【AAAI2021】长文本的上下文推理

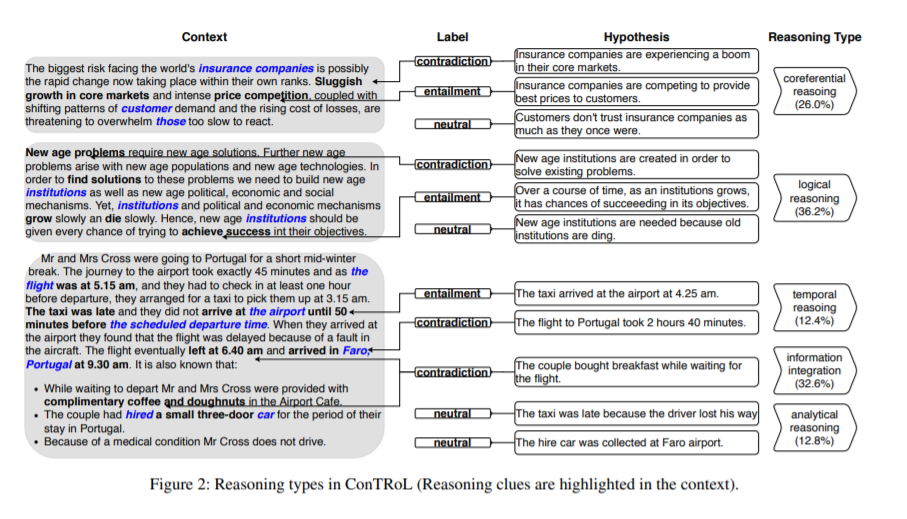
自然语言推理(NLI)是自然语言处理的一项基本任务,主要研究两个文本之间的蕴含关系。流行的NLI数据集是对该任务句子级别的研究。它们可以用来探讨语义表示,但并未涉及基于长文本的上下文推理,而这是人类推理过程的自然组成部分。我们提出了ConTRoL数据集来用于研究长文本的上下文推理。ConTRoL由8,325个专家设计的带有高质量标签的“上下文-假设”对组成,是一个段落级别的NLI数据集,重点关注复杂的上下文推理类型,例如逻辑推理。它是从竞争性甄选和招聘测试(推理测试)衍生而来的,具有很高的质量。与以前的NLI基准相比,ConTRoL中的材料更具挑战性,涉及多种推理类型。
实证结果表明,最先进的语言模型在ConTRoL上的性能表现远不如受过良好教育的人类。我们的数据集还可以用作下游任务(如检查摘要的事实正确性)的测试集。
https://www.zhuanzhi.ai/paper/0de7d36e358d3792f72bf4d41e2078ee
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“NLIC” 可以获取《【AAAI2021】长文本的上下文推理》专知下载链接索引



登录查看更多
相关内容
Arxiv
6+阅读 · 2020年2月25日




相关VIP内容
相关资讯
相关论文
Arxiv
6+阅读 · 2020年2月25日