1秒出图,全球最快的开源Stable Diffusion出炉
机器之心发布
OneFlow 将 Stable Diffusion 的推理性能推向了一个全新的 SOTA。
第一辆汽车诞生之初,时速只有 16 公里,甚至不如马车跑得快,很长一段时间,汽车尴尬地像一种“很酷的玩具”。人工智能作图的出现也是如此。
AI 作图一开始的 “风格化” 本身就为 “玩” 而生,大家普遍兴致勃勃地尝试头像生成、磨皮,但很快就失去兴趣。直到扩散模型的降临,才给 AI 作图带来质变,让人们看到了 “AI 转成生产力” 的曙光:画家、设计师不用绞尽脑汁思考色彩、构图,只要告诉 Diffusion 模型想要什么,就能言出法随般地生成高质量图片。
然而,与汽车一样,如果扩散模型生成图片时“马力不足”,那就没法摆脱玩具的标签,成为人类手中真正的生产工具。
起初,AI 作图需要几天,再缩减到几十分钟,再到几分钟,出图时间在不断加速,问题是,究竟快到什么程度,才会在专业的美术从业者甚至普通大众之间普及开来?
显然,现在还无法给出具体答案。即便如此,可以确定的是 AI 作图在技术和速度上的突破,很可能已经接近甚至超过阈值,因为这一次,OneFlow 带来了字面意义上 “一秒出图” 的 Stable Diffusion 模型。
OneFlow Stable Diffusion 使用地址:https://github.com/Oneflow-Inc/diffusers/wiki/How-to-Run-OneFlow-Stable-Diffusion
OneFlow 地址:https://github.com/Oneflow-Inc/oneflow/
比快更快,OneFlow 一马当先
下面的图表分别展示了在 A100 (PCIe 40GB / SXM 80GB)、RTX 2080 和 T4 不同类型的 GPU 硬件上,分别使用 PyTorch, TensorRT, AITemplate 和 OneFlow 四种深度学习框架或者编译器,对 Stable Diffusion 进行推理时的性能表现。
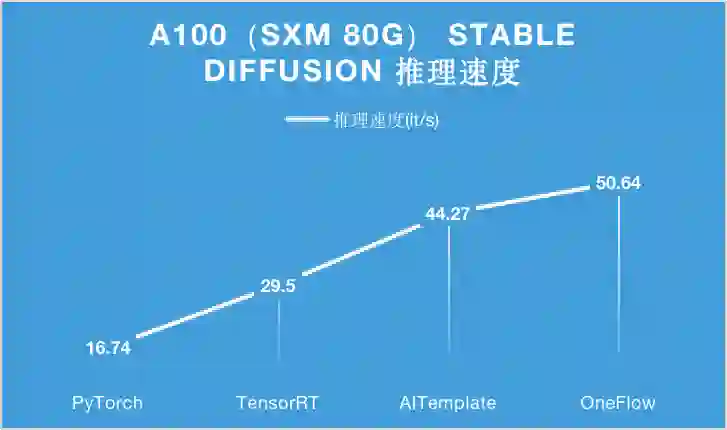
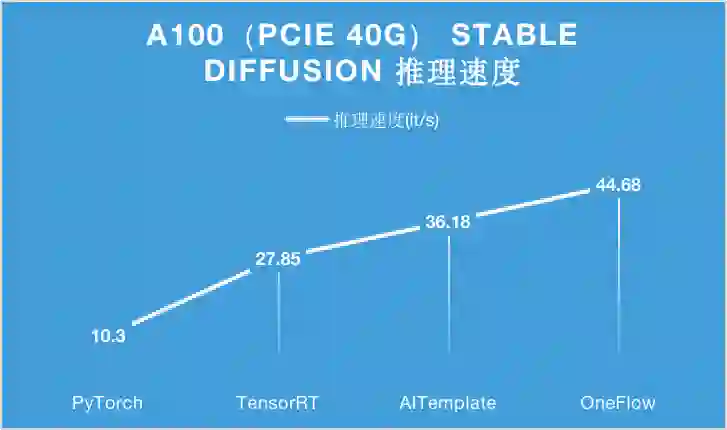
对于 A100 显卡,无论是 PCIe 40GB 的配置还是 SXM 80GB 的配置,OneFlow 的性能可以在目前的最优性能之上继续提升 15% 以上。
特别是在 SXM 80GB A100 上,OneFlow 首次让 Stable Diffusion 的推理速度达到了 50it/s 以上,首次把生成一张图片需要采样 50 轮的时间降到 1 秒以内,是当之无愧的性能之王。
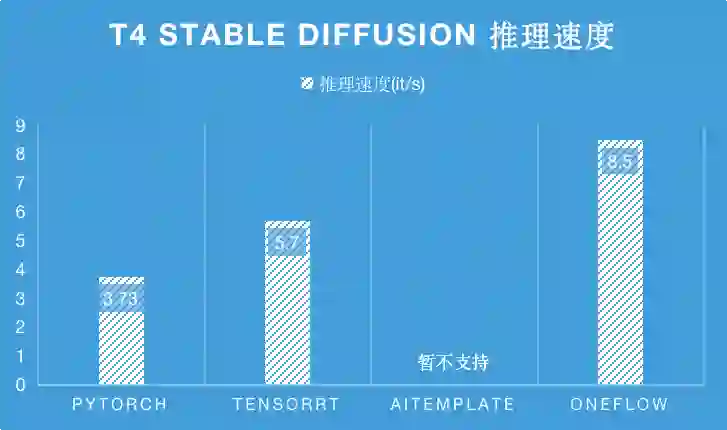
在 T4 推理卡上,由于 AITemplate 暂不支持 Stable Diffsuion,相比于目前 SOTA 性能的 TensorRT,OneFlow 的性能是它的 1.5 倍。
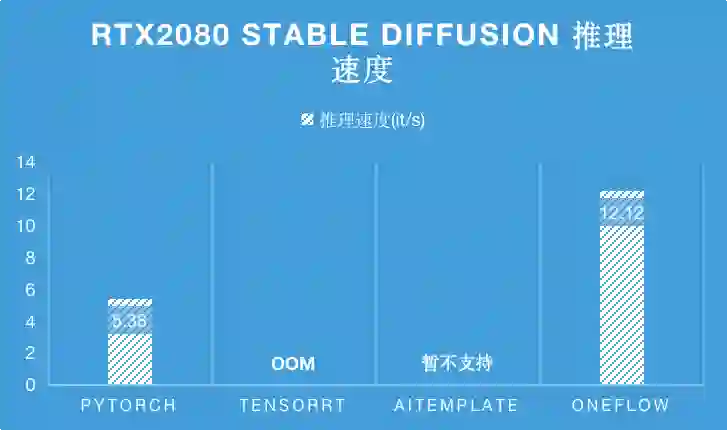
而在 RTX2080 上,TensorRT 在编译 Stable Diffsuion 时会 OOM ,相比于目前 SOTA 性能的 PyTorch,OneFlow 的性能是它的 2.25 倍。
综上,在各种硬件以及更多框架的对比中,OneFlow 都将 Stable Diffusion 的推理性能推向了一个全新的 SOTA。
生成图片展示
利用 OneFlow 版的 Stable Diffusion,你可以把天马行空的想法很快转化成艺术图片,譬如:
以假乱真的阳光、沙滩和椰树:

仓鼠救火员、长兔耳朵的狗子:

在火星上吃火锅:

未来异世界 AI:

集齐 OneFlow 七龙珠:

上述图片均基于 OneFlow 版 Stable Diffusion 生成。如果你一时没有好的 idea,可以在 lexica 上参考一下广大网友的创意,不仅有生成图片还提供了对应的描述文字。

无缝兼容 PyTorch 生态,实现一键模型迁移
想体验 OneFlow Stable Diffusion?只需要修改三行代码,你就可以将 HuggingFace 中的 PyTorch Stable Diffusion 模型改为 OneFlow 模型,分别是将 import torch 改为 import oneflow as torch 和将 StableDiffusionPipeline 改为 OneFlowStableDiffusionPipeline:
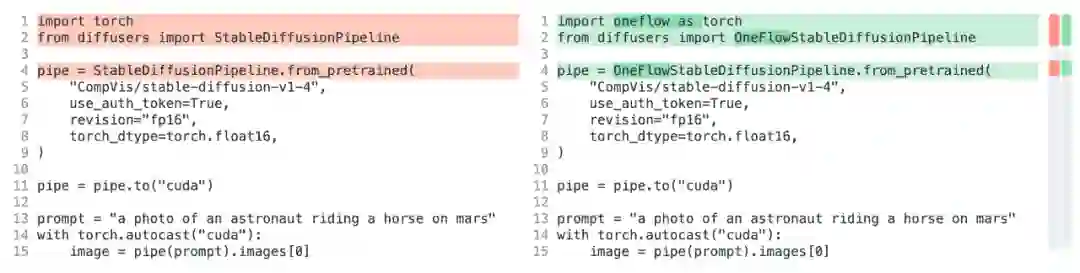
之所以能这么轻松迁移模型,是因为 OneFlow Stable Diffusion 有两个出色的特性:
OneFlowStableDiffusionPipeline.from_pretrained 能够直接使用 PyTorch 权重。
OneFlow 本身的 API 也是和 PyTorch 对齐的,因此 import oneflow as torch 之后,torch.autocast、torch.float16 等表达式完全不需要修改。
上述特性使得 OneFlow 兼容了 PyTorch 的生态,这不仅在 OneFlow 对 Stable Diffusion 的迁移中发挥了作用,也大大加速了 OneFlow 用户迁移其它许多模型,比如在和 torchvision 对标的 flowvision 中,许多模型只需通过在 torchvision 模型文件中加入 import oneflow as torch 即可得到。
此外,OneFlow 还提供全局 “mock torch” 功能,在命令行运行 eval $(oneflow-mock-torch) 就可以让接下来运行的所有 Python 脚本里的 import torch 都自动指向 oneflow。
使用 OneFlow 运行 Stable Diffusion
在 docker 中使用 OneFlow 运行 StableDiffusion 模型生成图片:
docker run --rm -it \--gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 \-v ${HF_HOME}:${HF_HOME} \-v ${PWD}:${PWD} \-w ${PWD} \-e HF_HOME=${HF_HOME} \-e HUGGING_FACE_HUB_TOKEN=${HUGGING_FACE_HUB_TOKEN} \oneflowinc/oneflow-sd:cu112 \python3 /demos/oneflow-t2i.py # --prompt "a photo of an astronaut riding a horse on mars"
更详尽的使用方法请参考:https://github.com/Oneflow-Inc/diffusers/wiki/How-to-Run-OneFlow-Stable-Diffusion
后续工作
后续 OneFlow 团队将积极推动 OneFlow 的 diffusers(https://github.com/Oneflow-Inc/diffusers.git) 和 transformers(https://github.com/Oneflow-Inc/transformers.git) 的 fork 仓库内容合并到 huggingface 上游的的对应仓库。这也是 OneFlow 首次以 transformers/diffusers 的后端的形式开发模型,欢迎各位开发者朋友在 GitHub 上反馈意见。
值得一提的是,在优化和加速 Stable Diffusion 模型的过程中使用了 OneFlow 自研编译器,不仅让 PyTorch 前端搭建的 Stable Diffusion 在 NVIDIA GPU 上跑得更快,而且也可以让这样的模型在国产 AI 芯片和 GPU 上跑得更快,这些将在之后的文章中揭秘技术细节。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com



