【学界】另一种可微架构搜索:商汤提出在反传中学习架构参数的SNAS
选自 Openreview
作者:Sirui Xie、Hehui Zheng、Chunxiao Liu、Liang Lin
来源:机器之心
为了寻找可以用在大规模数据集上的成熟的AutoML 或神经网络架构搜索(NAS)解决方案,本文作者提出了一种经济的、端到端的 NAS:随机神经网络架构搜索(SNAS)。该方法在保持 NAS 工作流程完整性和可微性的同时,在同一轮反向传播中训练神经运算的参数和网络架构分布的参数。在使用 CIFAR-10 数据集进行的实验中,SNAS 在经过更少 epoch 迭代的情况下取得了当前最佳性能,而且其效果可以被迁移至 ImageNet。
自 2016 年 Barret Zoph 和 Quoc Le 提出「用强化学习进行神经架构搜索」(《Neural architecture search with reinforcement learning》)以来,在大量科研人员的努力下,自动搜寻最先进的网络架构的趋势一直在增长。通常而言,一个神经网络架构搜索(NAS)的工作流程包括架构采样、参数学习、架构验证、信用分配以及搜索方向更新。
目前主要有三种神经架构搜索框架。首先,诸如 NEAT(Stanley & Miikkulainen,2002)的基于演化计算的 NAS 框架采用演化算法同时优化拓扑结构和参数。然而,它需要耗费巨大的计算能力,还不能在深度学习中利用高效的梯度反向传播。为了达到与最先进的人工设计的神经网络架构相当的性能,Real et al.(2018)要运行完完整的演化计算过程需要让 3150 个 GPU 工作一天的时间;基于强化学习的 NAS 是一种端到端的可以使用梯度反向传播的模型;而效率最高的 ENAS(Pham et al.,2018)能够像 NEAT 一样同时学习最优参数和网络架构。
然而,由于 NAS 被建模为一种马尔科夫过程,它会用时序差分(TD)学习(Sutton et al.,,1998)将信用度(credit)分配给结构化的决策,其效率和可解释性会受到延迟奖励的影响(Arjona-Medina et al.,2018)。为了摆脱架构采样过程的弊端,DARTS(Liu et al.,2019)提出了对运算的确定性注意力机制,分析计算每一层的期望,并在父网络收敛后删掉分配到较低注意力的运算。由于神经网络中普遍存在非线性计算过程,子网络的性能往往不一致,这时对参数的再训练就十分必要了。研究人员通常希望建立一个更高效、更易于解释并且偏置更小的搜索框架,尤其是用在未来的大规模数据集上的成熟的 NAS 解决方案。
本文提出了一种新的高效且高度自动化的搜索框架——随机神经网络架构搜索(Stochastic Neural Architecture Search,SNAS),该框架在保持 NAS 工作流程完整并可微的条件下,在同一轮反向传播中训练神经运算的参数和架构的分布参数。构建 SNAS 的一个关键的思想是,利用泛化损失中的梯度信息提高基于强化学习的 NAS 的效率,其反馈机制是由持续的奖励(reward)信号触发的。
为了能够与任意可微的损失函数相结合,搜索空间由一组服从完全可分解联合分布的 one-hot 随机变量表示,这些变量相乘作为掩码来选择每条边的运算。通过具体的概率分布来松弛网络架构的分布,可以使得在该搜索空间中的采样过程具有可微分性(Maddison et al.,2016)。有关它们参数的梯度被命名为「搜索梯度」,类似于 Wierstra et al.(2008)中的参数,但不涉及基于策略梯度(policy gradient)的强化学习方法。
从全局的角度来看,作者证明了:除了使用训练损失作为奖励,SNAS 的优化目标与基于强化学习的 NAS 是相同的。具体而言,作者提出了与搜索梯度等价的策略梯度,说明了每个样本中损失的梯度如何被用来为所有的结构化决策分配信用度。以这种方式分配信用可以被解释为泰勒分解(Montavon et al.,2017a),它比存在延迟奖励的时序差分学习更高效(Arjona-Medina et al.,2018)。此外,作者为做出结构化的决策,自然地分解了一个全局资源约束,增强了这一信用分配问题的可行性。
在本文的实验中,与 DARTS 和其它现有的 NAS 方法相比,SNAS 在测试误差、模型复杂度和搜索资源方面表现出了强大的性能。具体而言,在 CIFAR-10 数据集上进行测试时,SNAS 发现新的卷积神经架构可以在仅仅具有 2.8M 参数的情况下获得 2.85±0.02% 的测试误差,这比一阶 DARTS 搜索到的带有 3.3M 参数的网络所获得的 3.00±0.14% 测试误差和 ENAS 搜索到的带有 4.6M 参数的网络所获得的 2.89% 测试误差都要好。SNAS 搜索到的网络也在使用更少的参数的条件下,达到了与通过二阶 DARTS 搜索到的带有 3.3M 参数的网络(2.76±0.09%)相当的性能。通过更强的资源约束,SNAS 发现即使是更小的模型(带有 2.3M 参数)也能在 CIFAR-10 数据集上获得 3.10±0.04% 的测试误差。
在架构搜索过程中,SNAS 使用更少的 epoch 的迭代达到了 88% 的验证准确率,而 ENAS 的验证准确率则大约为 70%。在不进行调优的情况下,在 CIFAR-10 上验证派生的子网络时,SNAS 保证了搜索验证的准确率,显著优于 DARTS 取得的验证准确率为 54.66% 的性能。以上实验结果结果验证了我们的理论,即 SNAS 的偏置小于 DARTS。当迁移到 ImageNet(在移动设备上)时,SNAS 所发现的神经元架构获得了 27.3% 的 top-1 错误率,这与二阶 DARTS 所获得的 26.9% 的 top-1 错误率相当。
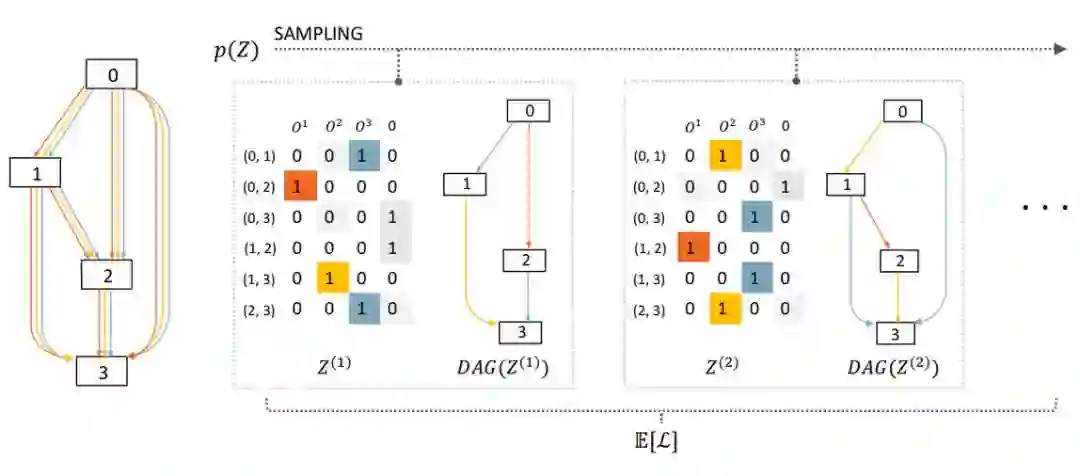
图 1:SNAS 中前向传播的概念的可视化结果。Z 是一个从分布 p(Z) 中采样得到的矩阵,其中每一行的 Z_(i,j) 是一个随机变量的 one-hot 编码向量,表示将掩码和有向无环图(DAG)中的边(i,j)相乘。该矩阵的列对应于运算 O^k。在本例中,有四个候选的操作,其中最后一个操作为零操作(即移除这条边)。目标函数是所有子图的泛化损失 L 的期望。
论文:SNAS: STOCHASTIC NEURAL ARCHITECTURE SEARCH

论文地址:https://openreview.net/pdf?id=rylqooRqK7
在本文中,作者提出了一种经济的、端到端的神经网络架构搜索(NAS)解决方案:随机神经网络架构搜索(SNAS)。该方法在保持 NAS 工作流程完整性和可微性的同时,在同一轮反向传播中训练神经运算的参数和网络架构分布的参数。在本文中,NAS 被重新规划为神经网络架构内搜索空间的联合分布参数的优化问题。为了利用可微的泛化损失中的梯度信息进行结构搜索,作者提出了一种新的搜索梯度。
作者证明了这种搜索梯度优化了与基于强化学习的 NAS 相同的目标,但可以更高效地为结构化决策分配信用。该信用分配机制进一步增加了局部可分解的奖励,从而实现了对资源效率的约束。在使用 CIFAR-10 数据集进行的实验中,SNAS 在经过更少 epoch 的迭代的情况下,取得了比不可微的基于演化计算或基于强化学习的 NAS 更好的、目前最先进的性能,并且其效果可以被迁移至 ImageNet。研究还表明,SNAS 子网络在搜索过程中能够保持验证准确率,而基于注意力机制的 NAS 需要经过参数再训练才能与之相匹敌,SNAS 在大数据集上显示出向高效 NAS 发展的潜力。
2 方法
SNAS 的主要研究动机是在尽可能少地破坏 NAS 系统工作流程的前提下,构建一个高效而经济的端到端学习系统。在本节中,作者将首先描述如何从搜索空间中对神经元内的 NAS 进行采样,以及它如何激发 SNAS(2.1 节)。作者在 2.1 节中给出了优化目标,讨论了基于注意力机制的 NAS 的不一致性。接着在 2.2 节中,作者将介绍如何将这个离散的搜索空间松弛为连续的搜索空间,从而让梯度能够反向传播。在 2.3 节中,作者将 SNAS 的搜索梯度与基于强化学习的 NAS 的策略梯度方法(Zoph & Le,2016;Pham et al.,2018)相结合,通过贡献分析解释 SNAS 的信用分配机制。最后,作者在 2.4 节中介绍了 SNAS 是如何分解资源约束并将其融合到信用分配中,从而增强了目标的可行性。
3 实验
本文的实验借鉴了 DARTS 的工作流程,由三个阶段构成。首先,作者将 SNAS 用于在 CIFAR-10 数据集上搜索一个小型的父网络中的卷积神经架构,并且基于它们的搜索验证准确率选出了最佳的神经架构。接着,通过堆叠学到的神经架构(子网络)构建出一个更大的网络,并且在 CIFAR-10 数据集上进行再训练,用于比较 SNAS 和其它最先进的方法的性能。最后,作者通过在 ImageNet 上评价这些模型的性能,证明了在 CIFAR-10 上学习到的神经架构可以被迁移到大型的数据集上。
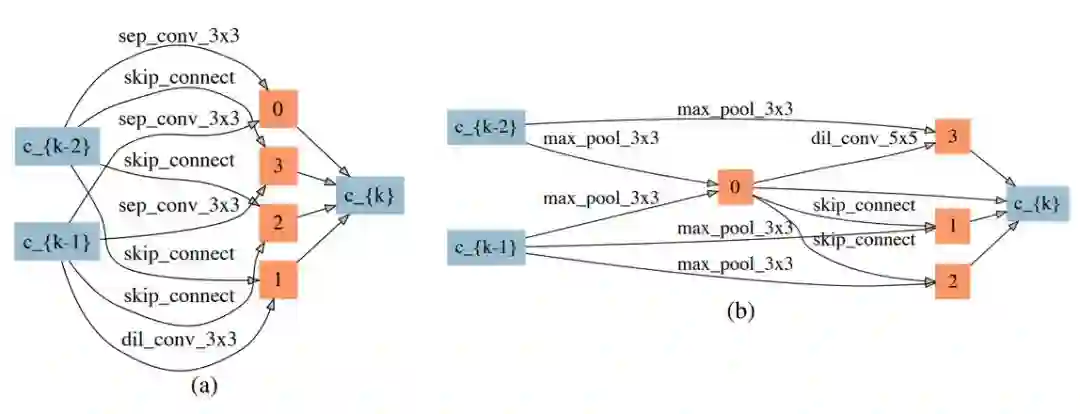
图 2:在 CIFAR-10 数据集上的神经架构(子网络)的随机神经网络架构搜索(带有较弱的约束)。(a)正常的神经架构。(b)删减后的神经架构。

表 1:分别使用 SNAS 和 DARTS 得到的搜索验证准确率及子网络的验证准确率。标有「*」的结果是使用 Liu et al.(2019)的代码获得的。
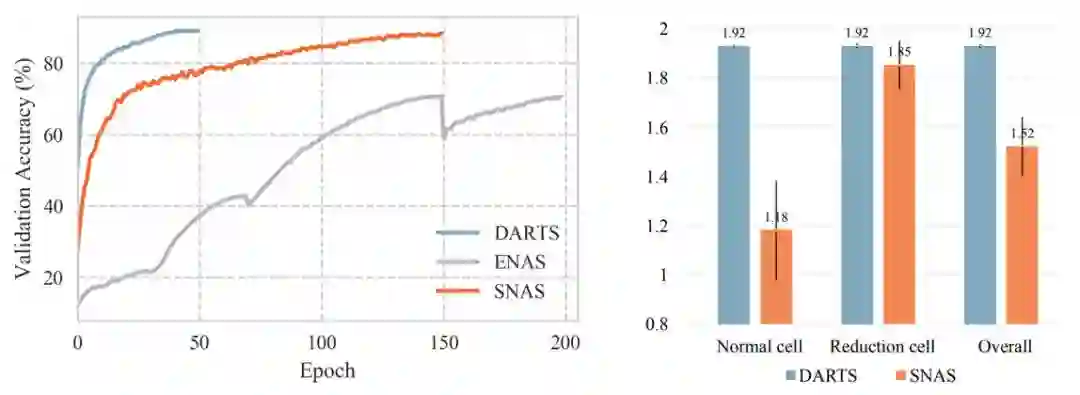
图 3(左):SNAS、DARTS 以及 ENAS 的验证准确率随着搜索进度不断推进的变化情况。图 4(右):SNAS 和 DARTS 中的架构分布的熵。
如图 5 所示,子网络中更多的边被摘掉,仅仅剩下了 两条边,这导致了一些节点(包括输入节点 c_{k-1},两个中间节点 x_2、x_3)也从网络中被摘除掉。请注意,通过 ENAS 和 DARTS 是不能发现这样的子网络的。
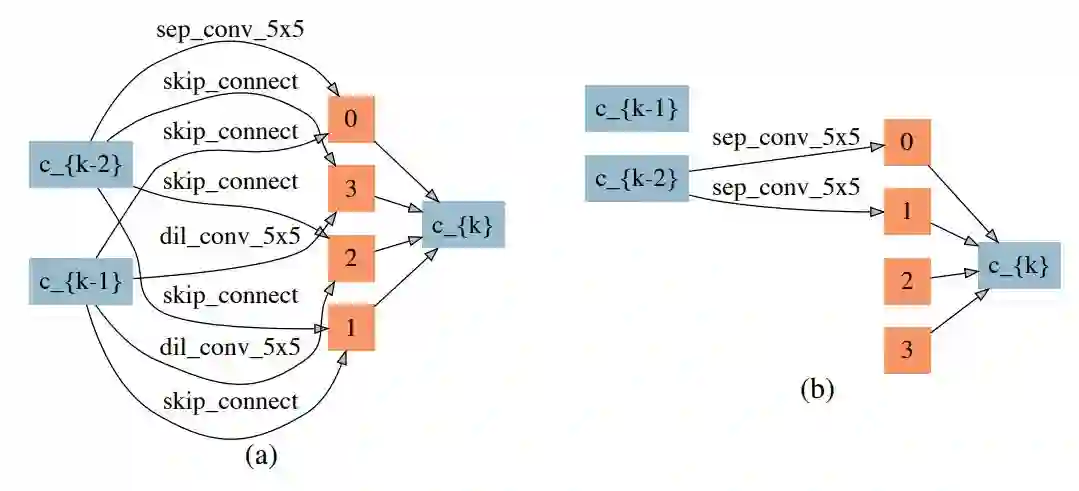
图 5:在 CIFAR-10 数据集上的神经架构(子网络)的随机神经网络架构搜索(带有较强的约束)。(a)正常的神经架构。(b)删减后的神经架构。
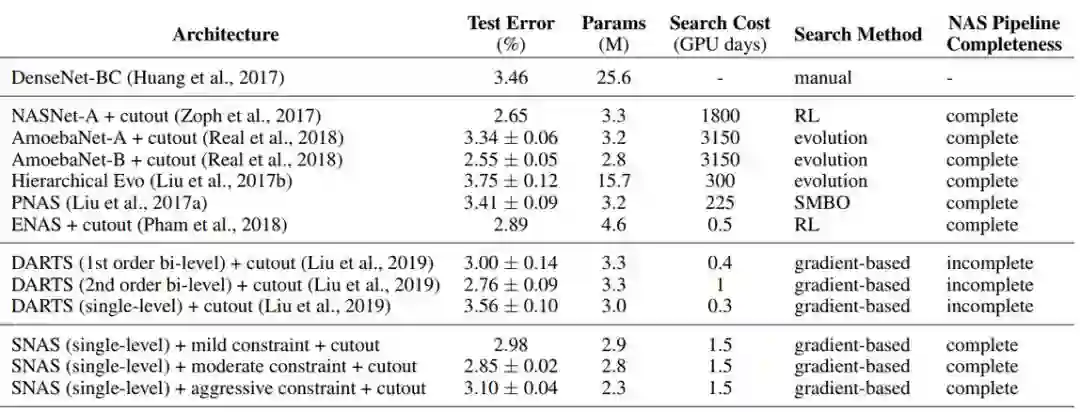
表 2:在 CIFAR-10 数据集上,SNAS 和最先进的图像分类的分类误差。
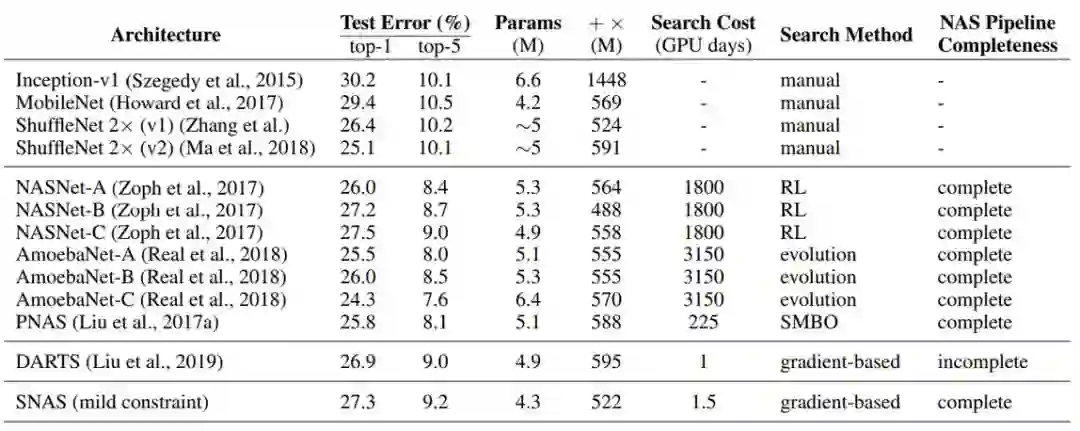
表 3:在 ImageNet 数据集上,SNAS 和最先进的图像分类的分类误差。
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得
