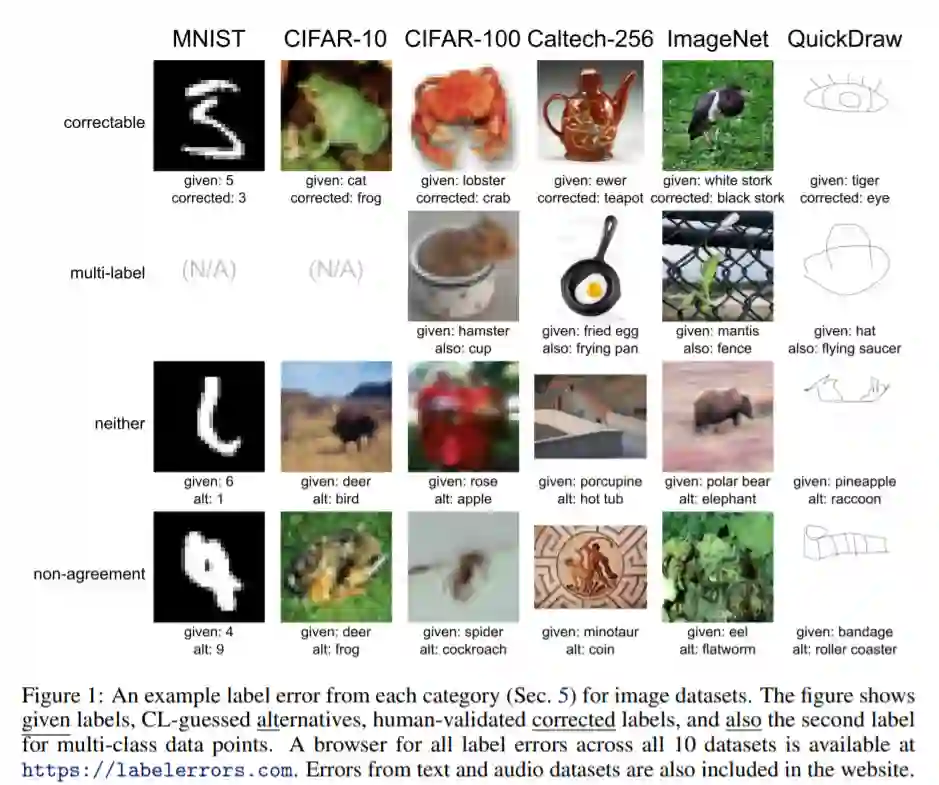
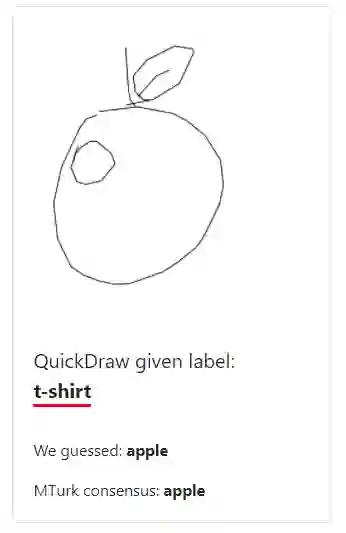
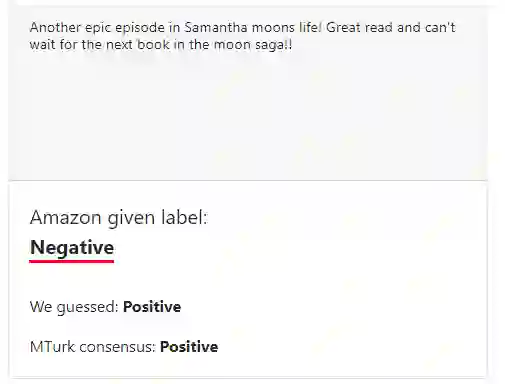
把老虎标成猴子,把青蛙标成猫,把码头标成纸巾……MIT、Amazon 的一项研究表明,ImageNet 等十个主流机器学习数据集的测试集平均错误率高达 3.4%。
![]()
我们平时用的机器学习数据集存在各种各样的错误,这是一个大家都已经发现并接受的事实。为了提高模型准确率,有些学者已经开始着手研究这些数据集中的错误,但他们的研究主要集中在训练集,没有人系统研究过机器学习测试集的误差。
众所周知,测试集是我们拿来衡量机器学习模型性能的基准。如果测试集错误百出,我们得到的性能数据也会存在很大偏差。
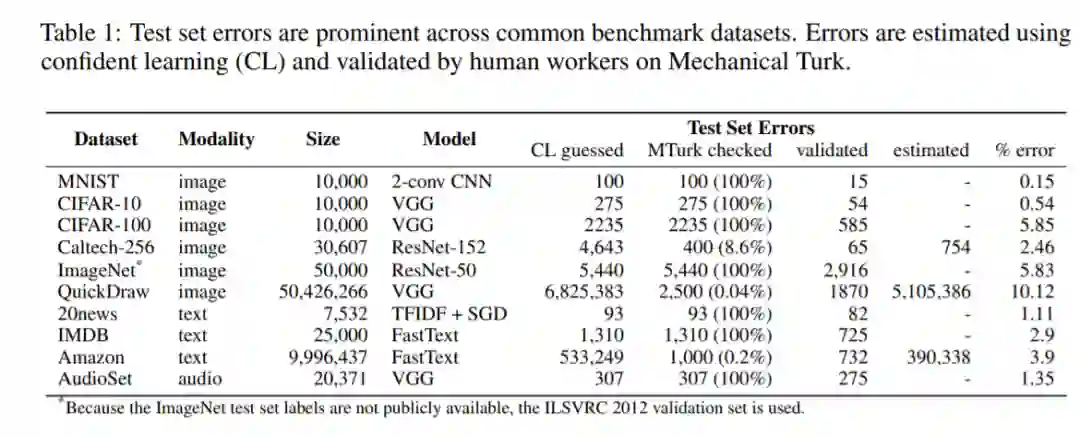
在一篇新论文中,麻省理工 CSAIL 和亚马逊的研究者对 10 个主流机器学习数据集的测试集展开了研究,发现它们的平均错误率竟高达 3.4%。其中,最有名的 ImageNet 数据集的验证集中至少存在 2916 个错误,错误率为 6%;QuickDraw 数据集中至少存在 500 万个错误,错误率为 10%。
![]()
论文链接:
https://arxiv.org/pdf/2103.14749.pdf
![]()
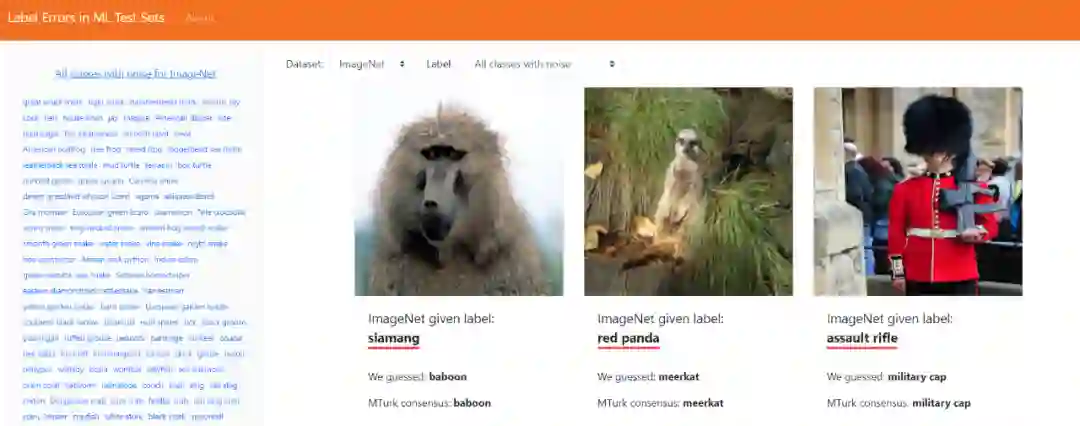
为了向所有人展示这些错误,帮助改进数据集,研究者还做了一个专门的归类网站。
![]()
网站地址:https://labelerrors.com/
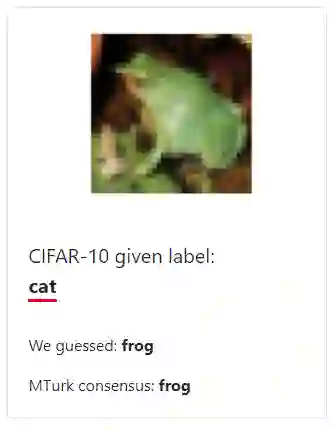
该网站列出的错误主要包括三种类型。第一种是标错的图像,如码头被标记成纸巾。
![]()
第二种是被标错的文本情感倾向,如亚马逊的商品评价本来是消极的,但被标成积极的。
第三种是被标错的 YouTube 视频的音频,如爱莉安娜 · 格兰德的高音片段被标记成口哨。
论文作者在研究中发现了一个有趣的现象:ResNet-18 这类比较简单的模型错误率要低于 ResNet-50 这种更为复杂的模型,这取决于不相关数据(噪声)的普遍性。因此,作者建议,如果你的数据集标签错误率高达 10%,你可以考虑使用较为简单的模型。
为了方便大家复现论文结果并在自己的数据集中找到标签错误,研究者还在 GitHub 上开源了他们用到的 Python 包(cleanlab)。
![]()
项目地址:
https://github.com/cgnorthcutt/cleanlab
下表一显示了研究者本次调查的十个数据集以及它们的测试集错误率。
![]()
以下是这些数据集的详细信息,从它们的标注过程我们看出标签出错的一些可能原因:
MNIST 数据集是是美国国家标准与技术研究院收集整理的大型手写数字数据库,最早是在 1998 年 Yan Lecun 的论文中提出的。该数据集包含了 0-9 共 10 类手写数字图片,每张图片都做了尺寸归一化,都是 28x28 大小的灰度图。该数据集的 ground-truth 标签是通过将数字与任务的指令相匹配来确定的,以便于复制一组特定的数字。标签错误可能是由于未遵循该数据集的相关说明和手写歧义引起的。
![]()
CIFAR-10 和 CIFAR-100 数据集分别由 10 类和 100 类 32 × 32 图像组成。这两个数据集通过在互联网上搜索类别标签来收集图像。人工标记时通过过滤掉标签错误的图像,来选择与类别标签匹配的图像。标记器仅根据图像中最突出的一个实例来赋予标签,其中允许该实例有部分遮挡。
![]()
Caltech-256 数据集是一种包含图像和类别的数据集,其中的图像是从图像搜索引擎中抓取的,人工标记时将图像评定为 good、bad 和 not applicable,从数据集中过滤掉遮挡过度、混乱,以及非物体类别示例的图像。
![]()
ImageNet 数据集是机器学习研究中最常用的数据集之一。该数据集通过在几个图像搜索引擎上查询 WordNet 同义词集(synset)中的单词来抓取图像。这些图像由 Amazon Mechanical Turk 的工作人员标记,他们要检查这些图像是否包含特定同义词集中的对象,过滤掉对象混乱、遮挡过度的图像,并确保数据集的图像多样性。
![]()
QuickDraw 涂鸦数据集是一个包含 5000 万张图画的集合,分成了 345 个类别,这些图画都来自于 Quick, Draw! 游戏的玩家。这些图像带有一些元数据标注,包括玩家被要求绘画的内容等。该数据集可能存在图像不完整、标签不匹配等情况。
![]()
20 Newsgroups 数据集是由发布到 Usenet 新闻组的文章的集合,一共涉及 20 种话题。该数据集常被用于对文本分类和聚类图像模型进行基准测试。其中每个样本的标签是最初发布的新闻组(例如 misc.forsale),该标签可以在数据收集过程中获得。
IMDB 大型影评数据集是情感分类数据集,用于二元情感分类。其中的标签是由用户的评价决定的:满分 10 分,分数≤ 4 被视为否定,分数≥ 7 被视为肯定。
![]()
评价中表示这是一部值得看的作品,但 IMDB 数据集给出的标签是负面的。
Amazon Reviews 数据集是来自亚马逊客户的文本评价和 5 星级评级的集合,通常被用于基准情感分析模型。
AudioSet 数据集包含 632 类音频类别以及 2084320 条人工标记的每段 10 秒长度的声音剪辑片段(片段来自 YouTube 视频),被称为声音版 ImageNet。研究者指出一些标签错误是因为标签混乱、人为错误以及音频检测差异造成的。
在估计了各个测试集的错误率之后,研究者利用 ImageNet 和 CIFAR-10 作为案例研究了测试集标签错误对基准稳定性造成的影响。
虽然这些基准测试数据中存在很多错误标签,但研究者发现,在移除或修正这些错误之后,基准中的模型相对排名并没有受到影响。但他们也发现,这些基准结果是不稳定的:与参数较少的模型(如 ResNet-18)相比,容量较大的模型(如 NasNet)在预测结果中更加能够反映这些系统性标签错误的分布,而且这种效应随着测试标签错误普遍性的增加而变得更加明显。
这不是传统的过拟合。更大的模型能够更好地泛化至测试数据中给定的噪声标签,但这是有问题的,因为在标签修正之后的测试数据上进行评估时,这些模型给出的预测结果比不上那些容量较小的模型。
在存在大量标注错误的现实世界数据集中,小容量模型可能比大容量模型更有用。举个例子,从基于原始给定标签的测试准确率来看,NasNet 似乎要优于 ResNet-18,但如果用标签修正之后的测试集进行测试,NasNet 的准确率其实比不上 ResNet-18。由于后者在现实中更为重要,在这种情况下,我们在现实中部署的也应该是 ResNet-18,而不是 NasNet。
为了评估流行预训练模型的基准如何变化,研究者随机并递增地删除正确标记样本,每次删除一个,直到只剩下一组原始的被错误标记的测试数据(标签得到纠正)。借助这种方法,他们只删除了 6% 的正确标记测试样本就让 ResNet-18 的表现超越了 ResNet-50。
该研究表明,如果着手纠正测试集中的标签错误或在数据集噪声较多时使用较小 / 较简单的模型,ML 从业者可能会从中受益。当然,你首先要确定你的数据集噪声是不是真的有那么大,判断方法可以在论文中找到。
参考链接:https://www.csail.mit.edu/news/major-ml-datasets-have-tens-thousands-errors
中文NLP:2021海华AI挑战赛火热报名中!
由海华研究院与清华大学交叉信息研究院联合主办的“2021海华AI挑战赛·中文阅读理解”正在进行,上届决赛答辩仪式,姚期智院士为大家深情致辞,所有获奖选手也都收到了姚先生亲笔签名的证书。
本届大赛依然保留中学组及技术组两条赛道,共设30万元奖金池,诗词AI,智慧中文,点击阅读原文或立即扫码报名!
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com