活动 | 200位学术青年齐聚HIT,GAIR大讲堂CVPR哈工大深圳专场总结回顾
AI科技评论按:8月26日下午,由雷锋网主办的“GAIR大讲堂CVPR 哈工大深圳专场”在哈尔滨工业大学深圳校区正式开幕。作为雷锋网旗下高端学术分享品牌,「GAIR大讲堂」的使命是通过举办高频次的线下校园学术分享活动,实现学术专家、AI业者与学校同学们之间的深度交流。CVPR哈工大深圳专场是GAIR大讲堂在8月份的第三场也是最后一场线下学术分享活动。本活动在哈工大深圳计算机学院王轩院长和何震宇老师的支持下,雷锋网特地邀请了5位CVPR 2017前方论文讲者来讲解各自的论文,同时分享CVPR 的参会心得。AI科技评论作为GAIR大讲堂活动的独家合作媒体,全程参与了现场报道。
活动现场

活动现场座无虚席


同学踊跃提问

活动承办方哈工大(深圳)研究生院计算机学院王轩院长致辞
分享嘉宾介绍
哈尔滨工业大学计算机学院教授、博士生导师 左旺孟
码隆科技首席科学家 黄伟林
码隆科技联合创始人兼CTO Matt Scott
清华大学博士 陈晓智
浙江大学工学博士 李琛
嘉宾分享环节

第一位分享嘉宾是左旺孟教授,左旺孟老师是IEEE会员,中国计算机学会会员,国际期刊《ISRN Signal Processing》编委。主要从事图像增强与复原、稀疏表达和深度学习等方面的研究。在ACM CSUR、IEEE TIP等重要国际期刊和CVPR、ICCV、ICPR、ICIP等重要国际会议上发表学术论文40余篇。他分享的论文题目是:Deep learning models for image restoration and depth enhancement (面向图像复原和深度图增强的深度学习模型)
论文分为四部分:图像还原与图像去噪;用深度学习卷积神经网络去噪之前图像进行图像还原;用于深度图像增强的动态引导学习;论文总结。

图像增强和复原是底层视觉的一个重要内容。近年来,以卷积神经网络为代表的深度学习模型在图像超分辨与去噪领域获得了巨大的成功。然而,如何将其推广应用至更多的底层视觉视觉问题,是近年来关注的一个重要方向。左旺孟老师的分享就是围绕这一问题,介绍他们在今年CVPR上的两个工作:
一、设计了一种新的去噪CNN网络,并结合半二次分裂方法将其推广应用于广义的图像复原问题的求解;
二、针对有引导图的深度图增强问题,设计了一种特殊的深度网络结构并利用任务驱动策略学习动态引导与增强模型。
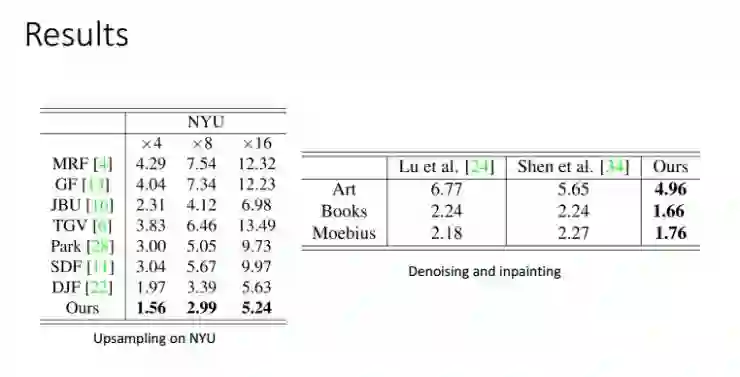
实验结果

接下来是来自码隆科技的两位科学家,黄伟林博士和Matt Scott 。

左:黄伟林博士;右:Matt Scott
黄伟林博士来自牛津大学 Visual Geometry Group(VGG),是首位从该实验室回国工作的研究员。博士后期间师从 Andrew Zisserman和 AlisonNoble。研究方向主要集中在场景文本识别,场景分类和医学视频分析等领域。同时,他还担任计算机视觉 / 人工智能领域主要会议的 PC member 或者 Reviewer,包括: ICCV、 CVPR、 ECCV、 AAAI 等。黄伟林博士曾任中国科学院助理教授。
Matt Scott 拥有十年微软研发经验,曾任微软亚洲研究院高级研发主管。 Matt 多年均为微软绩效排名前 1%的杰出员工与管理者,拥有国际顶级学术会议论文 13 篇,超过 40 个中美专利技术, 18 个微软技术商业转化成果。其熟悉研发领域包括软件工程、视觉计算,机器学习,尤其擅长把最前沿计算机科学成果转化为服务大众的互联网产品。
他们分享的主题为: CVPR WebVision 挑战赛分享与展望

分享内容: CVPR 期间,WebVision 大规模视觉理解全球挑战赛宣布赛果,码隆科技团队在全球超过 100 支参赛队伍中脱颖而出,荣获冠军。
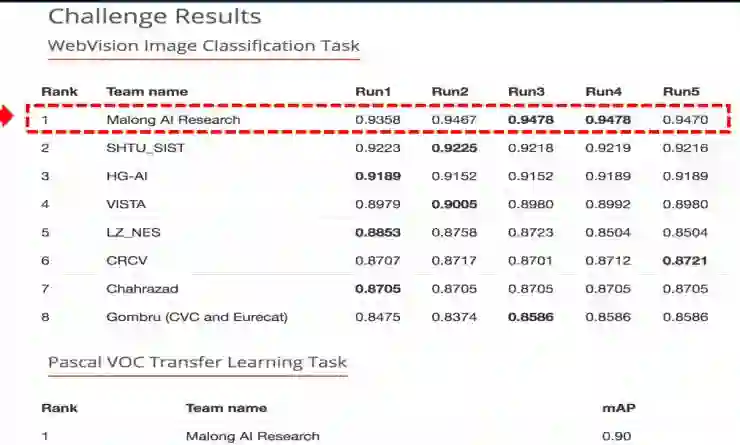
WebVision 竞赛的主要挑战是数据来源于网络抓取,未经过任何人工标注, 因此含有大量的错误类别标签。 码隆算法团队利用课程学习(Curriculum Learning)的思路,设计更加高效的训练策略, 有效地抑制错误标签和数据不平衡的负面作用。在演讲中,码隆科技黄博士将分享了竞赛的算法思路和方法方面的相关经验,以及针对现实场景中非人工标注数据的训练和学习技术的探索。除此之外,Matt 还重点介绍 ImageNet 与 Webvision 两大学术比赛之间的区别,深入介绍了WebVision 比赛的主要挑战,以及由WebVision 比赛引发的对智能视觉现实场景应用的探索。希望带领广大同学们更深入的了解和认识 WebVision 挑战赛。

第四位分享嘉宾是清华大学博士陈晓智,分享主题为: Multi-View 3D Object Detection Network for Autonomous Driving (面向自动驾驶的多视角三维物体检测网络)

陈晓智博士毕业于清华大学电子工程系。他的研究兴趣为深度学习及其在三维感知中的应用。他曾在多伦多大学、百度自动驾驶事业部进行访问和实习,曾获清华大学优秀博士论文、博士生国家奖学金。

陈晓智博士从四个方面解读这篇论文。

分享内容:三维物体检测是自动驾驶感知系统的关键问题。本文提出了一种多视角三维物体检测网络(MV3D),通过融合激光点云和 RGB 图像来实现物体的三维定位与检测。该模型将三维点云编码成多视角的表示,通过三维似物性网络来提取三维候选区域,并设计了一种深度融合网络来学习物体的多模态特征。该方法在 KITTI 评测集上取了领先的三维物体检测性能。
实验结果图:


李琛于 2017 年 6 月获得浙江大学工学博士学位,师从周昆教授和微软亚洲研究院 Steve Lin 博士。他的研究方向为三维重建、计算摄影学、观建模等计算机视觉、计算机图形学的交叉领域。 2012 年至 2016 年期间曾在微软亚洲研究院网络图形组实习。

他的分享内容主要分为以下六部分:

分享内容:人脸一直以来都是图像和视频中的最重要的呈现内容。目前市面上也有很多人脸识别APP。

因此,针对人脸的图像处理技术变得十分重要,并获得越来越广泛的学术和工业界关注。由于人类生理结构的相似性,使得人脸具有更多区别于一般物体的特征和约束可以被利用——肤色就是其中之一。李琛博士和团队其他人在CVPR 2017 发表的两篇论文《Radiometric Calibration from Faces in Images》和《Specular Highlight Removal in Facial Images》,正是利用人脸肤色的生物学模型作为先验知识,与当今主流算法相比较,在高光分离、相机响应函数校准,这两个传统图像处理的重要问题上,效果获得显著提升。

内容分享结束后,几位嘉宾还同时分享了他们在学术界与工业界做研究的工作经验。在最后的问答环节中,现场同学们就学习、招聘、工作等方面遇到的问题请教了几位嘉宾,他们都耐心给出了解答,广大在场的同学们都收获良多。以上就是GAIR大讲堂CVPR哈工大(深圳)专场 5位嘉宾分享的全部内容。AI科技评论为大家整理了本次活动现场PPT(可关注AI科技评论公众号,后台回复“哈工大PPT”,获取下载链接)。

活动结束后嘉宾合影
————— 给爱学习的你的福利 —————
3个月,从无人问津到年薪30万的秘密究竟是什么?答案在这里——崔立明授课【推荐系统算法工程师-从入门到就业】3个月算法水平得到快速提升,让你的职业生涯更有竞争力!长按识别下方二维码(或阅读原文戳开链接)抵达课程详细介绍~

————————————————————




