统计学习要素(The Elements of Statistical Learning)的中文翻译、代码实现及其习题解答,附下载
【导读】斯坦福《统计学习要素》一直是机器学习领域公认经典的教材,是一本在机器学习、统计推理和模式识别领域有影响力和被广泛研究的书。而这本书一直没有得到中文翻译。近期由szcf-weiya博士整理翻译的The Elements of Statistical Learning (ESL)的中文翻译、代码实现及其习题解答公开,非常值得学习!

The Elements of Statistical Learning中文版

ESL中文版是由香港中文大学Lijun Wang博士创作的,统计学专业,包括中文翻译、代码实现及其习题解答。
项目地址:
https://github.com/szcf-weiya/ESL-CN
https://esl.hohoweiya.xyz/
序言
We are drowning in information and starving for knowledge. –Rutherford D. Roger
我们沉浸在信息中并且渴望知识。—— 卢瑟福 D.罗杰
统计学持续被科学和工业中问题所挑战。早些年,这些问题来自农业和工业实验,而且相对较小。随着计算机和信息的迅速发展,统计学问题在规模和复杂性上爆炸性增长。在数据存储、组织和搜索方面的挑战引入到了一个新的领域——数据挖掘;在生物方面的统计和计算问题形成了“生物信息学”。大量的数据正在各个领域产生,而统计学家们的工作便是搞清楚一切:提取重要特征和趋势,并且明白这些“数据在说什么”。我们称之为从数据中学习。
从数据中学习的挑战促使了统计学的革命。因为计算扮演着关键性的角色,所以很多新的发展是被像计算科学和工程这些领域的研究者完成并不奇怪。
我们考虑的学习的问题可以大致分为两大类:监督和非监督。在监督学习中,目标是根据一系列输入度量来预测输出度量的值。而在非监督学习中,没有输出度量,它的目标是描述一系列输入度量之间的联系。
这本书是我们对把在“学习”中许多重要的想法聚集起来用统计学的框架来解释的一种尝试。尽管一些数学细节是必要的,但是我们更多地强调方法以及基础的概念,而不是理论性质。因此,我们希望这本书不仅吸引统计学家,同时能够吸引更多领域的研究者们。
正如我们从非统计学领域的研究者们那里学到了很多,我们统计学的观点或许帮助其他领域的研究者们更好地理解学习的不同方面。
任何事情没有绝对正确的解释,解释只是帮助人类更好理解的一项工具而已。解释的价值是在于确保他人能够富有成效地思考一个想法。——Andreas Buja
目录
第一章:导言
第二章:监督学习的综述
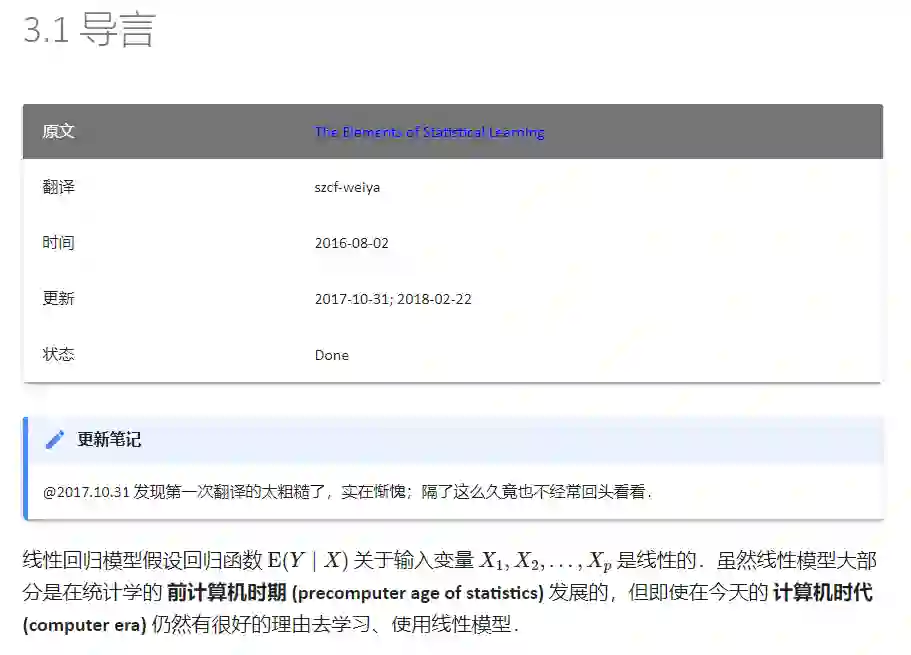
第三章:回归的线性方法(新:LAR算法和lasso的一般化)
第四章:分类的线性方法(新:逻辑斯蒂回归的lasso轨迹)
第五章:基本的扩展和正则化(新:RKHS的补充说明)RKHS(再生核希尔伯特空间)
第六章:核光滑方法
第七章:模型评估与选择(新:交叉验证的长处与陷阱)
第八章:模型推论与平均
第九章:补充的模型、树以及相关的方法
第十章:Boosting和Additive Trees(新:生态学的新例子,一些材料分到了16章)
第十一章:神经网络(新:贝叶斯神经网络和2003年神经信息处理系统进展大会(NIPS)的挑战)
第十二章:支持向量机和灵活的判别式(新:SVM分类器的路径算法)
第十三章:原型方法和邻近算法
第十四章:非监督学习(新:谱聚类,核PCA,离散PCA,非负矩阵分解原型分析,非线性降维,谷歌pagerank算法,ICA的一个直接方法)
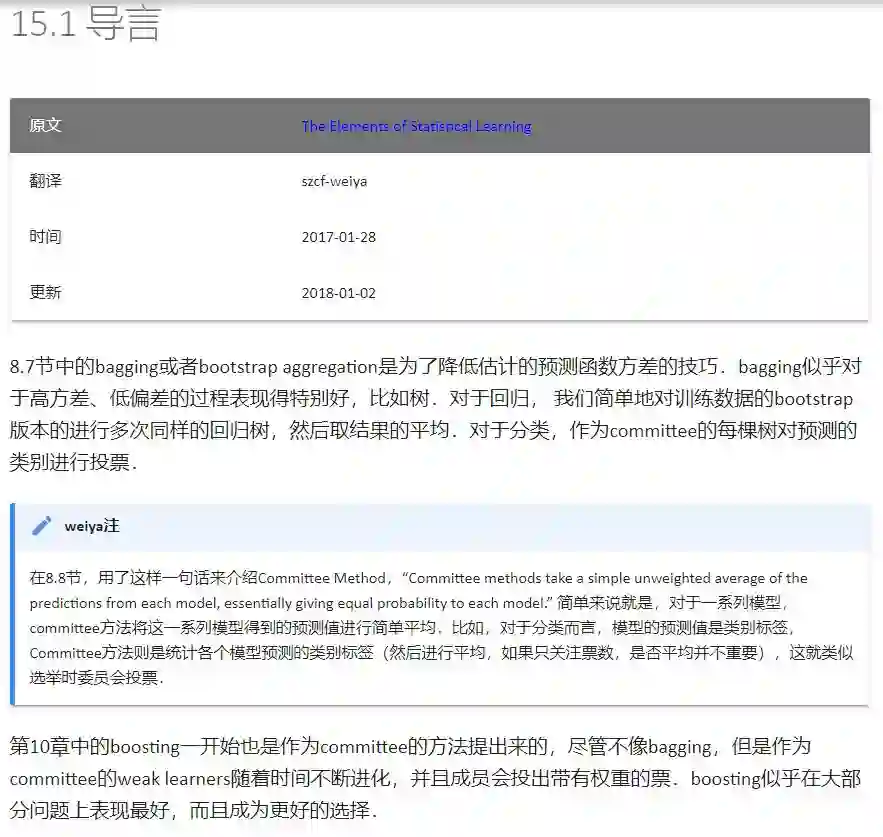
第十五章:随机森林
第十六章:实例学习
第十七章:无向图模型
第十八章:高维问题


习题解答

代码实现
EM 算法模拟
朴素贝叶斯进行文本挖掘
CART实现
AdaBoost实现R&Julia
MARS实现
RBM,或者可以查看 Jupyter Notebook
Gibbs
Self-organized Map
kernel estimation
Resampling Method: 包括交叉验证(cv)和自助法(bootstrap)
Neural Network: Simple Classification,Implementation for Section 11.6
高维问题例子: 例18.1的模拟
便捷查看:请关注专知公众号(点击上方蓝色专知关注)
后台回复“ESL” 就可以获取《统计学习要素(The Elements of Statistical Learning)》电子书pdf下载链接~
更多统计学习资料,请上专知网站查看
https://www.zhuanzhi.ai/topic/2001035706592432/vip



相关内容

社会学/环境学(社会统计学,心理学,人口学,空间统计学,环境统计学等)
工业工程学(质量控制,可靠性分析等)
经济学/金融学(精算学,金融统计学等)
工程学/计算机科学(统计学习,数据挖掘,信号/图像采样/处理等)
基础科学(统计物理学,统计化学等)



