年龄估计技术综述
AI综述专栏简介
在科学研究中,从方法论上来讲,都应先见森林,再见树木。当前,人工智能科技迅猛发展,万木争荣,更应系统梳理脉络。为此,我们特别精选国内外优秀的综述论文,开辟“综述”专栏,敬请关注。
年龄估计(Age Estimation),即提供一张图片,自动识别出图中人物的年龄。这项技术有很多应用,如视频监控、产品推荐、人机交互、市场分析、用户画像、年龄变化预测(age progression)等。
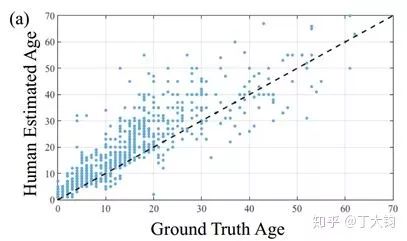
使用算法进行年龄估计是一个比较困难的任务,人脸年龄与头骨形状、五官位置、皱纹等都有一定关系,而且会受到光照、姿态、表情等的影响【1】。据下图所示,即使是人类对年龄的观察估计也会有很大偏差【2】。
本文主要分为两个部分:年龄估计典型算法介绍和数据集介绍。
其中算法部分将用以下五篇论文为例,对年龄估计算法进行介绍。
1. Age and Gender Classification using Convolutional Neural Networks (2014)
2. DEX: Deep EXpectation of apparent age from a single image (2015)
3. Ordinal Regression with Multiple Output CNN for Age Estimation (2016)
4. Quantifying Facial Age by Posterior of Age Comparisons (2017)
5. SSR-Net: A Compact Soft Stagewise Regression Network for Age Estimation (2018)
数据集介绍部分将对FG-NET、MORPH2、Adience、CACD、LAP、IMDB-WIKI、AFAD、MegaAge等8个年龄数据集进行介绍。
年龄估计典型算法介绍
年龄估计领域论文的大致有以下几类:用输入图片直接进行分类或回归;使用预测值与概率相乘求期望;引入排序和概率分布信息等。我们将用以下五篇论文为例,以时间顺序对算法的演变发展进行介绍。
1. Age and Gender Classification using Convolutional Neural Networks (2014)
概述
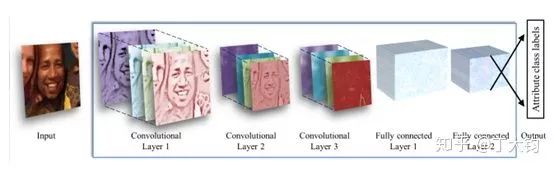
本文是最早使用深度学习估计年龄的论文之一。根据其网络结构图可很容易的去理解其方法:使用三个卷积层和两个全连接对年龄直接进行分类估计。
由于论文提出时间较早,且相对其他论文创新点有限,在此不做详细介绍。
2. DEX: Deep EXpectation of apparent age from a single image (2015)
概述
此论文提出的方法获得了LAP2015年龄分类竞赛的冠军,创新点如下:
1. 由于分类算法无法得到准确的年龄,作者通过预测概率和标签值相乘的求期望方法,把年龄估计的回归问题用分类问题解决。
2. 提出了一种不用关键点的矫正方法。
3. 提出了IMDB-WIKI年龄数据集。
整体设计
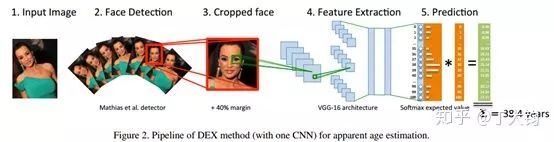
如上图所示,文章的整体流程为人脸检测、人脸矫正、剪裁处理、神经网络估计年龄。
1. 首先将输入图片以5度为区间的进行左右各60度旋转。由于训练图片里有上下\左右颠倒图像,故也进行了-90\90\180度的旋转。
2. 对旋转后的图片进行人脸检测【7】。
3. 提取得分最高的人脸,提取此图的旋转信息对原图进行校正。
4. 校正后的图片扩充40%,并Resize为256*256,送入后面的网络。
通过先旋转再矫正的方法不需要进行关键点检测,也被认为是本文的创新点之一。但是这样的操作会使计算量翻倍,占用更多的计算资源。且作者使用的数据集是LAP等输入图里必有人脸的数据集,最高的得分可以确保输出最好的人脸。但实际操作中,输入图片很多没有人脸,如果还是提取得分最高的结果可能会导致很多False-Positive的错误输出。
CNN网络部分使用了ImageNet预训练的VGG16作为基础网络,由于任务是区分0-100岁的年龄,故最后是一个101维的FC层。
最终输出的年龄是估计标签对应的年龄标签和Softmax概率相乘再求和得到年龄的期望值。
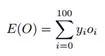
训练\评测细节
在训练时,作者将LAP数据按9:1划分训练和验证集,图片做了-10~10度的旋转扩展和0.9-1.1的缩放扩展。
作者进行了20种随机划分组合,训练了20个网络,最后输出结果是这20个网络输出结果的平均值。
之后作者介绍了两种测评方案1. MAE 2. E-error。MAE就是对估计年龄和真实标签直接求MAE误差。而由于LAP数据集使用了多人进行标注,年龄标注结果可以近似为一个正态分布。E-error会同时衡量估计结果与均值和方差的综合关系。
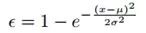
实验效果
通过对在LAB2015数据集上的测评结果,有如下几个结论:
1. 使用概率估计值相乘的求期望的方法比直接分类效果要好。
2. 在保证数据充足(加了IMDB-WIKI)前提下,使用求期望的方法比直接回归(文中使用了SVR回归)的效果要好。
总结
使用分类概率和估计值相乘再求和来求期望的方法比直接分类和直接回归的效果更好。
3. Ordinal Regression with Multiple Output CNN for Age Estimation (2016)
概述
此论文使用有序的回归问题来做年龄估计。
作者把年龄回归问题转为一系列有序的多个分类的子问题,每个子问题只对是否比某个年龄大进行判别。
文章最后还提出了AFAD亚洲人脸年龄数据集。
年龄估计中的排序信息
作者首先讨论了直接年龄分类和回归的弊端,多分类问题把每个年龄标签看做是独立的,但实际上年龄是有序的。
回归方法可利用这个有序的年龄标签做回归,但是人脸有很多因素比如头型、皮肤等会对年龄变化造成影响。这样会造成学习的不稳定“non-stationary”,回归模型这种情况下可能导致过拟合。
此论文将有序排序转换为一系列二分类问题,每个子问题只判断输入人脸是否比k年龄大,这样作者使用CNN将年龄回归问题转换为一个多输出的分类问题。
因为网络中间的卷积部分共享,所以所有的二分类问题可在一起训练。
训练时输入的是Xi空间,输出是y空间y={r1,r2,...rk}。若有K个年龄分类,将转换为k-1个二分类问题,每个子问题只关注输出yi是否比k大。
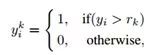
最后的回归问题是找到一个 X * Y -> R 的方法,让这个排序最好。
有了排序信息后,使用如下公式得到估计输出年龄。其中fk(x) 只与是否比x年龄大有关,是一个0 or 1的二值输出。
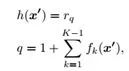
网络设计
如下图网络结构所示,整体网络有三个卷积层,维度为80的FC后面接k-1个二分类FC。
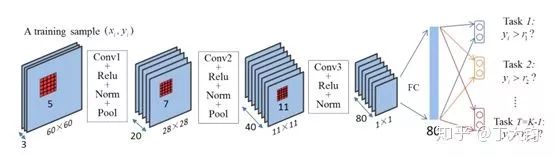
对于每个子任务,使用的交叉熵如下(W是网络参数,xi是输入,oi是输出,wi是图像权重):
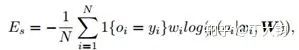
而所有的子问题整合在一起就是一个大的交叉熵损失的集合:
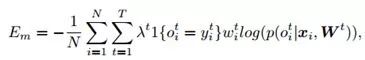
在操作时的预处理步骤为 1. 人脸检测 -> 2. AAM人脸矫正【10】 -> 3. resize为64*64 -> 4. 随机crop为60*60。
文章使用两种评测方法: MAE和Cumulative Score(CS)。其中CS的方法认为年龄差异在n内的输出为正确,求在此前提下的准确率。
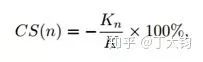
实验效果
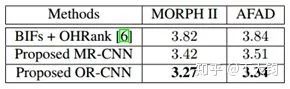
文章对比了传统方法和直接用回归(MR-CNN)的方法,直接回归的基础网络与OR-CNN一样,最后一层直接接一个FC输出年龄,使用L2-norm Loss去回归。

结果传统方法和直接回归MR-CNN的效果都不如OR-CNN好。
总结
年龄估计中使用排序信息可以提升效果。
4. Quantifying Facial Age by Posterior of Age Comparisons (2017)
概述
次论文由商汤和港中文在2017年发表于BMVC。作者基于区分两张人的年纪大小比直接进行年龄预估的难度小的原理,不使用单一年龄标签,而把年龄的概率分布作为标签。
在训练时结合分类loss和分布loss共同学习。
作者还提出了MegaAge数据集。
使用概率分布标记年龄
文章使用了两个实验证明了两个结论:1.直接猜年龄很困难 2. 若给定两张脸,判别哪个脸年龄更大会更简单。
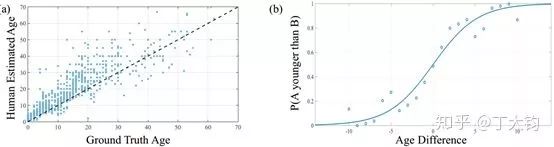
作者通过观察发现人在年龄对比的时候,年龄的差异和区分概率近似是一个Logistic函数。估计值a和真实值k差距越大,区别越明显。a和k越接近,区分概率越接近0.5,越不好区分。
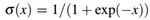
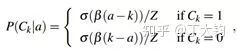
公式中Z是一个区分函数保证上下两者加和为1。贝塔是弯曲参数值,将其设置为0.36。
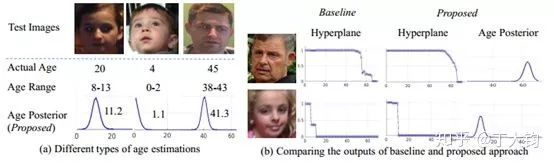
在上图的左图中作者对比了对年龄进行标记的不同方法,分别为直接标记真实年龄、标记一个范围、还有就是本文提出的使用概率分布表示。
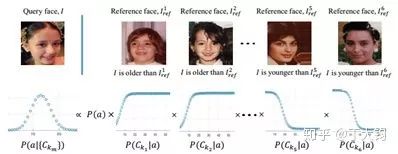
作者使用了大量篇幅介绍了每次两两对比年龄都是一个随机独立事件,通过多次事件可以决定基于多次对比后一张脸输出为a年龄的后验概率。
作者使用构建mega-age数据集的过程说明了如何构建年龄的分布标签。FG-net是参考数据集,从MEGA里随机选图作为query图像,通过两两对比得到其分布。为了让对比有效:作者用了一个性别分类器,保证两张图性别一致。然后用一个在Morph2上训好的模型大体估计图片的年龄,在FG-net上找三个年龄标签比它大、三个比它小图片。以下图为例,每张图的后验概率分布与图片内容无关只与图片的真实年龄有关,所以相同年龄的后验概率分布图是都一样的。变化的是在Morph2上进行训练的年龄估计模型概率输出p(a)。通过p(a)与用于对比的不同reference图片两两对比就可以得到新的图片的分布并作为query图片的标签。
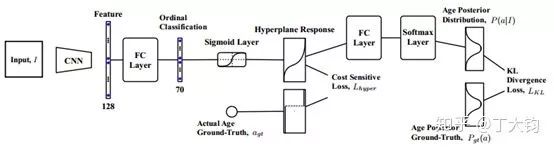
网络设计
作者设计的网络在学习时可以同时训两个loss:超平面分类的loss和表示分布差异的KL散度loss。两个loss相得益彰,分类loss让分类大致正确,KL散度loss使输出是一个分布而且能容纳不确定性。
在网络设计这里作者把分类loss和分布loss结合在一起提出如下的模型。
1 分类Loss
作者参考【8】,使用超平面(Hyperplane)的概念对其进行分类。
所谓超平面就是将原来类似001000的标签转换为001111这样的形式,借此可以使网络获知排序信息。所以对每个子任务就是一个二分类任务,只区分是否比年龄K大或者小。
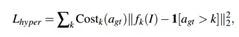
1[.]是一个0 or 1的二维输出,输出概率和1[.]的差异可以反映出分类Loss。Cost(x)是一个限制函数,当GT和预测年龄k差异小于L时(|a - k| < L)会让这个子任务的Loss变为0 (论文里设置L为3)。理由是两个人的年龄差距小于3将很难区分,导致网络学习困难。
2 后验概率验证结果相似的KL变换Loss
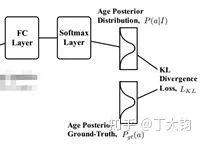
经过Softmax变换后输出年龄变成了一个分布,而本论文中年龄的GT也是一个分布。
下面公式中的Loss会计算这两个分布的差异,使用的方法是KL散度。KL散度会计算两个分布的差异,若分布近似则其输出接近于0。
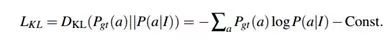
由于GT是一个概率分布,所以有三种方法计算:
对MORPH2(标签为年龄)可以直接用一个高斯分布替代;
对adience数据集(标签为年龄区间)用一个年龄分段的计算;
对于MegaAge(标签为概率分布)使用其概率分布Ground Truth来计算。
实验效果
网络设计上,作者使用VGG的剪裁版本,每一层只用原来VGG的1/4大小,所以计算量变为原来的1/16。 实验证明,相对其他算法,本论文在MORPH2上的表现是最好的。
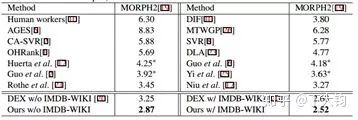
总结
对年龄图像标记使用概率分布作为GT,更准确。
结合超平面分类和KL散度的结合的Loss,分类准确率会更高。
5. SSR-Net: A Compact Soft Stagewise Regression Network for Age Estimation (2018)
概述
本文发表于IJCAI2018,特点是使用分段回归的网络,并使用回归平移量和缩放量来拟合准确的年龄。
SSR-NET借鉴了【3】的思想:使用多分类然后通过计算期望值将分类转为回归。通过分级对【3】进行改进,使用一个从粗分到细分的策略。由于每个任务更简单,所以需要的整体的神经元会会少很多,模型也会很小。为了解决分类的边界问题和回归精确的年龄,SSR-NET提出了可以进行平移和尺度变化的动态软区间(Soft Stagewise)。作者提供的SSR-NET只有0.32MB,可比肩一些比其大1500倍的网络的效果。
提出分级问题
论文中提到其他方法的对比:
1. 回归:由于年龄和人脸的很多随机因素相关,直接用回归可能会过拟合。
2. 分类:分类问题没有考虑到年龄的排序问题,而且有边界问题。
3. 排序:【2】使用排序和年龄分布来做年龄估计,但是这样就需要复杂的算法和Loss计算。
本文首先整体介绍了年龄估计要解决的问题,若所有的输入图片是X,图片数量为N,则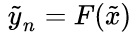
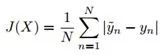
回顾一下DEX中年龄的求法是概率乘以对应年龄再相加求期望。这里的i是第几个区间,V是年龄的上限,则每个区间的宽度是V/S.
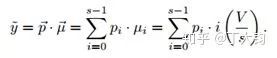
由于传统分类最后一层是很多年龄的标签(如0-90),所以需要维度很大的全连接层(91)来处理这个问题,网络就会很大。
鉴于人可以很轻易的把年龄划分为相对年轻、中年、老年等,所以本文提出了分级的设计。下面公式中k就是要分的级数。
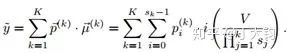
假设将任务分为三级,则第一个层级中每个区间的宽度为 90/3, 用来区分年轻、中年、老年(0 ∼30)、 (30 ∼ 60)、(60 ∼ 90)。若分到了第一层级的第一个区间,第二层级中每个区间的宽度为 90/(3*3),用来区分区分的是(+0 ∼ 10)、 (+10 ∼ 20) 、 (+20 ∼ 30)。第三个层级中每个区间的宽度是 90/(3*3*3)。由于每个阶段需要做的任务相对简单,所以整体的神经元个数很少。
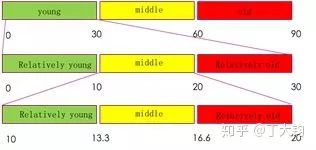
提出软区间(Soft Stagewise)问题
若每个区间的宽度都是固定的,那么只能处理离散的年龄,第三层级的“分辨率”只能是3.3,而且把年龄分段计算,会有明显边界效应。
所以作者提出对每个层级的各区间都需要有一个平移和尺度缩放系数。
首先是对区间的缩放:
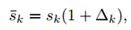
新的区间宽度不再是一个整数,而是一个小数。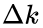
这样每层区间的宽度就会得到相应的调整:
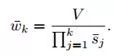
然后是区间平移:在输入图像对应的每个层级中,会有多个划分结果,而每个划分都会有一个新的平移量:
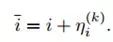
通过尺度缩放和平移,动态区间会有更精确的值,而新的输出也有相应的更新:
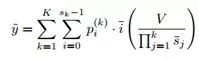
网络设计
根据分级和软区间的思想,作者设计了如下网络结构:
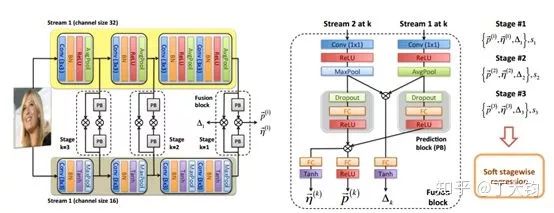
为了提取不同的特征,整个网络分为了两个分支,Stream1的通道数为32,Stream2的通道数为16。
在每层提取输出处接一个预测模块,每个预测模块有三个输出:该层的各区间的概率、各区间平移系数、区间宽度缩放系数。预测模块中stream1和stream2融合的方法是element-wise multiplication.
网络使用不同的激活函数以保证有正确范围的输出结果,如使用RELU保证概率为正数,使用Tanh保证偏移和缩放系数输出为-1 ~1。
网络最后的loss是预测的输出和真实值的MAE。
在阅读论文时对网络设计有几个问题,通过联系作者得到了其热心回复:
Q1: stage1是预测大概年龄,stage3是预测精细年龄。为何stage1在网络的深层,stage3在网络的浅层?
A1:stage 1在比較後面的設計原因是我當初認為淺層的會有比較接近紋理的資訊,而細緻的變化往往是無法用抽象的表達所形容,所以才把淺層的設為stage 3。
Q2:在提取特征时为何是RELU+avg pooling 和Tanh+max pooling的组合?
A2:RELU+ave是想擷取比較模糊的訊息,而tanh+max是想擷取比較peak的訊息。
Q3:stream1 的channel是32 ,stream2 的channel是16,为什么这么设计?
A3: 不等價的channel是根據我上篇DeepCD【11】的想法,不平衡的two-stream有時候會有更多資訊,不過這只是emprical choice。
Q4: 在计算宽度放缩系数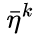
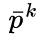
A4: 對,因為設計上p和eta是對每個index都有不同的值,所以更多fc。
实验效果
文章最终实验部分在IMDB-WIKI、MORPH2、MegaAge-asian上对比了各种网络,证明本方法是有效的。
实验证明在小模型中,SSR-NET效果是最好的,可以和比它大1500倍的模型相媲美,而且其网络只有0.32MB。笔者测试了MXNET版本发现其只有不到0.2MB,而且推理速度很快。
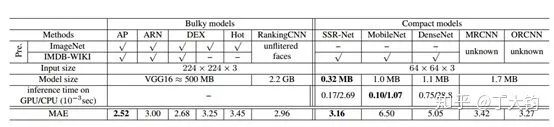
总结
1. 通过分级得到了一个年龄估计的紧凑模型。
2. 使用软区间回归可以动态调整输出结果,解决边界问题,使结果更准确。
年龄估计数据集介绍
1. FG-NET (2002)
www-prima.inrialpes.fr/
FG-Net训练集有818张图片,测试集有170张图片。此数据集包含了82个人在不同年龄的照片,同时提供了每张图中68个人脸关键点信息。
鉴于本数据集跨年龄的特色,FG-Net可用于年龄估计、跨年龄人脸识别、年龄变化推演(age progression)等方向的研究。
FG-Net曾是年龄方面最流行的数据集之一【9】,但由于此数据集公布时间较早(2002年)、人脸个数较少,且观察其人脸均为白种人,而且一些早期图片为黑白图片,【9】指出该数据的准确率已趋近饱和。所以近期的论文很少用FG-net做Benchmark。

2. MORPH2 (2006)
faceaginggroup.com/morp
people.uncw.edu/vetterr

根据论文引用情况,MORPH2数据集是目前最流行的年龄估计数据集之一,【2】【4】【5】等论文均在数据集基础上进行了评测,但【9】指出该数据集的准确率近年也已趋近饱和。
MORPH2也是一个跨时间的数据集,收录了同一个人在不同年龄段的图片。
该数据集分为商用和学术用版本,学术用版本包括了13000个人的55134张图片,照片收集时间跨度2003-2007年,人物年龄为16-77岁,平均年龄为33岁。
MORPH2数据集除年龄外还记录了人物的其他信息,如性别、种族、是否戴眼镜等。
3. Adience (2014)
talhassner.github.io/ho
openu.ac.il/home/hassne

Adience数据集包括2284个人的26580张图片。其特点为均为真实场景下拍摄(in the wild),照片受到噪声、姿态、光照等影响很大,旨在解决真实世界中的年龄和性别检测问题,网站上同时提供了原始数据和矫正后的人脸。该数据集使用了区间标注的方法,分为了8个区间:(0-2, 4-6, 8-13, 15-20, 25-32, 38-43, 48-53, 60-)。
4. CACD (2014)
bcsiriuschen.github.io/
cmlab.csie.ntu.edu.tw/~
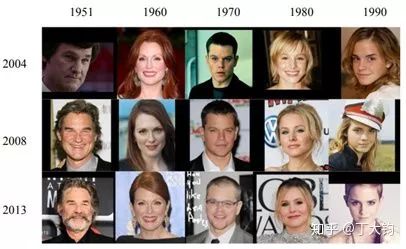
CACD收集了2000个名人的163,446张图片,年龄跨度为16 到 62。截止论文发表时间,是当时最大规模的跨年龄数据集。收集照片的时间跨度为2004-2013年。数据集同时也提供了16个人脸关键点的标注信息。
CACD数据集提供者明确指出,虽然该数据集包含人物年龄信息,但只建议使用此数据集做跨年龄人物检索,不建议使用该数据集来做年龄预估。
5. ChaLearn LAP Dataset (2015 / 2016)
chalearnlap.cvc.uab.es/(ICCV2015)
http://chalearnlap.cvc.uab.es/dataset/19/description/ (CVPR2016)

LAP(Look At People)竞赛于2015和2016举办了两年,两年数据集规模分别为5000和8000(基于官网)。
与其他数据集的标签为真实年龄不同,LAP数据集的标签是外观显示年龄(apparent age),标签制定平均了至少10个人的标注结果,所以每张图片的年龄标签都是一个正态分布。比赛排名中使用的是结合均值和方差的综合误差E-error【3】。LAP数据集在20-40岁的分布相对均匀,在0-15和65-100区间数据集较少。
6. IMDB-WIKI(2015)
data.vision.ee.ethz.ch/

IMDB-WIKI数据集是目前规模最大的年龄数据集之一,【3】的作者提出了本数据集并在其基础上finetune网络,赢得了LAP2015年的冠军。
本数据集来源包括IMDB(一个明星网站)和Wikipedia中的两万个人,图片数量分别为460723和 62328。标注方法是找到某个名人的照片,然后通过照片拍摄年份减其出生年份得到其年龄标签。
经过观察和及【5】指出,由于数据集标注过程是自动处理的,故标注质量不高,有很多错误内容。在【3】、【5】中,主要使用该数据集进行网络初始训练。下图是提取了几张与笔者同生日名人的图片,可以看到有些图片甚至没有人脸。

7. AFAD (2016)
链接:afad-dataset.github.io/
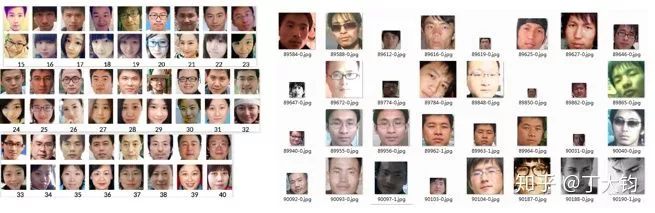
数据集【4】规模为164432张脸,其中63680张女性、100752男性。年龄段为15-40岁。
该数据集的特点是数据几乎全是中国人。该数据的数据来源为人人网,首先爬取人人网上的图片数据并获取相册所有者的年龄,然后使用人力对错误图片进行过滤。
本数据年龄分布也不是很均衡,在最年轻和年纪较大的年龄段数据较少(也好理解,因为该年龄使用人人网的人少)。
根据观察,感觉数据集整体标注效果比较准确,但有一些小图片(22*22)看不清楚,且有很多同一个人的图片几乎完全一样。数据集还有一个特点就是图片截取的较小,只留了较少的脸部,发型和颈部都去除了。其实年龄估计和人的发型、身体等也有一定联系,截取太小将无法使用到这些信息。
8. MegaAge/MegaAge-Asian (2017)
mmlab.ie.cuhk.edu.hk/pr

MegaAge数据集由商汤发布【2】,总数有41941张图片,同一论文提出的MegaAge-Asian包含40000张亚洲人(绝大部分是东亚人)的图片,两个数据集年龄段都是0-70。数据集人脸的原始来源是MegaFace和YFCC。论文中提到,由于MegaAge-Asian的种族相对单一,故同一年龄估计算法MegaAge-Asian上的表现一般要优于MegaAge数据集上的表现。
经观察,MegaAge-Asian标注结果比较精准,提供的图片大小统一为178*218,在保持比例前提下进行了补边操作,数据集包含了明星和普通人的图片。
参考文献
1. Age progression in Human Faces A Survey
2. Quantifying Facial Age by Posterior of Age Comparisons
3. DEX: Deep EXpectation of apparent age from a single image
4. Ordinal Regression with Multiple Output CNN for Age Estimation
5. SSR-Net: A Compact Soft Stagewise Regression Network for Age Estimation
6. Age and Gender Classification using Convolutional Neural Networks
7. Face detection without bells and whistles
8. Ordinal Hyperplanes Ranker with Cost Sensitivities for Age Estimation
9. Age and Gender Estimation of Unfiltered Faces
10. Active appearance models
11. DeepCD: Learning Deep Complementary Descriptors for Patch Representations
@ 知乎-丁大钧
版权声明
本文版权归《知乎-丁大钧》,转载请自行联系。


点击下方阅读原文了解课程详情
历史文章推荐:
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
SFFAI分享 | 曹杰:Rotating is Believing
SFFAI分享 | 黄怀波 :自省变分自编码器理论及其在图像生成上的应用
AI综述专栏 | 深度神经网络加速与压缩
SFFAI分享 | 田正坤 :Seq2Seq模型在语音识别中的应用
SFFAI 分享 | 王克欣 : 详解记忆增强神经网络
SFFAI报告 | 常建龙 :深度卷积网络中的卷积算子研究进展
点击下方阅读原文了解课程详情↓↓
若您觉得此篇推文不错,麻烦点点好看↓↓





