未来 3~5 年内,哪个方向的机器学习人才最紧缺?
作者:紫杉
链接:https://www.zhihu.com/question/63883507/answer/227977296
灵活解决问题的人
专精一个领域的人
我:“你最擅长的人工智能领域是什么呢?” 伊森:“我什么都会(jack-of-all-trades)。” (评论:这很容易误导招聘者让他们觉得你样样都不专精) 我:“你在寇克德福尔教授那里做了什么样的研究呢?” 伊森:“我给无人机搭建了一个服务器,用了Kafka做流处理。” (评论:这句话暴露缺乏研究经历)——虽然Kafka也还算是有趣 我:“怎样的工作在你看来最有趣呢?” 伊森:“我想有机会把最前沿的算法应用在公司的业务中。” (评论:算法没有前沿与不前沿之分,只有合适与不合适之分) 我:“你理想的工作岗位是什么呢?” 伊森:“我其实最想当人工智能的产品经理。” (评论:其实产品经理的收入不如程序员哦)
能够把学术模型转化成工业模型的人
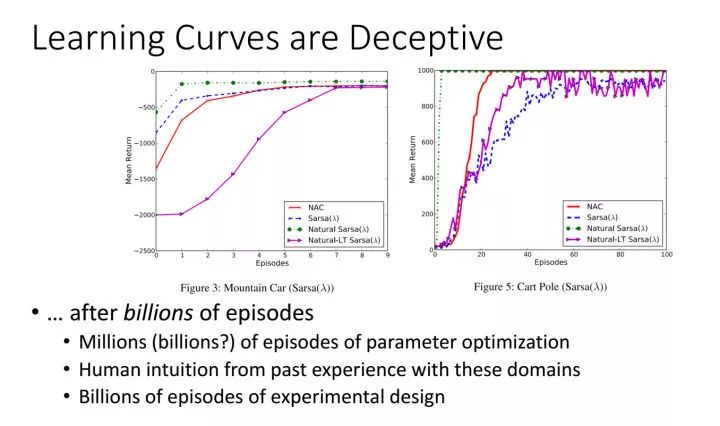
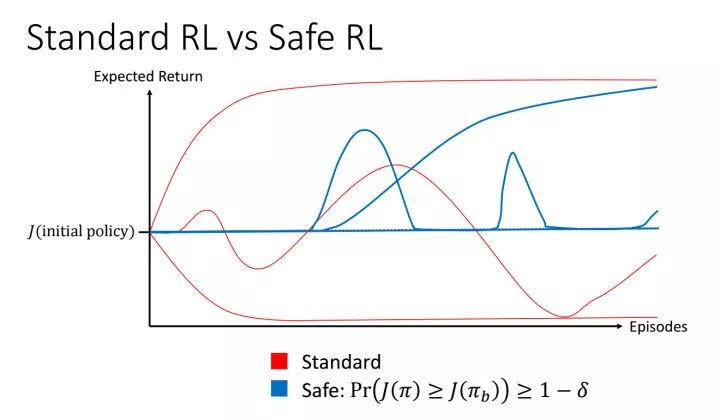
 算法。
算法。
能够研究深度学习理论的人
●编号892,输入编号直达本文
●输入m获取到文章目录

程序员求职面试
登录查看更多
相关内容

斯坦福大学计算机科学学院助理教授,伍兹环境研究所Fellow。他主要研究在图形模型中的可伸缩技术以及精确推理,数据统计建模,大规模组合优化和不确定性下的鲁班决策,特别是在新兴的计算可持续领域。
Arxiv
10+阅读 · 2018年4月11日
Arxiv
10+阅读 · 2018年2月27日





相关VIP内容
相关资讯
相关论文
Arxiv
10+阅读 · 2018年4月11日
Arxiv
10+阅读 · 2018年2月27日