开源自动语音识别系统wav2letter (附实现教程)

wav2letter 是由 Facebook AI 研究团队开源的一款简单而高效的端到端自动语音识别系统,它实现了在 WavLetter:an End-to-End ConvNet-based Speed Recognition System 和 Letter-Based Speech Recognition with Gated ConvNets 这两篇论文中提到的架构。它将基于卷积网络的声学模型和图解码结合起来,通过转录的语音训练后,无需强制对齐音素,系统就可以输出字母。
论文地址:
(1)WavLetter:an End-to-End ConvNet-based Speed Recognition System
https://arxiv.org/abs/1609.03193
(2)Letter-Based Speech Recognition with Gated ConvNets
https://arxiv.org/abs/1712.09444
GitHub 地址:
https://github.com/facebookresearch/wav2letter
如果你想要立刻进行语音转录,我们提供了在 Librispeech 数据集上预训练的模型。
Librispeech 数据集:http://www.openslr.org/12
运行要求
MacOS 或 Linux 操作系统
Torch框架
在 CPU 上训练:Intel MKL
在 GPU 上训练:NVIDIA CUDA Toolkit (cuDNN v5.1 for CUDA 8.0)
读取录音文件:Libsndfile(必须在任何标准发行版中可用)
标准语音特征:FFTW(必须在任何标准发行版中可用)
安装
1. MKL
如果你打算在 CPU 上训练,我们强烈推荐安装 Intel MKL。
通过以下代码更新你的 .bashrc 文件
2. LuaJIT + LuaRocks
以下代码在本地的$HOME/usr 安装了 LuaJIT 和 LuaRocks。如果你需要全系统的安装,请删除-DCMAKE_INSTALL_PREFIX=$HOME/usr 选项。

在下一部分,我们假定 LuaJIT 和 LuaRocks 被安装在了路径$PATH。如果不是,并假定你将它们安装在了本地的$HOME/usr,你需要替换成运行~/usr/bin/luarocks 和 ~/usr/bin/luajit。
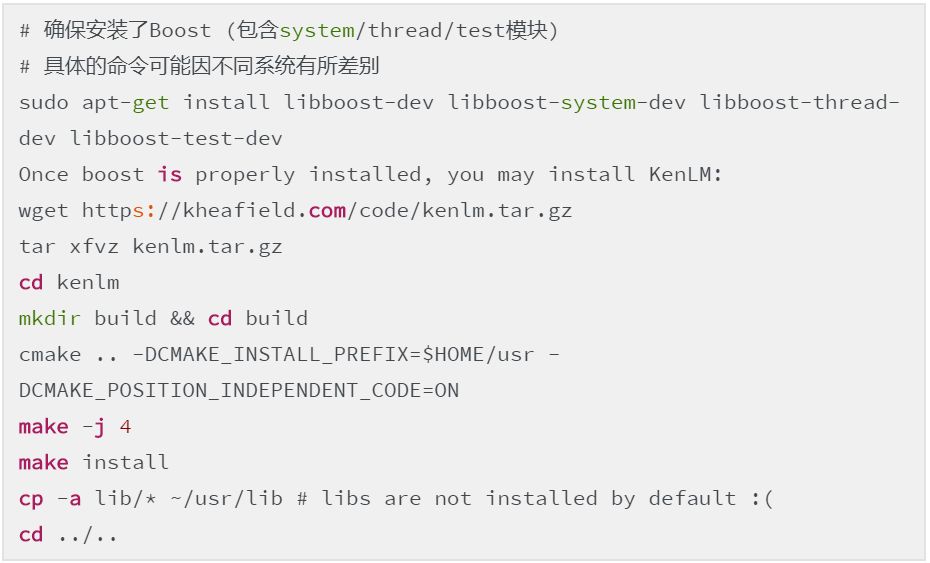
3. KenLM 语言模型工具包
运行 wav2letter 解码器需要 KenLM 工具包,运行 KenLM 需要安装 Boost 库。
4. OpenMPI 和 TorchMPI
如果想使用多 CPU 或多 GPU 训练(或多机器训练),你需要安装 OpenMPI 和 TorchMPI。
建议重编译 OpenMPI。OpenMPI 二进制文件的标准发行版的编译标签存在很大的方差。特定的标签对于成功地编译和运行 TorchMPI 很关键。
首先安装OpenMPI:

注意:这里也可以使用 openmpi-3.0.0.tar.bz2,但需要将—enable-mpi-thread-multiple 删除。
现在可以安装 TorchMPI 了:
5. 安装 Torch 和其它的 Torch 包
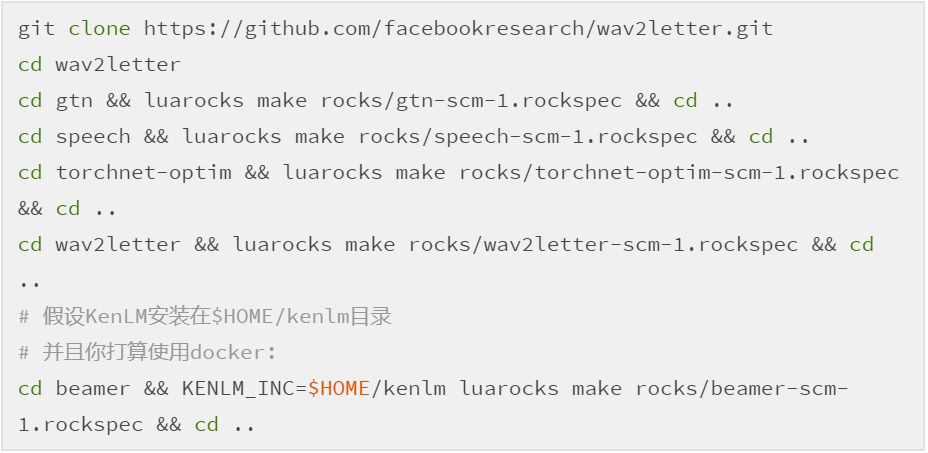
6.安装 wav2letter 包
训练 wav2letter 模型
1. 数据预处理
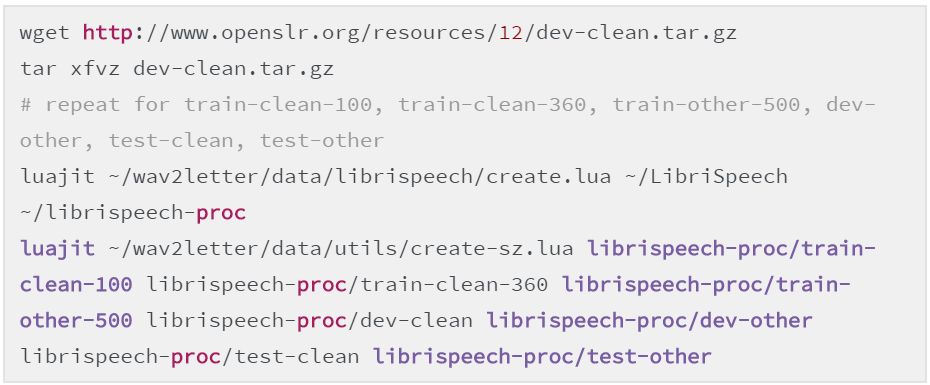
数据文件夹包含多个用于预处理多种数据集的脚本。目前我们仅提供 LibriSpeech 和 TIMIT。
以下是预处理 LibriSpeech ASR 语料库的例子:
2. 训练

3. 在多 GPU 上训练
使用 OpenMPI 进行多 GPU 训练:

这里假定 mpirun 位于$PATH
运行解码器(推理)
运行解码器之前,需要做些预处理步骤。
首先,创造一个字母词典,里面包含 wav2letter 中使用到的特殊重复字母

然后用一个语言模型,做预处理。在这里,我们使用的是基于 LibriSpeech 的预训练语言模型,你们也可以使用 KenLM 训练自己的语言模型。然后,把单词预处理转化为小写字母,在 dict.lst 特定词典中生成字母录音文本(带有重复字母)。该脚本可能会提醒你哪个单词转录错误,因为重复字母数量不对。在我们的案例中不存在这种情况,因为这种词非常少。

注意:也可以使用 4-gram 预训练语言模型 4-gram.arpa.gz 作为替代,预处理可能花费的时间比较长。
可选项:用 KenLM 将其转化为二进制格式,后续载入语言模型,可加速训练时间(我们在这里假定 KenLM 位于你的$PATH)。
build_binary 3-gram.pruned.3e-7.arpa 3-gram.pruned.3e-7.bin
我们现在可以生成特定训练模型的 emissions,在数据集上运行 test.lua。该脚本展示了字母错误率(LER)与词错率(WER),后者是在声学模型没有后处理的情况下计算的。

一旦 emissions 存储好,可运行解码器计算通过用特定语言模型约束解码获得的词错率:

预训练模型
我们提供了基于 LibriSpeech 的完整预训练模型:

为了使用该模型做语音转录,我们需要遵循该 github 项目中 README 的 requirements、installation 和 decoding 部分。
注意,该模型是 Facebook 基础设施上的预训练模型,所以你需要运行 test.lua 使用它,有略微不同的参数:

1月27日,七月在线【 语音识别技术的前世今生】开课,带你了解更多语音识别技术。扫描下方二维码立即报名!
王赟:美国卡内基梅隆大学(CMU)计算机学院语言技术研究所(LTI)博士。曾在清华电子系专业课排名第一,后在Facebook语言技术组实习,现在CMU专攻语音识别。




