【技术贴】P2P运营手册:怎样摸透用户的投资产品偏好 并打上标签
用户画像,想必运营的小伙伴们都非常熟悉,核心工作就是给用户打标签,以便后续更好执行后续营销策略与精细化营销。标签有多种,比如年龄、地域、收入等等。今天我们就用聚类方法来给用户打标签,根据用户在平台的购买产品情况来判断这个人的购买偏好,加之以标签,并针对各类用户未来制定营销计划。
我们会用4种常用聚类模型进行分析,并最终对这4种模型进行综合评定,选出最佳模型进行聚类分析。这4种模型分别是:K-mediod、K-means、两步法和kohonen。
下面我们先对这四种模型进行简单的介绍:
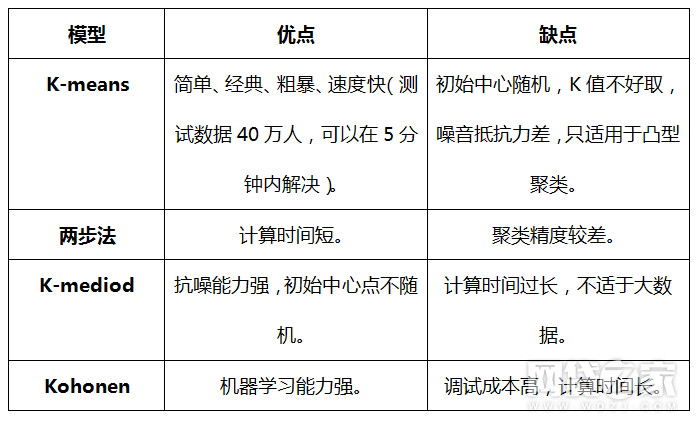
以欧氏距离作为相似度测量的硬聚类算法,算是聚类算法中的“一哥”,本人也经常使用,在我之前文章中也多次提及,算法这里就不在赘述了。
k-mediod和Kmeans算法核心思想大同小异,但是最大的不同是在修正聚类中心的时候,k-mediod是计算类簇中除开聚类中心的每点到其他所有点的聚类的最小值来优化新的聚类中心。因此,相对于K-means,k-mediod优点在于对噪声和孤立点不敏感。缺点是计算时间过于冗长。K-mediod需要不断的找出每个点到其他所有点的距离的最小值来修正聚类中心,这大大加大了聚类收敛的时间。
Kohonen网络是自组织竞争型神经网络的一种,该网络为无监督学习网络,能够识别环境特征并自动聚类
Kohonen神经网络算法工作机理是在网络学习过程中,当样本输入网络时,竞争层上的神经元计算输入样本与竞争层神经元权值之间的欧几里德距离,距离最小的神经元为获胜神经元。调整获胜神经元和相邻神经元权值,使获得神经元及周边权值靠近该输入样本。通过反复训练,最终各神经元的连接权值具有一定的分布,该分布把数据之间的相似性组织到代表各类的神经元上,使同类神经元具有相近的权系数,不同类的神经元权系数差别明显
第一步打开程序,第二部出数完事!开玩笑…
第一步 预聚类阶段:采用了BIRCH算法中的CF树生长的思想,随后逐个读取数据集中数据点,在生成CF树的同时,预先聚类密集区域的数据点,形成子簇。
第二部 聚类:以第一步形成的子簇为对象,利用凝聚法(agglomerative hierarchical clustering method),逐个地合并子簇,直到期望的簇数量
以上简单的介绍了4种常用聚类算法的算法,下面我们就要过关斩将,选出最佳模型进行用户划分。
模型评定主要通过计算时间、聚类质量和综合评定的三个方面来评定模型,时间顾名思义就是计算所用时长,如果一个算法优秀但时间过于冗长,导致不能及时更新平台标签,这种算法也是不可取的;聚类质量就是模型聚类的好坏,主要用轮廓系数这个指标来衡量模型的质量。综合评定就是根据模型的优劣局限性等因素,并针对此次分析进行的综合评定。
我们通过对4种算法的计算时间进行排序,得出以下结果:
k-mediod 《 kohonen 《 两步 ≈ K-means
我们发现k-mediod计算时间过于冗长。因为k-mediod需要不断的找出每个点到其他所有点的距离的最小值来修正聚类中心,这大大加大了聚类收敛的时间。K-mediod对于大规模数据聚类消耗时间过长,只能适应较小规模的数值聚类,对于互金这种动则上百万用户的数据量来说是吃不消的,所以k-mediod被淘汰。
接下来,我们就对模型质量进行评估,利用spss modeler进行自动聚类快速处理,得到如下图。

自动聚类图
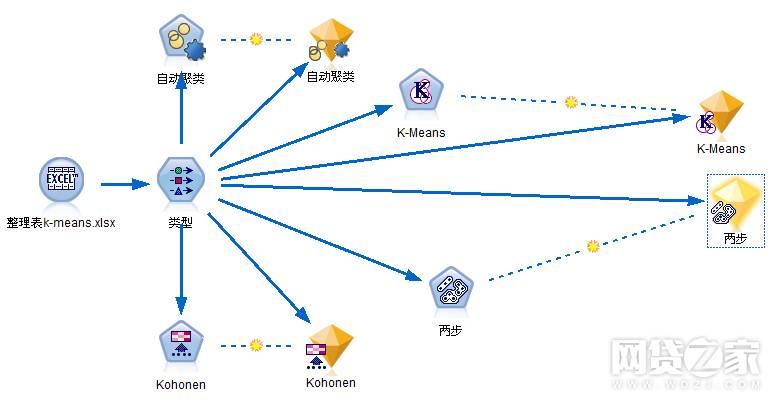
模型流程图
我们按照轮廓系数进行筛选(介于[-1,1]间,越接近1表示聚类结果越好),对于监督式学习,在训练完成后用准确率评价模型。但聚类属于无监督式学习,所以要用到凝聚和分离的轮廓评价模型的好坏。首先可以看出k-means(K=7)的轮廓系数为0.7,两步算法轮廓系数为0.614,kohonen为0.475。在这里有个小问题,为什么K-means的K值为7呢,大家都知道K-means的K值对聚类结果影响很大,我们不妨来做一个K值与轮廓系数图,就一目了然了,如下图。
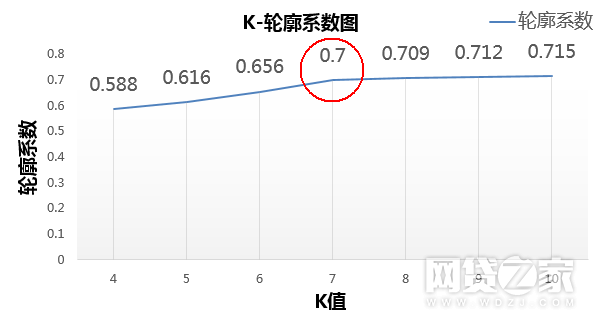
K与轮廓系数关系图
在K《7时轮廓系数增长明显,当K《7时增长缓慢几乎保持不变,又知如果K值过大,会造成过度聚类。所以K=7时,即保证准确度又不会出现过度聚类的情况发生,所以K=7为最优值。
按照聚类质量分析,将k-means、k-mediod、两步和kohonen四种模型进行排序,结果如下:
K-means (0.7) 《 kohonen(0.57) 《 kmediod(0.56) 《 两步(0.405)
K-means聚类分析:本次分析中,数据不存在噪音(数据预处理去噪)和凸型聚类问题,而且数据量超过百万,所以综上所述选取轮廓系数高,我们选择计算时间快,并且在此次分析中不受其自身局限性影响的K-means模型进行聚类分析。
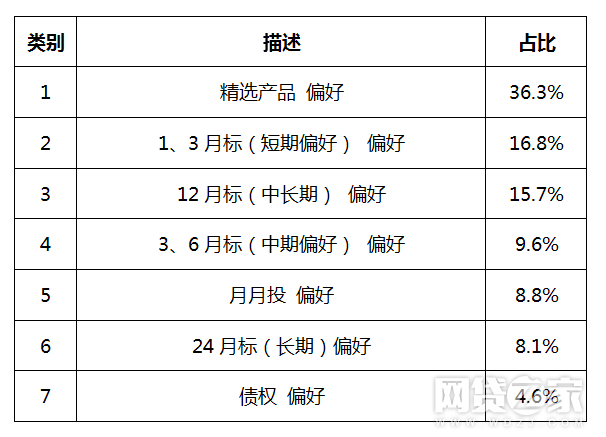
选定K-means后,下面对平台用户投资行为进行分析,将现有人群分为7类(K=7,刚才已经对K的最优值选取进行分析),可以看到聚类结果概要图,如下图:
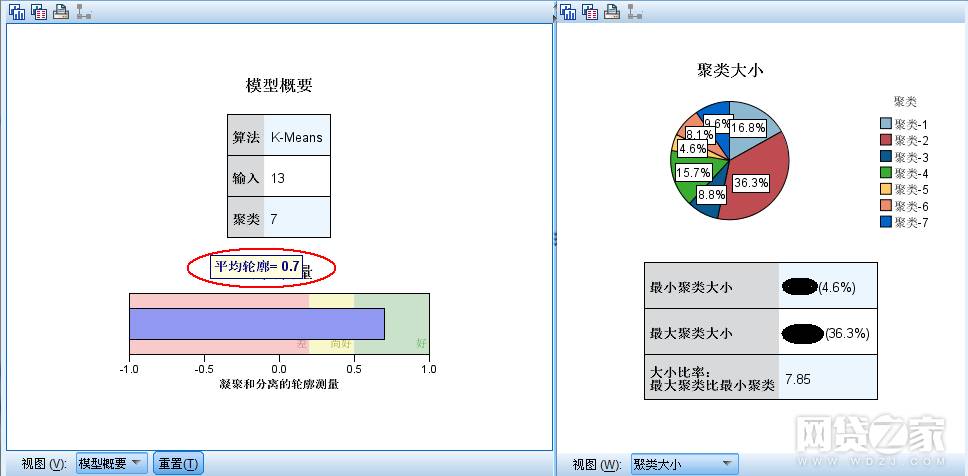
K-means模型结果概要图
分为以下7类人群:
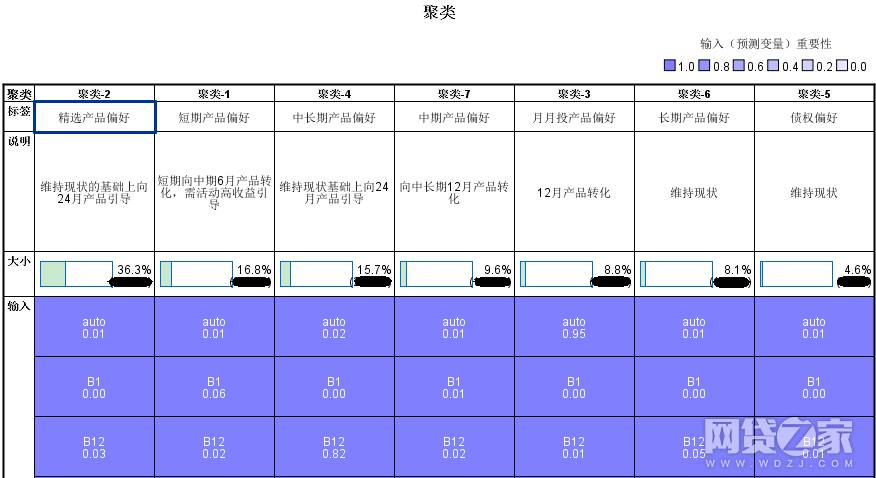
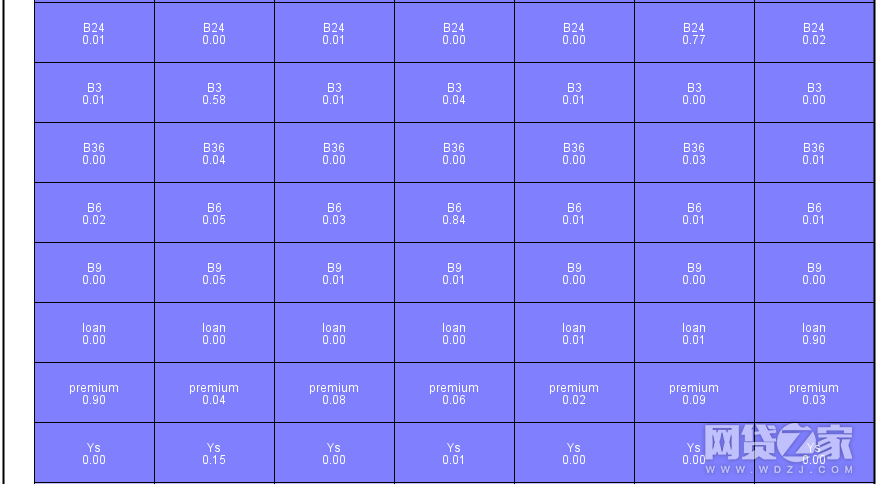
聚类明细

最终将分类结果出数为EXCEL表,如下图:
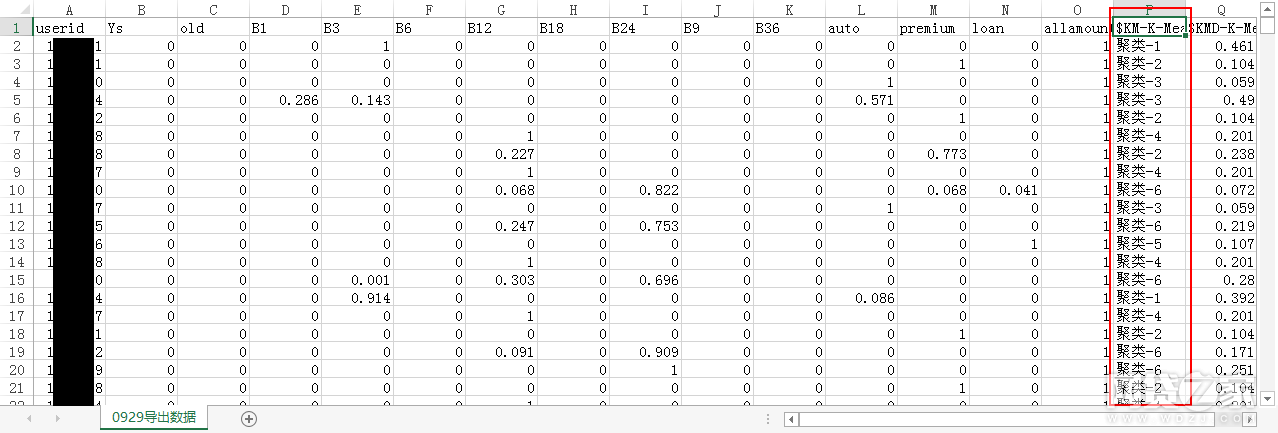
导出表
至此,整个流程基本完毕,只需在数据库中对用户添加标签即可。
我们就把今天分析的过程来捋一捋:
用户投资偏好画像 《 聚类 《 选择模型 《 最优模型确立 《 聚类分析 《 得出结论 《 数据库打标签
正所谓磨刀不误砍柴工,我们把大部分的时间都用在选择最优模型上,在后期既能节省运算时间,又能保证计算的质量。今天就讲到这里,用户在其他维度也有很多标签, 比如生命周期标签、收益喜好标签等等,以后再跟大家分享。
写在后面:希望这篇文章可以帮助广大的互金运营人士,也能够让广大的互金用户了解平台运营方式,同时欢迎互金同行与爱好者一起交流学习,提出您宝贵的意见。
作者:姜頔
来源:网贷之家
行业时事
英国发布ICO和数字货币风险警告 摩根大通CEO炮轰数字货币
案例分析
Random Forest Capital:利用机器学习对每笔贷款进行再定价
监管动态
传北京约谈比特币交易平台 发布虚拟货币交易所清理整治工作要求
央行:ICO属非法公开融资,各类代币发行融资活动应当立即停止
深度观察
活动&荐书
清华大学五道口金融学院互联网实验室成立于2012年4月,是中国第一家专注于互联网金融领域研究的科研机构。
专业研究 | 商业模式 • 政策研究 • 行业分析
内容平台 | 未央网 • "互联网金融"微信公众号iefinance
创业教育 | 清华大学中国创业者训练营 • 全球创业领袖项目(报名中!点击查看详情)

网站:未央网 http://www.weiyangx.com
免责声明:转载内容仅供读者参考。如您认为本公众号的内容对您的知识产权造成了侵权,请立即告知,我们将在第一时间核实并处理。
WeMedia(自媒体联盟)成员,其联盟关注人群超千万




