深度强化学习从入门到大师:简单介绍A3C (第五部分)

本文为 AI 研习社编译的技术博客,原标题 :
An intro to Advantage Actor Critic methods: let’s play Sonic the Hedgehog!
作者 | Thomas Simonini
翻译、校对 | 斯蒂芬•二狗子
审核 | 邓普斯•杰弗
整理 | 菠萝妹
原文链接:
https://medium.freecodecamp.org/an-intro-to-advantage-actor-critic-methods-lets-play-sonic-the-hedgehog-86d6240171d
注:本文的相关链接请点击文末【阅读原文】进行访问
深度强化学习从入门到大师:简单介绍A3C (第五部分)

从本系列课程开始,我们研究了两种不同的强化学习方法:
基于数值的方法(Q-learning,Deep Q-learning):该方法是学习一个值函数,该值函数将每组状态、动作映射到一个数值。多亏了这个方法, 可以找到了每个状态的最佳行动 - 具有最大Q值的行动。当行动个数有限时,该方法很有效。
基于策略函数的方法(策略梯度方法之REINFORCE 算法):我们不使用值函数,而直接优化策略。当动作空间是连续的或随机时,这很有效。该方法的主要问题是找到一个好的评分函数来计算策略的好坏程度。我们使用episode的总奖赏作为评分函数(每个Episode中获得的奖励之和)。
但这两种方法都有很大的缺点。这就是为什么今天我们将研究一种新型的强化学习方法,我们称之为“混合方法”: Actor Critic(AC)。我们将用到两个神经网络:
衡量所采取的行动的好坏的评价器(critic)(基于值函数)
控制智能体行为方式的行动者(actor)(基于策略)
掌握这种架构对于理解最先进的算法(如近端策略优化Proximal Policy Optimization,又名PPO)至关重要。PPO是基于Advantage Actor Critic(优势行动者评论家算法)。
本文中,你将通过Advantage Actor Critic(A2C)来实现一个可以学习如何玩刺猬索尼克的智能体!
寻找更好的学习模型
策略梯度存在的问题
策略梯度法有一个很大的问题是,当使用蒙特卡洛策略梯度方法时,会等到整个情景episode结束后计算奖励。据此可以得出结论,若结果回报值很高R(t),整个情景中所做的行动都被是指定为是有利的(行动),即使有些行动非常糟糕。
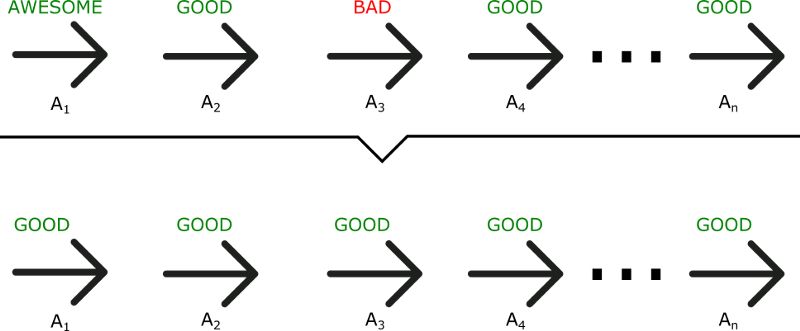
正如我们在这个例子中所看到的,尽管A3 是一个不好的行动(会造成负奖励),总回报(total reward)的重要评分使得所有被执行过的行动的策略参数被平均。
因此,学习模型要获得最优策略,就需要大量样本。因此导致训练过程耗时,因为这需要花费大量的时间来收敛loss函数。
那么,如果我们可以在每个时间步对参数进行更新,结果会有什么不同?
介绍Actor Critic (表演者-评论家)
表演者-评论家模型是一个更好的得分函数。我们不会像在蒙特卡洛这种传统强化学习方法那样,等到情景episode结束才更新参数,而是在每个步骤进行更新(即时序差分学习,TD学习)。
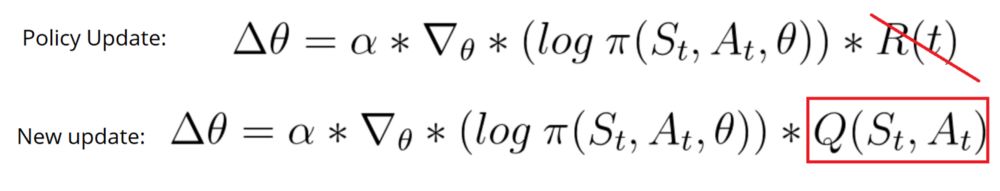
因为每个时间步都进行参数更新,所以不再使用总回报R(t)。我们还需要训练一个与值函数近似的评论家模型(记得,值函数是通过给定状态和动作计算的最大未来回报的期望值)。这个值函数被用来代替使用策略梯度时的奖励函数。
ctor Critic 是如何运行的
想一下,你和你的朋友一起玩视频游戏,你朋友一直回应你。你就是表演者,你朋友是评论家。
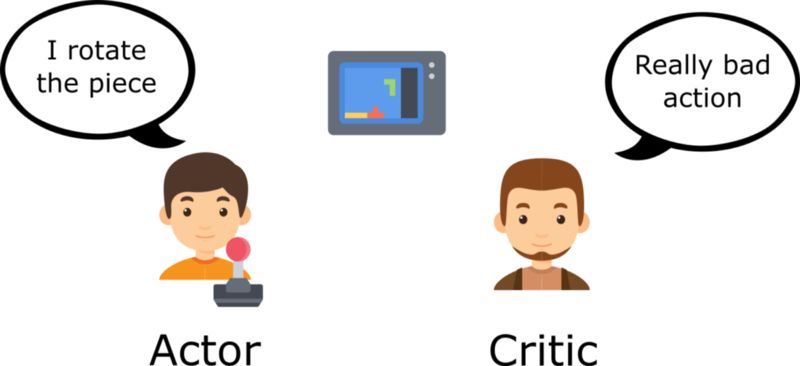
刚开始,你不会玩,所以你随机尝试一些行动。评论家(你朋友)将对你的行为的评价反馈给你。
通过在反馈中学习,你不断更新玩游戏的策略,并玩的越来越好了。
另一方面,你的朋友(评论家)也会更新他们提供反馈的方式,以便下次更好。
在我们看来,这个表演者-评论家的思想需要两个神经网络。我们给出两者表达式:
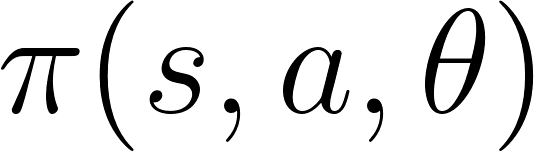
ACTOR:一个控制智能体行为的策略函数
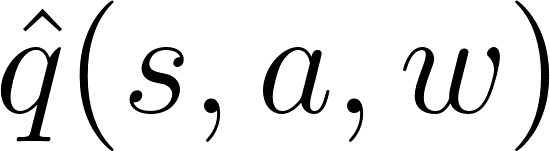
CRITIC:一个衡量这些行为好坏程度的值函数
两个模型同时运行。
因为我们有两个模型(Actor和Critic)需要被训练,所以需要分别优化两组权重(用于行动的𝜃和用于评论的w)

Actor Critic表演-评论过程
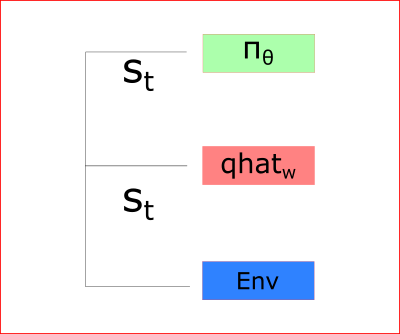
在每个时间步,我们从环境中获取当前状态(St),并将其作为输入传到Actor表演者和Critic评论家两模型中。
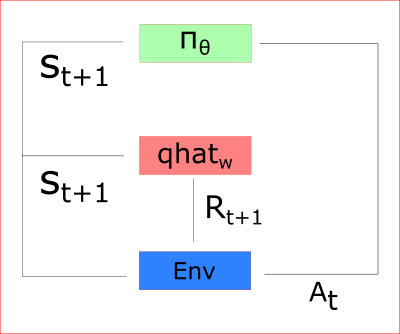
我们的策略获得状态,输出一行动(At),并再接收一个新状态(St+1)和奖励(Rt+1)。
多亏那样:
评论家模型计算当前状态下采用某行动的得分q
表演者模型使用这个q值更新自身的策略权重
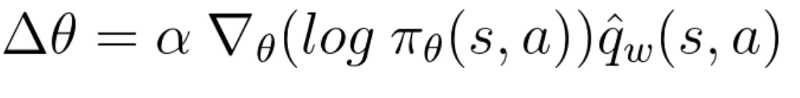
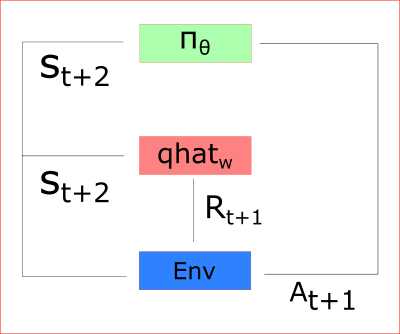
因为这一步的参数更新,使得在新状态St+1到来时,Actor可以获取到对应的行动At+1,随后,Critic更新他的参数值。
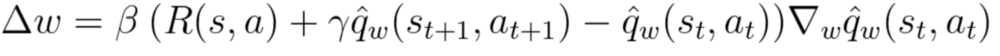
A2C 和 A3C
介绍平稳地学习的优势函数Advantage function
在 深度Q学习的改进 这篇文章中我们了解,基于值函数的方法具有大的训练波动。
这里我们讨论了优势函数的使用,就是为了缓解这个问题。
优势函数定义如下:

该函数给出相比在当前状态下采用平均行动(动作值函数)的优势值。换句话说,如果我采取这个行动,该函数计算我这个行动得到的奖励。
(注:优势函数的目的是,使用动作值函数减去了对应状态拥有的基准值,使之变为动作带来的增益,从而因而降低因状态基准值的变化引起的方差)
如果 A(s,a) > 0: 梯度将朝梯度的那个方向更进一步。
如果 A(s,a) < 0:(我们的行为比该状态的平均值更差),梯度将朝相反的方向进一步。
实现这个优势函数的需要两个值函数-- Q(s,a) 和 V(s) 。幸运的是,我们可以使用 差分时间序列误差TD Error 作为该优势函数的(无偏)估计。

(Q(s,a)是动作值函数,V(s)也就是在状态s下所有动作值函数动作概率的期望)
两种不同的策略:异步或同步
我们有两种不同的策略来实现Actor Critic智能体:
A2C(又名优势演员评论家)
A3C(又名异步优势演员评论家)
因此,我们使用与A2C,而不是A3C。如果您想看到完整的A3C实现,请查看 Arthur Juliani的优秀文章 A3C 和 Doom 实现。
在A3C中,我们不使用经验回放,因为这需要大量内存。不同的是,我们可以并行的在多个环境实例上异步执行不同的智能体。(可多核CPU跑)每个work(网络模型的副本)将异步地更新全局网络。
另一方面,A2C与A3C的唯一区别是A2C是同步更新全局网络。我们等到所有works完成训练后,计算他们的梯度的均值,以更新全局网络参数。
选择A2C还是A3C?
这篇很棒的文章解释了A3C存在的问题 。由于A3C的异步特性,一些works(智能体的副本)使用较旧版本的参数。因此,这样几个work聚合地更新参数不是最好的。
这就是为什么A2C在更新全局参数之前等待每个actor模型完成他们网络的各自部分的经验训练的原因。然后,我们重新开始一个使用各自部分经验的新训练,并且所有并行模型具有相同的新参数。
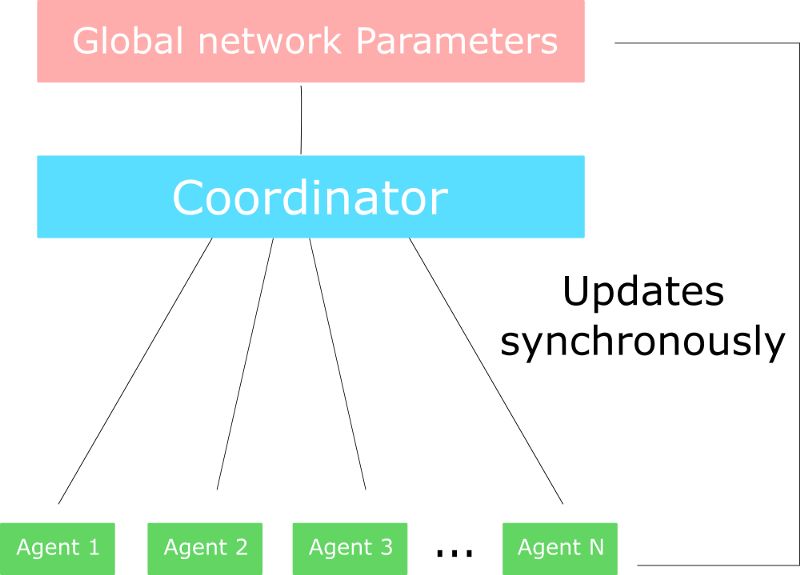
此架构思想受益于这篇文章
因此,训练过程将使得模型间更密切联系,并且训练更快速度。
实现一个玩刺猬索尼克的A2C智能体
实际情况中的A2C
实际上,正如 Reddit帖子中 所解释的那样 , 因为A2C的同步性,所有我们不需要 A2C 的不同版本(不同的work)。
A2C中的每个work都具有相同的权重集,与A3C不同的是,A2C同时更新所有work(的参数)。
实际上,我们创建了多种版本的环境(比如八个),然后将它们并行地执行。
该过程如下:
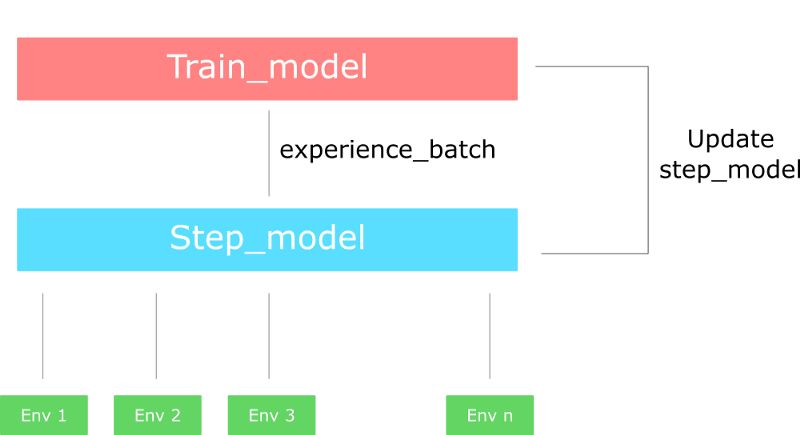
使用“multiprocessing”库创建一个具有n个环境的向量
创建一个对象“runner”,用来并行处理不同的环境
使用两种网络模型:
step_model: 从环境中产生经验样本
train_model: 训练经验样本
当 runner 迈出一步时(单步模型),将分别从n个环境中的每个环境执行一个步骤,并输出了一批经验样本。
然后使用 train_model 和在这一批经验样本上计算(所有work)梯度。
最后,使用计算得出的新权重更新单步模型。
请记住,这样一次计算所有梯度和每个 work 分别收集数据,并计算每个工人的梯度,然后求全局平均值是一样的。为什么?因为求导数的和(梯度的总和)与求和的导数相同。但求和的导数是使用GPU更好的方式(节省训练时间)。
刺猬索尼克的A2C
目前,我们了解了A2C一般的运行方式,我们可以开发这个玩索尼克的A2C智能体了!这个视频展示了我们的智能体训练10分钟(左)和训练10小时(右)的行为对比。
A2C Agent playing Sonic the Hedgehog 🦔 (Left 1 update // Right 260)
实现代码在GitHub上能找到(here), 代码的细节在notebook中给出了解释。我还给你一个在GPU上训练了10+小时的模型。
这个代码实现比以前的代码要复杂好多。我们要开始复现最先进的算法,因此需要代码的更高的效率。这也是为什么,我们将整个code分为不同对对象和文件来实现代码。
Understand A2C implementation playing Sonic the Hedgehog
就像这样!你刚刚创建了一个学习玩刺猬索尼克的智能体。 好棒!我们可以看到,在10小时的训练中,智能体还是不理解“looping”,所以我们需要使用更稳定的架构:PPO。
花点时间来想想我们从第一节课到现在取得的所有成就:从简单的文本游戏(OpenAI taxi-v2)到像毁灭战士、索尼克这些复杂的游戏,我们采用越来越复杂的模型结构。这真是极好的!
下次,我们会来了解近端策略梯度,这个结构赢得了 OpenAI 迁移学习竞赛 我们将训练智能体玩索尼克2和索尼克3的全部关卡。
不要忘了,亲自写写代码实现每个部分。试着添加epochs,改模型架构,调整学习率,等等。尝试是最好的学习方式,玩的愉快~
想要继续查看该篇文章相关链接和参考文献?
长按链接点击打开或点击底部【阅读原文】:
https://ai.yanxishe.com/page/TextTranslation/1407
【点击查看本系列文章】
深度强化学习从入门到大师:通过Q学习进行强化学习(第二部分)
深度强化学习从入门到大师:以Doom为例一文带你读懂深度Q学习(第三部分 - 上)
深度强化学习从入门到大师:进一步了解深度Q学习(第三部分 - 下)
深度强化学习从入门到大师:以 Cartpole 和 Doom 为例介绍策略梯度 (第四部分)
AI研习社每日更新精彩内容,观看更多精彩内容:
7分钟了解Tensorflow.js
在Keras中理解和编程ResNet
初学者怎样使用Keras进行迁移学习
如果你想学数据科学,这 7 类资源千万不能错过
等你来译:
深度学习目标检测算法综述
一文教你如何用PyTorch构建 Faster RCNN
高级DQNs:利用深度强化学习玩吃豆人游戏
用于深度强化学习的结构化控制网络 (ICML 论文讲解)
【AI求职百题斩 - 每日一题】
赶紧来看看今天的题目吧!

想知道正确答案?
点击今日推文【第4条】或 在公众号回复“0114挑战”即可答题获取!



