.text, 'html.parser')
构建web抓取工具的一个重要部分是浏览我们所抓取的web页面的源代码。上面这段文字只是整个页面的一部分。你可以通过右键单击页面并选择查看源代码(View Source Code)(我知道Chrome有这个选项,相信大多数现代浏览器都有这个功能)在浏览器中查看它。您还可以找到html文档中特定对象(如房产价格)的位置。右键单击它并选择检阅(inspect)。
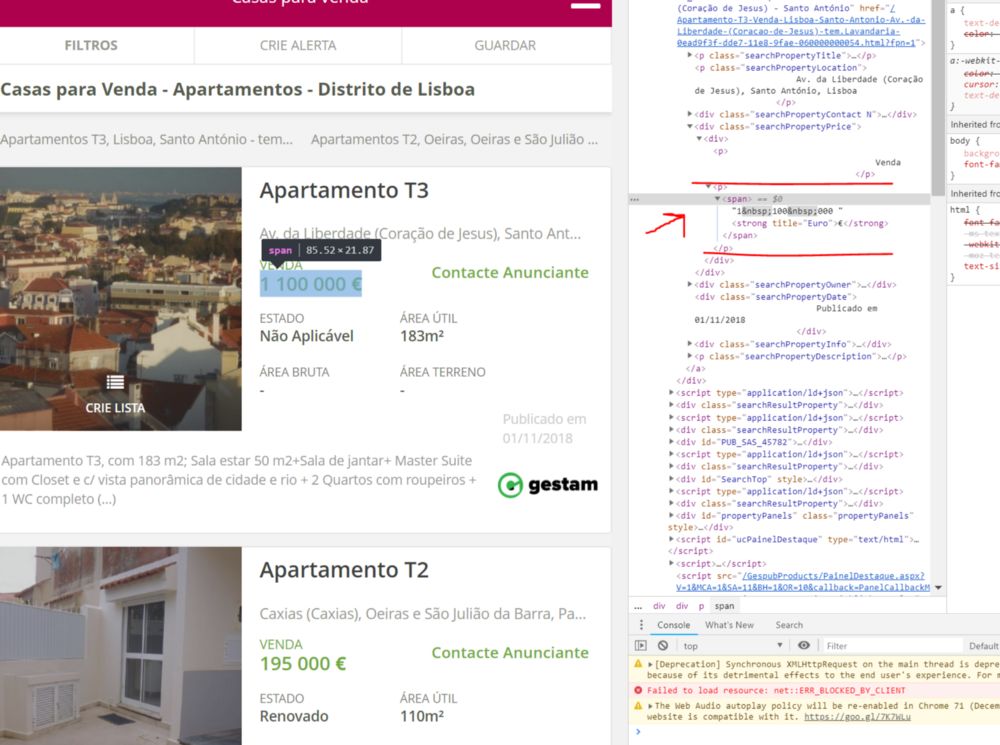
价格在标签内,但在它之前还有其他标签
如果你对html代码一无所知,不必担心。了解一些基本知识是有用的,但不是必须的!简而言之,你只需知道世界上的每个web页面都是以这种方式构建的,且它是一种基于块(block)的语言。每个块都有自己的标签来告诉浏览器如何理解它们。这是浏览器能够将表格显示为正确的表格的惟一方式,或者显示特定容器内的一段文本和另一容器内的一副图像。如果你把html代码看作一连串必须解码才能获得所需值的标签,那你应该没问题了!
在提取价格之前,我们希望能够识别页面中的每个结果。以知道我们需要调用什么标签,我们可以从价格标签一直跟踪到顶部,直到我们看到每个结果的主容器。我们可以在下图中看到:
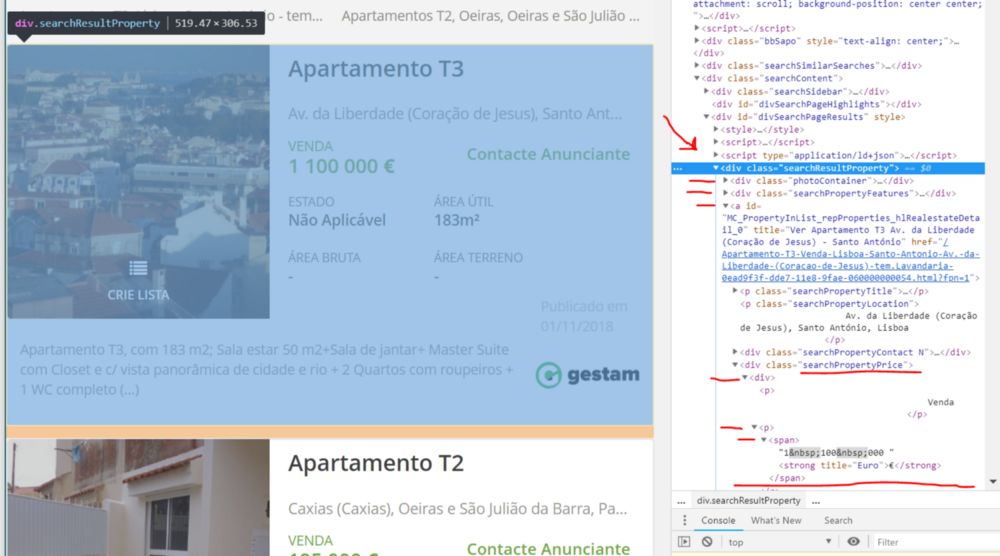
从底部的价格到包含每个结果并具有searchResultProperty类的<div>标识符
house_containers = html_soup.find_all('div', class_="searchResultProperty")
现在我们有了一个在每个搜索页面中抓取结果时可以反复的对象。让我们试着得到上图看到的价格。我将首先定义first变量,它将是我们的第一个房子(从house_containers变量中获得)的结构。
first = house_containers[0]
first.find_all('span')

价格在第3个标签中,即为索引中的位置2
所以价格是很容易得到的,但在文本中有一些特殊的字符。解决这个问题的一个简单方法是用空字符替换特殊字符。当我将字符串转换为整数时,我会对其进行分割。
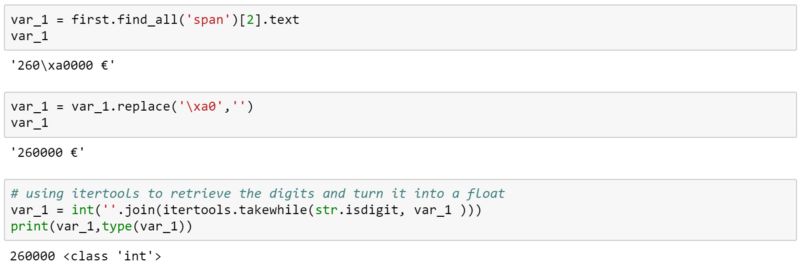
在最后一步中,itertools帮助我从提取第二步中的数字。我们刚刚抓取到了我们的第一个价格!我们想要得到的其他字段是:标题、大小、发布日期、位置、状态、简短描述、房产链接和缩略图链接。
在构建能从每个页面获得所有结果的完美for循环之前,我将在下面给出一些示例。
这些例子应该足够你自己做研究了。我仅从摆弄html结构和操作返回值以得到我想要的东西中就学到了很多。
尝试反向复制上面的代码(删除[xx:xx]和[0]部分),并检查结果以及我如何得到最终的代码。我肯定还有十几种方法可以得到同样的结果,但我也不想把它过度复杂化。

最后这两个字段不是必须的,但是我希望保留房产和图像的链接,因为我正在考虑为特定房产构建预警系统或跟踪器。也许这是一个新的项目,所以我把它留在这里只是为了示例的多样性。
玩够标签了,让我们来开始抓取页面!
一旦您熟悉了要提取的字段,并且找到了从每个结果容器中提取所有字段的方法,就可以设置爬虫的基础了。以下列表将被创建来处理我们的数据,稍后将用于组合数据框架。
# setting up the lists that will form our dataframe with all the results
titles = []
created = []
prices = []
areas = []
zone = []
condition = []
descriptions = []
urls = []
thumbnails = []
快速检查一遍最初的网页,我看到一共有871页的结果。我们可以给它们多点空间,设成900次循环。如果它找到一个没有房产容器的页面,我们将加段代码来中止循环。页面命令是地址末尾的&pn=x,其中 x 是结果页码。
代码由两个for循环组成,它们遍历每个页面中的每个房产。
如果你跟随本文,你会注意到在遍历结果时,我们只是在收集前面已经讨论过的数据。由于有以“/”分开的卖价和租金同时存在的情况,价格字段比想象中更加复杂。在一些结果中,索引2返回了“Contacte Anunciante”,因此我更新代码,添加if语句以在下一个索引位置查找价格。
%%time
n_pages = 0
for page in range(0,900):
n_pages += 1
sapo_url = 'https://casa.sapo.pt/Venda/Apartamentos/?sa=11&lp=10000&or=10'+'&pn='+str(page)
r = get(sapo_url, headers=headers)
page_html = BeautifulSoup(r.text, 'html.parser')
house_containers = page_html.find_all('div', class_="searchResultProperty")
if house_containers != []:
for container in house_containers:
# Price
price = container.find_all('span')[2].text
if price == 'Contacte Anunciante':
price = container.find_all('span')[3].text
if price.find('/') != -1:
price = price[0:price.find('/')-1]
if price.find('/') != -1:
price = price[0:price.find('/')-1]
price_ = [int(price[s]) for s in range(0,len(price)) if price[s].isdigit()]
price = ''
for x in price_:
price = price+str(x)
prices.append(int(price))
# Zone
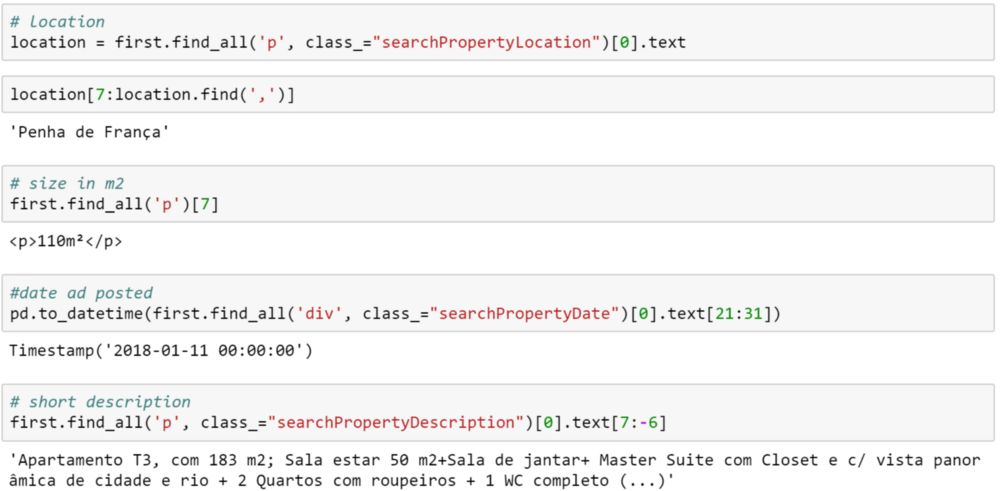
location = container.find_all('p', class_="searchPropertyLocation")[0].text
location = location[7:location.find(',')]
zone.append(location)
# Title
name = container.find_all('span')[0].text
titles.append(name)
# Status
status = container.find_all('p')[5].text
condition.append(status)
# Area
m2 = container.find_all('p')[9].text
if m2 != '-':
m2 = m2.replace('\xa0','')
m2 = float("".join(itertools.takewhile(str.isdigit, m2)))
areas.append(m2)
else:
m2 = container.find_all('p')[7].text
if m2 != '-':
m2 = m2.replace('\xa0','')
m2 = float("".join(itertools.takewhile(str.isdigit, m2)))
areas.append(m2)
else:
areas.append(m2)
# Creation date
date = pd.to_datetime(container.find_all('div', class_="searchPropertyDate")[0].text[21:31])
created.append(date)
# Description
desc = container.find_all('p', class_="searchPropertyDescription")[0].text[7:-6]
descriptions.append(desc)
# url
link = 'https://casa.sapo.pt/' + container.find_all('a')[0].get('href')[1:-6]
urls.append(link)
# image
img = str(container.find_all('img')[0])
img = img[img.find('id=')-2]
thumbnails.append(img)
else:
break
sleep(randint(1,2))
print('You scraped {} pages containing {} properties.'.format(n_pages, len(titles)))
最后我添加了sleep命令,以便在每个页面之间等待1到2秒。

记住,你不需要抓取整整871页。您可以在循环中更改变量sapo_url以包含特定的过滤器。只需在浏览器中执行你想要的过滤器并进行搜索。地址栏将刷新并显示带有过滤器的新url。在我上图贴出的循环中,我实际上将结果限制在价格高于10,000欧元(&lp= 10,000)的范围内。
最后一个转换
现在,我们应该将所有这些变量保存在一个数据结构(dataframe)中,这样我们就可以将其保存为csv或excel文件,并在以后访问它,而不必重复上述过程。
我会为这些列定义名称,并将所有内容合并到一个数据结构(dataframe)中。我在最后加上[cols]这样列就按这个顺序出来了。
cols = ['Title', 'Zone', 'Price', 'Size (m²)', 'Status', 'Description', 'Date', 'URL', 'Image']
lisboa = pd.DataFrame({'Title': titles,
'Price': prices,
'Size (m²)': areas,
'Zone': zone,
'Date': created,
'Status': condition,
'Description': descriptions,
'URL': urls,
'Image': thumbnails})[cols]
lisboa.to_excel('lisboa_raw.xls')
# lisboa = pd.read_excel('lisboa_raw.xls')
稍后,我们可以用最后一行代码来读取数据。现在,由于我不想把这篇文章写得太大,我将把探索性分析留到以后的文章中讨论。我们抓取了超过2万的房产,现在有了一个原始数据集!还有一些数据清洗和预处理工作要做,但我们已经完成了复杂的部分。
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1203
AI研习社每日更新精彩内容,观看更多精彩内容:
用Python实现遗传算法
如何将深度学习应用于无人机图像的目标检测
机器学习和深度学习大PK!昆虫分类谁更强?
Python高级技巧:用一行代码减少一半内存占用
等你来译:
五个很厉害的 CNN 架构
状态估计:卡尔曼滤波器
如何在神经NLP处理中引用语义结构
让神经网络说“我不知道”——用Pyro/PyTorch实现贝叶斯神经网络
◆◆ 敲黑板,划重点啦! ◆◆
【AI求职百题斩】已经悄咪咪上线啦,点击下方小程序卡片,开始愉快答题吧!

点击 阅读原文 查看本文更多内容↙




