畅途亿级业务日志系统演变过程

你是否遇到过如下情况:线上偶尔出现一个问题,但我们并不能快速准确的排查定位该问题!
为了解决这个问题,快速准确的排查定位问题,畅途网建立了一套业务日志系统。
畅途业务日志系统模块主要分 4 个模块:
1. 日志集中查询
2. 业务编码配置
3. 日志异步记录
4. 日志存储
由于你没有线上环境的权限,所以还需要运维帮你取一些日志。通常情况下,你是无法知道具体执行方法的代码位于集群中的哪台机器上,可能需要一台一台登录进行查询。为了避免这种情况,我们需要把所有日志统一到一个地方,提供统一的查询入口,供相应人员进行查询。
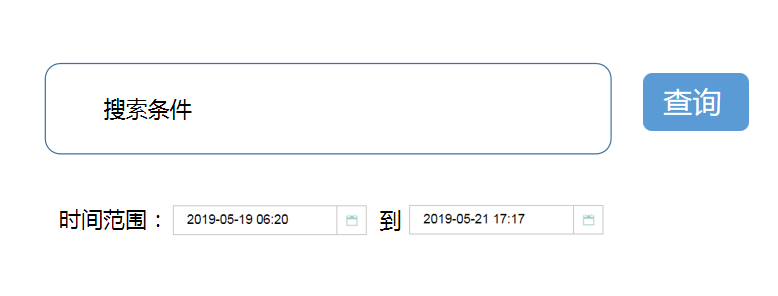
备注: 登录系统,时间范围为当前时间 -3 天 到当前时间 默认仅需要输入搜索条件即可进行搜索查询,如果需要调整时间,选择相应时间即可。
由于每一个业务逻辑不一样,需要处理的数据也不一样,我们定义了一个下面类似的页面,每新加一个业务处理,添加一个业务,需要设置相应位置的字段的内容。
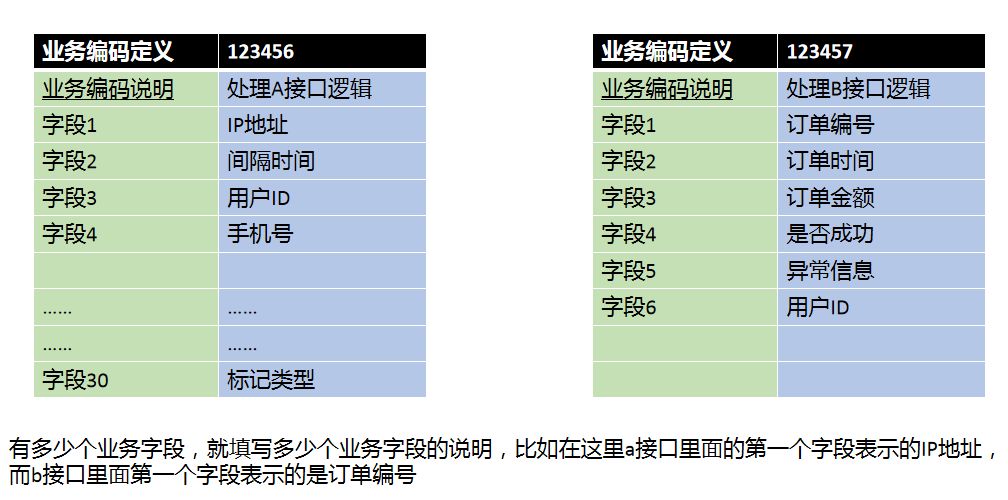
备注: 定义完这个业务编码之后,我们输出的时候会在每个字段前面加上相应的解释,比如 ip 地址:123.145.33.25,而不是一些没有解释的直接输出的内容。
如果记录日志慢,就会影响正常的业务流程,那么这个记录就是失败的! 所以记录日志必须要走异步。
这里经历了 3 个大版本的演变,后续慢慢说明!
对记录的日志进行处理,存储到相应地方,提供接口供统一查询进行调用。
这里也经历了 3 个大版本的演变,后续慢慢说明!
演变的过程,在我看来就是不断挖坑、填坑的过程!
上面提到畅途业务日志系统的 4 个模块分别是:
1. 日志集中查询
2. 业务编码配置
3. 日志异步记录
4. 日志存储
其中关于日志异步记录、日志存储经历了一些坑,下面我们分别来谈谈。
我们写一个通用工具类,通过在业务代码中间穿插发送日志代码
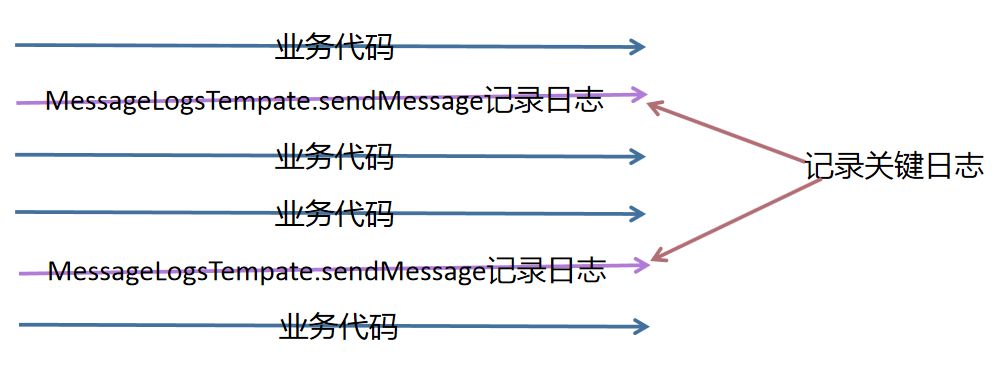
调用 sendMessage 方法发送日志如下:
String[] param = { ip, operStatus, result, errorMessage, userId,……等等的一些其他参数 };
MessageLogsTempate.sendMessage("123456", param);
sendMessage 内部实现日志异步记录经历了三个过程:
走 ActiveMQ 记录日志 ;
走 Nginx 记录日志 ;
走队列,异线程取队列走 Nginx 记录日志。
备注:记录日志的逻辑不能影响正常业务!!!
记录日志的逻辑不能影响正常业务!!! 这个也很容易理解,但是我们以前就经历过这个坑。
大概在 2012-2013 年左右,我们当时讨论选择的框架就是走 MQ,那样异步不会影响业务。当时就选择了 ActiveMQ。
做法思路就是 sendMessage 往 ActiveMQ 里面写数据,另外消费者消费 ActiveMQ 里面的数据。
思路也很简单,修改做起来也很简单,一直都挺好,有次业务高峰期,忽然整个系统很慢,最后排查定位发现是写 ActiveMQ 阻塞了。(具体原因很多,在这里就不详细说明了 )。

使用 ActiveMQ 记录日志,出现阻塞,导致影响业务! 问题很严重,后来我们就选择了通过走 Nginx 记录日志了。
谈谈当时的想法,为什么没有继续选择其他 MQ 呢?
时间紧迫,Nginx 简单,并且用过 Nginx 类似功能。
MQ 学习成本较大,同时也怕再次遇到类似 ActiveMQ 问题 。
由于上面的 2 个原因,最后我们选择了 Nginx。

就变成了 sendMessage 方法通过调用 Http 发送 Nginx。
文件名称都是以小时来生成的,不同的情况会有不同的后缀,处理完成之后会修改文件名为 bak。
下面是测试环境类似日志:
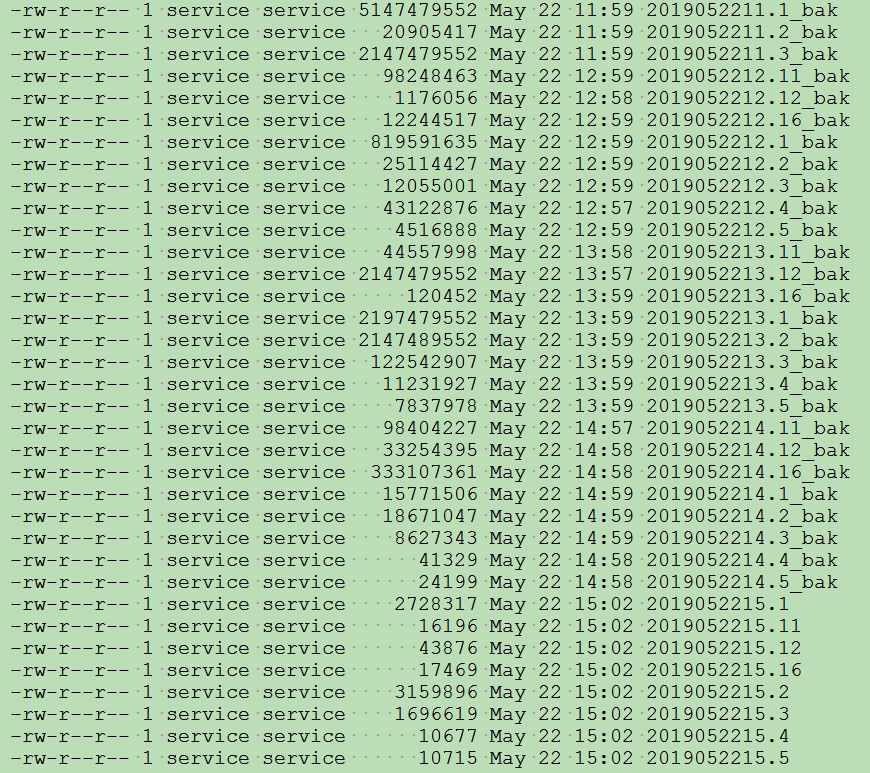
有次我们通宵模拟的时候,发现如果 Nginx 服务器特别卡顿的时候,会导致类似 ActiveMQ 一样的情况,会阻塞。
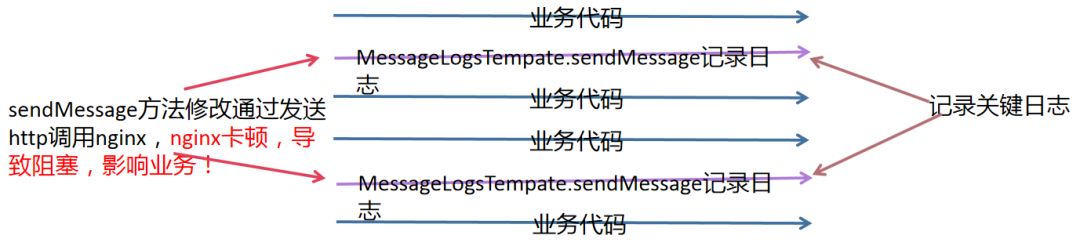
所以 sendMessage 方法继续修改:
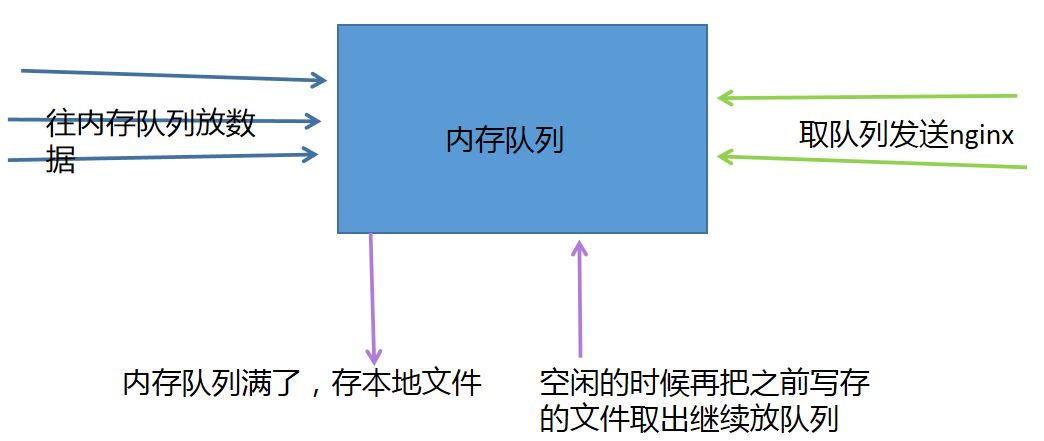
最终我们的日志发送就变成:
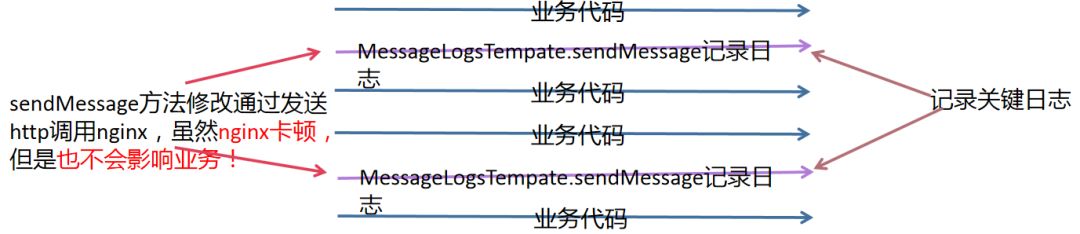
日志发送完全异步,不管什么情况都不会影响业务!!!
日志存储也同样经历了三个过程:
走 DB 存储 ;
走 SolrCloud 存储 ;
走 ES 集群存储
现在我们讨论后半段,之前不管是走 ActiveMQ 还是后面的异步 Nginx 过程,开始的时候我们都是把数据存储在 DB 里。2012-2013 年的时候,数据不是特别多,也没发现特别大的问题,虽然搜索不太方便,但是还是可以搜索的(需要输入业务编码 ,相应属性输入值)

从上图可以发现,搜索不是特别方便,并且各个业务编码之间也不能相互搜索,一次只能搜索一个编码!但是还是可以使用,并且解决了很多问题! 随着业务发展,日志越来越多,慢慢的数据入 DB 就跟不上了,就会面临一个问题:有时候一个日志生产了,但需要很久才可以查询的到。所以,我们就开始考虑解决这个问题,将单条插入修改为批量插入,性能提高了 n 倍,勉强做到了:日志产生后,5 分钟内可以处理入 DB。但是还是会有其它问题出现:
查询速度越来越慢!
跨业务编码间的搜索诉求越来越大!
模糊搜索很不理想!
针对这些问题,我们进行了专门的调研,SolrCloud 就进入了我们的视线了,solr 具备高级全文搜索能力:由 Lucene ™提供支持,Solr 可实现强大的匹配功能,包括短语、通配符、联接、分组以及任何数据类型 。
通过对 Solr 的研究,我们用 Solr 替换掉了 DB,从而达到了下面的搜索情况:
不管搜索体验,还是搜索效率,都提高了很多,引入 SolrCloud 算是质的飞跃! 并且还具备高亮,通过关键词、人员相关字段都可以进行匹配搜索到,如下:
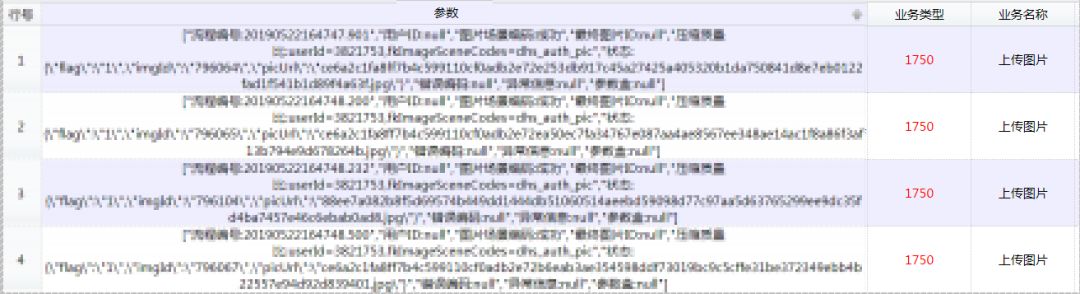
选择一条记录点击,出现明细如下:
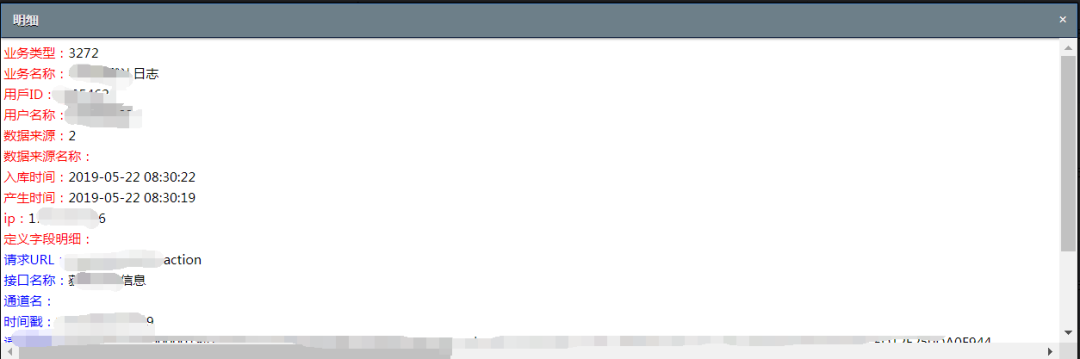
字段的解释名也会出现在行的左侧(这个就是之前配置的业务编码,不同的业务编码对应的字段是不一样的),后面是对应的值!
如果搜索条件在各个编码里面,如下,并且搜索的条件是 红色 的:
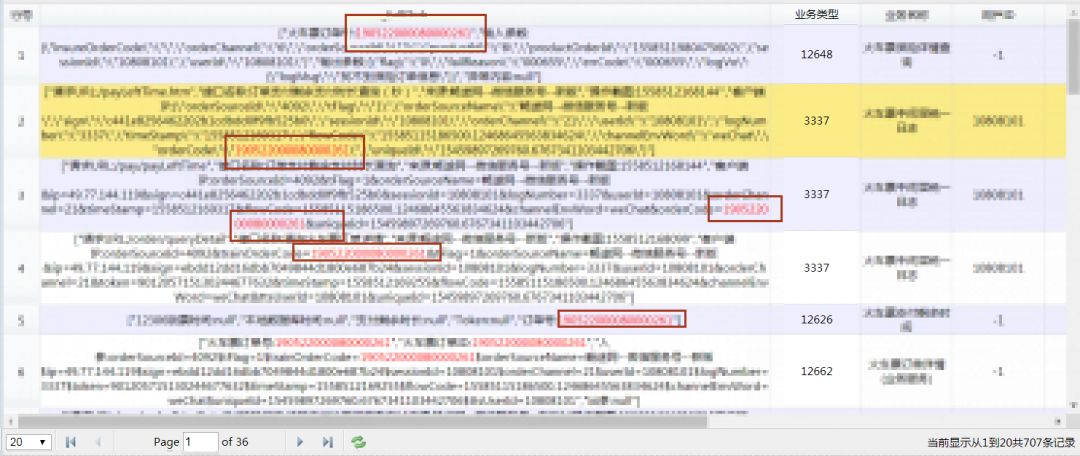
到这里之后,我们如果有什么问题,可以通过搜索这套日志系统,就可以快速准确的排查定位问题。这套系统不仅仅给开发查询问题,在周末、节假日值班的时候,我们的维护也通过可以通过这套系统进行查询,初步定位问题,解决 90% 的问题。剩余的 10% 的问题再到相应开发人员定位解决,提高了处理问题的响应速度,给用户一个好的体验!
本以为到这里很完美了,那里知道又要经历一波折磨人的时刻!
由于引入了 SolrCloud,业务发展迅速,日志量越来越多,1 天 2-3 亿的日志数据,查询速度在 1s 左右可以返回,但是 SolrCloud 忽然变的不稳定。
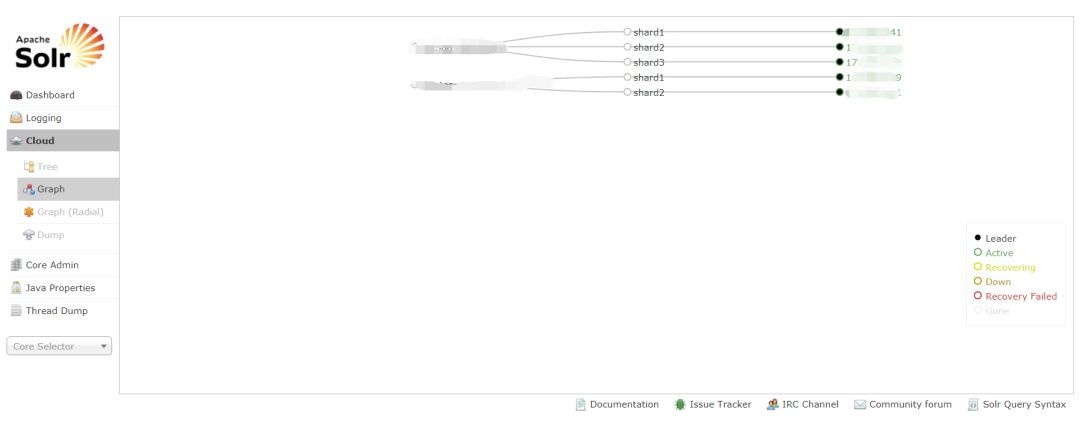
经常出现 SolrCloud OOM,需要重启,每次开发人员、维护人员都在喊:日志查不了!!! 每次都需要重启之后补数据,特别节假日,晚上非常麻烦(SolrCloud 太复杂当时没有想着看代码解决,曲线解决问题,我们定时 2 小时执行一次 FGC)经过执行 FGC 之后,出现频率问题低很多了,但是偶然还是会出现 OOM。
针对 SolrCloud 的问题很头疼,后来搜索发现 Elasticsearch 和 Solr 类似,并且互联网很多公司都用的是 ES,决定研究下 ES,看看是否可以采用!
通过研究 Elasticsearch 发现和 Solr 基本类似,替代也比较简单,就给替换了。
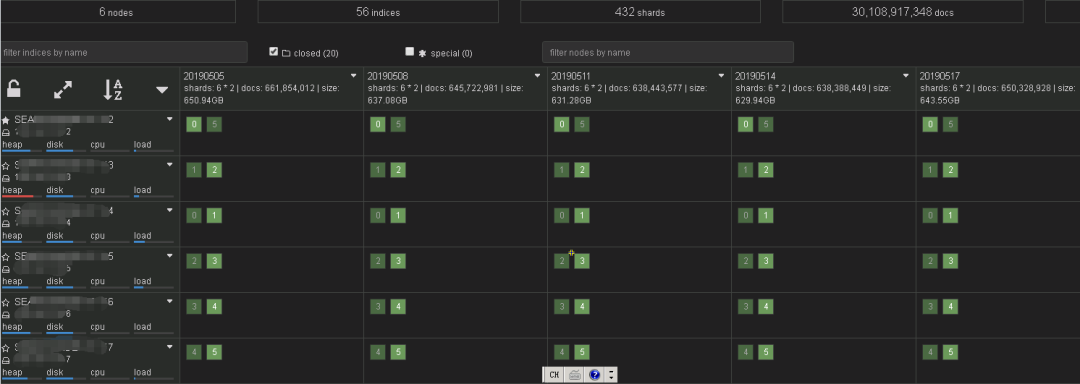
目前 Elasticsearch 运行时间 2 年多了,并没有像 Solr 那样的出现过 OOM 等情况,非常稳定,这段期间也对 Elasticsearch 进行过一些方面的优化(以后可以和大家分享)!
同一份数据多份去向的处理逻辑修改,由于之前我们的日志数据仅仅是流向到了 Elasticsearch 集群,而有些数据特定的业务编码数据可能需要入库,有些需要进行大数据 fsdf,或者 Redis 或者 Kafka 中供大数据那边分析,所以我们对数据处理进行了修改,支持多种去向,并且做到已经有的处理可以立即配置生效。
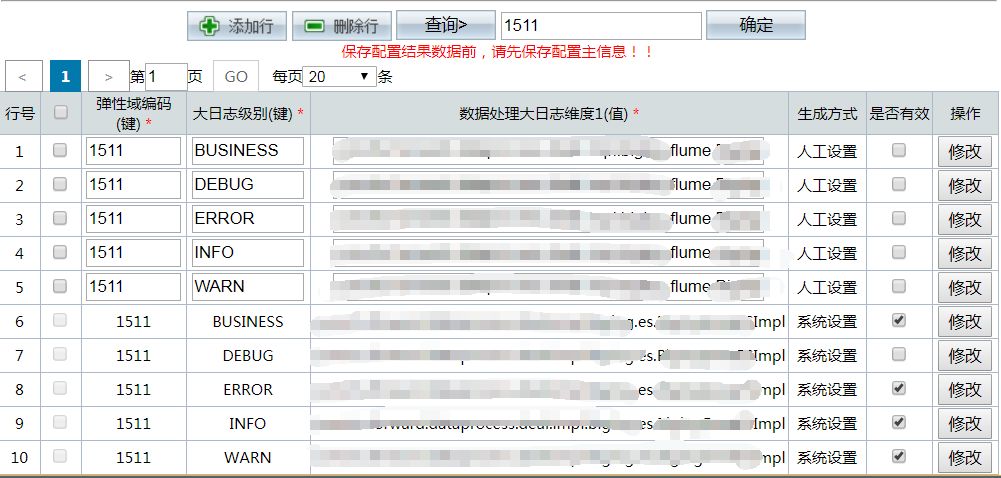
由于日志系统太好用,记录的越来越多,我们发现有些日志没有必要,所以就对日志进行了分级(借鉴 log4j 的日志级别),这样很多一些低级别日志就不进入 Elasticsearch 了。
我们日志的去向也可以根据业务编码进行动态的调整,控制去哪个维度,从而做到了灵活。
这套畅途业务日志系统经历了很多迭代,集合了很多人的智慧,不仅易用好用,而且可以快速准确的定位问题。希望我们做到的这套日志系统能够对读者有所帮助,我们要的不是屌炸天技术,而是稳定可靠易用,未来这套日志系统可能还会继续进行升级。
作者介绍
李仁佐,畅途网平台技术团队负责人。致力技术研究、难点攻破和基础服务建设。
王哲民,畅途网技术总监。
王杰,畅途网大数据及技术研发中心经理。
今日推荐
如何搭建百万级别并发的 Web 应用?作为一个兼具开发效率和性能的服务端开发平台,OpenResty 虽然基于 Nginx 实现,但其适用范围早已超出反向代理和负载均衡。掌握了 OpenResty,就能同时拥有脚本语言的开发效率和迭代速度,以及 Nginx C 模块的高并发和高性能优势。
OpenResty 软件基金会主席温铭,带你系统掌握一款高性能开发利器。
限时¥68,原价 ¥129,半价到手,你没看错,扫描二维码或点击「阅读原文」免费试读。