业界 | 详解Horovod:Uber开源的TensorFlow分布式深度学习框架
选自Uber
作者:Alex Sergeev、Mike Del Balso
机器之心编译
参与:李泽南、路雪
Horovod 是 Uber 开源的又一个深度学习工具,它的发展吸取了 Facebook「一小时训练 ImageNet 论文」与百度 Ring Allreduce 的优点,可为用户实现分布式训练提供帮助。本文将简要介绍这一框架的特性。
近年来,深度学习引领了图像处理、语音识别和预测等方面的巨大进步。在 Uber,我们将深度学习应用到了公司业务中,从自动驾驶搜索路线到防御欺诈,深度学习让我们的数据科学家和工程师们能够为用户提供更好的体验。
TensorFlow 已经成为了 Uber 首选的深度学习库。因为这个框架是目前使用最为广泛的开源深度学习框架,对于新的开发者而言非常友好。它结合了高性能与低级模型细节调试能力——例如,我们可以使用 Keras 这种高级 API,同时使用自己定制的 Nvidia CUDA 工具。此外,TensorFlow 还为各种深度学习用例提供了端到端支持,从进行实验性探索到将生产级模型部署到云服务器、移动端 APP、甚至自动驾驶汽车上。
上个月 Uber 工程部门推出了 Michelangelo——一个内部机器学习服务平台,可以让机器学习轻松部署到大规模系统中。在本文中 Uber 介绍了 Michelangelo 深度学习工具包的重要开源组件 Horovod,它可以让分布式 TensorFlow 深度学习项目更加轻松地实现。
面向分布式
随着 Uber 在 TensorFlow 上训练越来越多的机器学习模型,项目的数据和计算能力需求正在急剧增加。在大部分情况下,模型是可以在单个或多 GPU 平台的服务器上运行的,但随着数据集的增大和训练时间的增长,有些时候训练需要一周甚至更长时间。因此,Uber 的工程师们不得不寻求分布式训练的方法。
Uber 开始尝试部署标准分布式 TensorFlow 技术,在试验了一些方法之后,开发者意识到原有方法需要进行一些调整:首先,在遵循文档和代码示例之后,我们并不总是清楚哪些功能对应着哪些模型训练代码的分布式计算。标准分布式 TensorFlow 引入了很多新的概念:工作线程、参数服务器、tf.Server()、tf.ClusterSpec()、 tf.train.SyncReplicasOptimizer() 以及 tf.train.replicas_device_setter() 等等。它们在某些情况下能起到优化作用,但也让我们难以诊断拖慢训练速度的 bug。
第二个问题有关 Uber 规模的计算性能。在进行了一些基准测试之后,我们发现标准的分布式 TensorFlow 机制无法满足需求。例如,在使用 128 个 GPU 进行训练时,我们因为低效率损失了一半的计算资源。
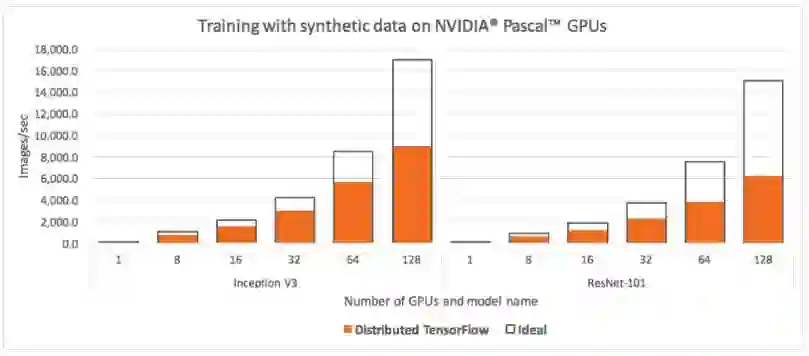
图 1. 标准 TensorFlow 基准套件,使用英伟达 Pascal GPU(从 1 块到 128 块)运行 Inception V3 和 ResNet-101 模型,与理想状态下的分布式计算(单 GPU 算力简单叠加)每秒处理的图像数量对比。从中我们发现标准方法很难释放出硬件的全部潜能。
当我们使用标准 TensorFlow 基准测试套件在 128 块英伟达 Pascal GPU 上进行测试时(如图 1 所示),无论是 Inception V3 还是 ResNet-101 都浪费了将近一半 GPU 算力。
充分利用 GPU 资源是目前大规模训练的一大课题,此前 Facebook 的一小时训练 ImageNet 论文《Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour》介绍了使用 256 块 GPU 进行 ResNet-50 网络「数据并行」训练的方法,引起人们的广泛关注,这也证明了大规模分布式训练可以显著提高生产力。
利用不同类型的算法
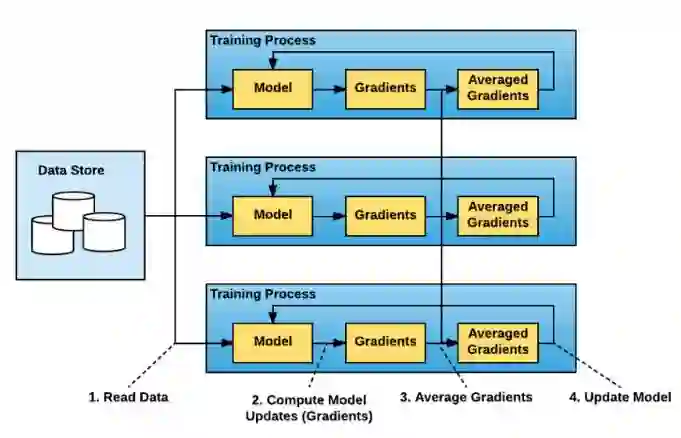
图 2.「数据并行」方法在分布式训练上包含在多节点上并行分割数据和训练。在同步情况下,不同批次数据的梯度将在不同节点上分别进行计算,但在节点之间进行互相平均,以对每个节点中的模型副本应用一致化更新。
在 Facebook 的研究之后,Uber 的研究人员开始寻找更好的分布式 TensorFlow 模型训练方法。由于我们的模型小到可以在单个 GPU 或多 GPU 的单服务器上运行,我们开始尝试使用 Facebook 的数据并行方法。
在概念上,数据并行的分布式训练方法非常直接:
1. 运行训练脚本的多个副本,每个副本:
a)读取数据块
b)将其输入模型
c)计算模型更新(梯度)
2. 计算这些副本梯度的均值
3. 更新模型
4. 重复 1a 步骤
标准分布式 TensorFlow 包使用参数服务器的方法来平均梯度。在这种方法之下,每个进程都有一到两个角色:工作线程或参数服务器。工作线程处理训练数据,计算梯度,并把它们传递到参数服务器上进行平均。
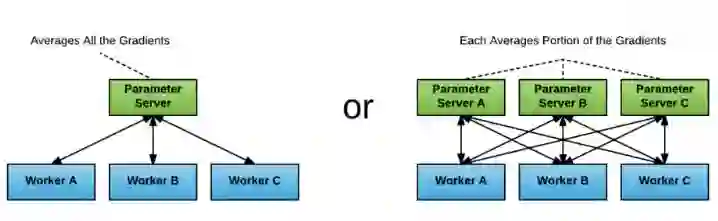
图 3. 分布式训练中的参数服务器可以按照不同比例的参数服务器和工作线程进行配置,每一个都有着不同的配置数据。
尽管这种方法可以提升表现,但我们仍然面临两大挑战:
确定工作线程与参数服务器的正确比例:一旦使用参数服务器,它就可能变成网络或计算的瓶颈。如果使用多个参数服务器,通信模式就会变成「all-to-all」的状态,网络可能会很快饱和。
应对不断增加的 TensorFlow 程序复杂性:在测试中我们发现,每个使用分布式 TensorFlow 的案例都需要指定初始工作线程和参数服务器,传递服务发现信息,如所有工作线程和参数服务器的主机和端口,并使用合适的 tf.ClusterSpec() 构建 tf.Server(),进而调整训练程序。此外,用户必须保证所有的操作都正确地使用 tf.train.device_replica_setter(),并使用 towers 让代码符合服务器中多 GPU 的设置。这通常导致陡峭的学习曲线和大量的代码重构,压缩了实际建模的时间。
在 2017 年上半年,百度发表了研究《Bringing HPC Techniques to Deep Learning》(参见百度将 HPC 引入深度学习:高效实现模型的大规模扩展),提出使用不同的算法来平均梯度,并让这些梯度在所有节点之间交流,这被称为 ring-allreduce,他们使用 TensorFlow 也实现了这种算法(https://github.com/baidu-research/tensorflow-allreduce)。该算法的思路基于 2009 年 Patarasuk 与 Xin Yuan 的论文《Bandwidth Optimal All-reduce Algorithms for Clusters of Workstations》。
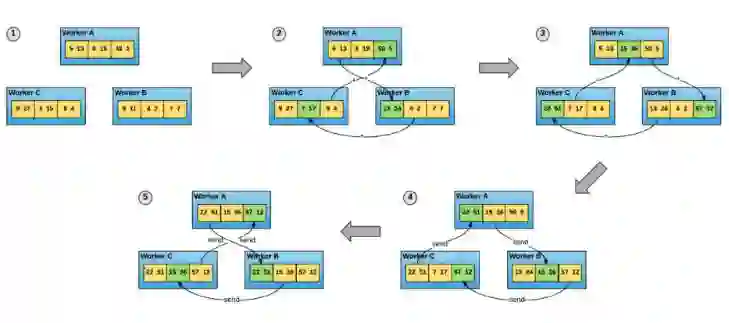
图 4. ring-allreduce 算法允许工作线程节点平均梯度并将其分散到所有节点——无需参数服务器。
在 ring-allreduce 算法中,每个 N 节点与其他两个节点进行 2*(N-1) 次通信。在这个通信过程中,一个节点发送并接收数据缓冲区传来的块。在第一个 N-1 迭代中,接收的值被添加到节点缓冲区中的值。在第二次 N-1 迭代中,接收的值代替节点缓冲区中保存的值。百度的文章证明了这种算法是带宽上最优的,这意味着如果缓冲区足够大,它将最大化地利用可用的网络。
除了网络最优化,allreduce 方法也易于理解和应用。用户可以利用消息传递接口(Message Passing Interface,MPI)实现,如 Open MPI,来启动 TensorFlow 程序的所有副本。MPI 明确地建立了在分布式条件下工作线程互相通信的范式。用户需要使用 allreduce() 来调整自己的程序以平均梯度。
Horovod 简介
意识到 ring-allreduce 方法能够改善易用性和性能,这激励我们继续研究适合我们的实现,以满足 UberTensorFlow 的需求。我们采用了百度的 TensorFlow ring-allreduce 算法实现,并在此基础上进行构建。流程如下:
1. 我们将代码转换成独立的 Python 包 Horovod,它的名字来自于俄国传统民间舞蹈,舞者手牵手围成一个圈跳舞,与分布式 TensorFlow 流程使用 Horovod 互相通信的场景很像。Uber 的不同团队可能使用不同版本的 TensorFlow。我们希望所有团队无须更新到 TensorFlow 最新版,就可以利用 ring-allreduce 算法,使用补丁,甚至构建框架。拥有独立的 Python 包使安装 Horovod 的时间从一个小时缩减至几分钟,时间长短取决于硬件条件。
2. 我们用 NCCL 替换百度的 ring-allreduce 实现。NCCL 是英伟达的集合通信库,提供高度优化的 ring-allreduce 版本。NCCL 2 允许在多个机器之间运行 ring-allreduc,这使得我们利用其多种性能提升优化。
3. 我们支持模型适应单个服务器和多个 GPU,原始版本只支持单个 GPU 模型。
4. 最后,我们根据大量初始用户的反馈对 API 进行了多处改进。特别是,我们实现了广播操作,使模型在所有工作线程中实现一致性初始化。新的 API 允许我们将用户在单个 GPU 项目中的运算量减少到 4。
接下来,我们将讨论如何在团队中使用 Horovod 进行机器学习。
使用 Horovod 分配训练任务
分布式 TensorFlow 的参数服务器模型(parameter server paradigm)通常需要对大量样板代码进行认真的实现。但是 Horovod 仅需要几行。下面是一个分布式 TensorFlow 项目使用 Horovod 的示例:
tensorflow as tf
import horovod.tensorflow as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per process)
config = tf.ConfigProto()
config.gpu_options.visible_device_list = str(hvd.local_rank())
# Build model…
loss = …
opt = tf.train.AdagradOptimizer(0.01)
# Add Horovod Distributed Optimizer
opt = hvd.DistributedOptimizer(opt)
# Add hook to broadcast variables from rank 0 to all other processes during
# initialization.
hooks = [hvd.BroadcastGlobalVariablesHook(0)]
# Make training operation
train_op = opt.minimize(loss)
# The MonitoredTrainingSession takes care of session initialization,
# restoring from a checkpoint, saving to a checkpoint, and closing when done
# or an error occurs.
with tf.train.MonitoredTrainingSession(checkpoint_dir=“/tmp/train_logs”,
config=config,
hooks=hooks) as mon_sess:
while not mon_sess.should_stop():
# Perform synchronous training.
mon_sess.run(train_op)
在该示例中,粗体文字指进行单个 GPU 分布式项目时必须做的改变:
hvd.init() 初始化 Horovod。
config.gpu_options.visible_device_list = str(hvd.local_rank()) 向每个 TensorFlow 流程分配一个 GPU。
opt=hvd.DistributedOptimizer(opt) 使用 Horovod 优化器包裹每一个常规 TensorFlow 优化器,Horovod 优化器使用 ring-allreduce 平均梯度。
hvd.BroadcastGlobalVariablesHook(0) 将变量从第一个流程向其他流程传播,以实现一致性初始化。如果该项目无法使用 MonitoredTrainingSession,则用户可以运行 hvd.broadcast_global_variables(0)。
之后,用户可以使用 mpirun 命令使该项目的多个拷贝在多个服务器中运行:
$ mpirun -np 16 -x LD_LIBRARY_PATH -H
server1:4,server2:4,server3:4,server4:4 python train.py
mpirun 命令向四个节点分布 train.py,然后在每个节点的四个 GPU 上运行 train.py。
Horovod 还通过同样的步骤分布 Keras 项目。(TensorFlow 和 Keras 的脚本示例地址:https://github.com/uber/horovod/blob/master/examples/)
Horovod 的易用性、调试效率和速度使之成为对单 GPU 或单服务器项目感兴趣的工程师和数据科学家的好搭档。下面,我们将介绍 Horovod Timeline,它在分布式训练工作中提供对工作线程节点状态的高度理解。
Horovod Timeline
我们在允许用户使用 Horovod 时,就意识到需要向用户提供一种能够轻松识别代码中 bug 的方式,这也是处理复杂分布式系统时常常面临的问题。尤其是,由于用户需要收集和交叉引用不同服务器上的文件,用户很难使用原始的 TensorFlow timeline 或 CUDA 分析器。
我们希望用 Horovod 创造一种方式,提供节点之间操作 timeline 的高度理解。因此,我们构建了 Horovod Timeline。用户可以使用 Horovod Timeline 清晰看到每个节点在训练过程的每个时间步的状态。这有助于识别 bug,解决性能问题。用户可通过设置单个环境变量启用 timeline,通过 chrome://tracing 在浏览器中查看分析结果。
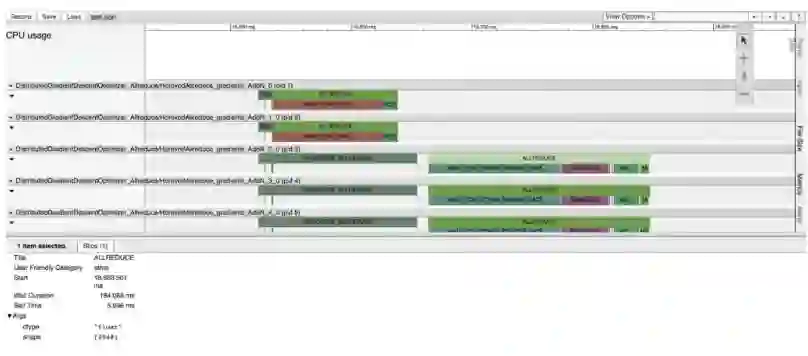
图 5:Horovod Timeline 在 Chrome 的事件追踪性能分析工具(trace event profiling tool)中描述分布式训练过程中的高级别 timeline。
Tensor Fusion
我们分析了多个模型的 timeline 之后,发现具有大量张量的模型,如 ResNet-101,有很多小的 allreduce 操作。之前我们注意到,ring-allreduce 在张量足够多的情况下可以最大化利用网络,但工作效率和速度都不如张量少的情况。于是问题来了:如果在张量上执行 ring-allreduce 之前,先融合多个小张量,会发生什么呢?
答案就是:Tensor Fusion,一种在执行 Horovod 的 ring-allreduce 之前先融合张量的算法。我们使用该方法进行实验,发现在未优化的传输控制协议(TCP)网络上运行的多层模型性能提升了 65%。我们简要介绍了 Tensor Fusion 的使用方法:
1. 确定要减少哪些向量。首先选择几个在缓冲区(buffer)中适用且具备同样的数据类型的张量。
2. 为未分配的张量分配融合缓冲区(fusion buffer)。默认的融合缓冲区大小是 64 MB。
3. 将所选张量的数据复制到融合缓冲区。
4. 在融合缓冲区上执行 allreduce 操作。
5. 将融合缓冲区中的数据复制到输出张量中。
6. 重复直到该循环中没有需要减少的张量。
我们使用 Horovod、Tensor Fusion 和在 Michelangelo 平台上构建的其他特征,提高模型在我们的机器学习系统中的效率、速度和易用性。下一部分,我们将分享现实世界的基准,来展示 Horovod 的性能。
Horovod 基准
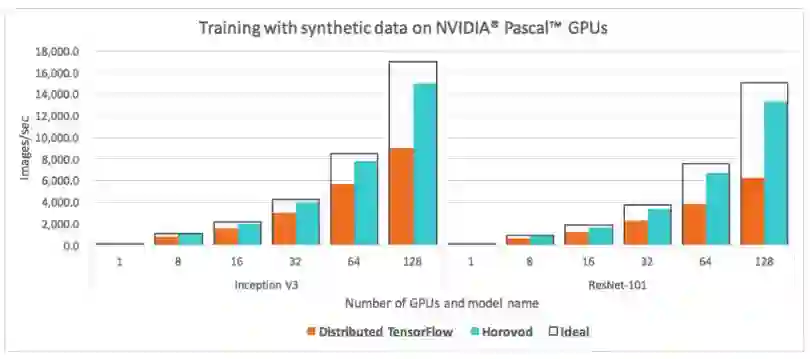
图 6:Inception V3 和 ResNet-101 TensorFlow 模型在 25GbE TCP 上使用不同数量的 NVIDIA Pascal GPU 时,使用标准分布式 TensorFlow 和 Horovod 运行分布式训练工作每秒处理的图像数量对比。
我们重新运行调整后适合 Horovod 的官方 TensorFlow 基准,并与常规的分布式 TensorFlow 的性能进行对比。如图 6 所示,Horovod 的能力有大幅改进,我们不再浪费一半的 GPU 资源。事实上,使用 Inception V3 和 ResNet-101 模型进行缩放可以达到 88% 的计算效率。也就是说,训练速度是标准分布式 TensorFlow 的两倍。
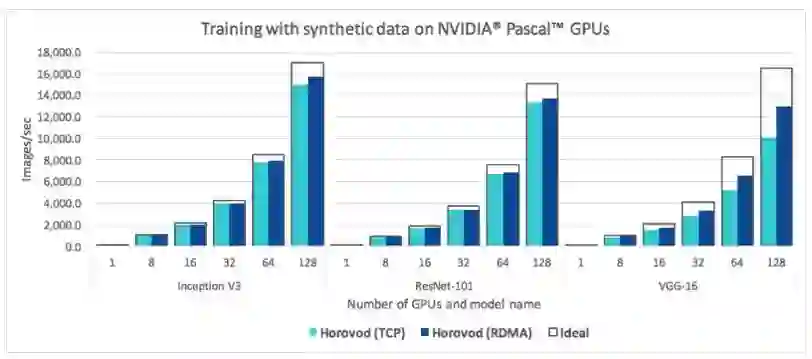
图 7:Horovod 在 25GbE TCP 和 25GbE RDMA 网络上每秒处理的图像对比。它们在不同数量的 NVIDIA Pascal GPU 上为 Inception V3、ResNet-101 和 VGG-16 运行分布式训练工作。
由于 MPI 和 NCCL 都支持远程直接内存访问(RDMA)网络,我们使用 RDMA 网卡运行额外的基准测试,来确定它们提升的效率是否能够超过 TCP 网络。
我们发现 RDMA 没有明显提升 Inception V3 和 ResNet-101 模型上的性能,仅比 TCP 网络提高了三四个百分点。但是,RDMA 帮助 Horovod 在两个模型上实现了超过 90% 的缩放效率(scaling efficiency)。
与此同时,VGG-16 模型在使用 RDMA 网络时速度提升了 30%。这可以用 VGG-16 的大量模型参数来解释,全连接层和少量层的结合引起大量模型参数。这些特征改变了从 GPU 计算到通信的关键路径,造成了网络瓶颈。
这些基准说明 Horovod 在 TCP 和 RDMA 网络上的缩放效果很好,尽管使用 RDMA 网络的用户能够在使用大量模型参数的模型如 VGG-16 时才能获取最优性能和显著效率提升。
我们使用 Horovod 探索深度学习中的性能优化还只是开始。未来,我们将持续利用开源社区使用我们的机器学习系统和框架实现性能提升。
下一步
今年早些时候,Uber 开源了 Horovod,让这一可扩展机器学习模型走向整个社区。目前 Horovod 还在发展之中,我们正在向以下几个方向继续推进:
1. 让 MPI 更易安装:虽然在工作站上安装 MPI 比较容易,但是在集群上安装 MPI 仍然需要一些努力;例如,有很多工作负载管理器,我们需要根据不同的硬件进行相应的调整。我们正在开发为集群运行 Horovod 的参考设计,为此,我们希望与 MPI 社区和网络硬件供应商合作,开发安装 MPI 和相关驱动程序的说明。
2. 收集和分享调整分布式深度学习模型参数的心得:Facebook 的「一小时训练 ImageNet 论文」描述了与在单 GPU 上训练模型相比,分布式训练任务需要超参数调整以达到甚至超越前者的准确性。Facebook 证明了在 256 块 GPU 上训练 TensorFlow 模型的可行性。
3. 加入超大模型示例:Horovod 目前支持适用于单 GPU,同时也支持多 GPU 服务器的模型。我们希望在更多形式的硬件上应用更大的模型。
我们希望 Horovod 的简洁性可以使大家采用分布式训练,更好地利用计算资源用于深度学习。
原文地址:https://eng.uber.com/horovod/
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com



