CVPR 2020 | 详解Kaggle X光肺炎检测比赛亚军方案
点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转载自:AI算法修炼营

论文:https://arxiv.org/abs/2005.13899
代码:https://github.com/tatigabru/kaggle-rsna
本文为Kaggle X光肺炎检测比赛第二名方案。在这项工作中,使用了基于Se-ResNext101为主干网络的RetineNet SSD网络模型, 同时使用了数据增广和多任务学习的技巧来实现肺炎区域的检测。
肺炎约占全世界5岁以下儿童死亡原因总数的16%,是世界领先的幼儿死亡原因。仅在美国,每年约有100万成年人因肺炎在医院接受治疗,并有5万人死于这种疾病。近期新型冠状病毒病2019(COVID-19)是一种危及生命的疾病,在2020年有成千上万人因此丧失生命。
肺炎的检测通常是由训练有素的专家通过检查胸部X光片(CXR)进行的。它通常表现为CXR上不透明性增加的区域或区域,通过临床病史,生命体征和实验室由于肺中存在其他状况,例如体液超负荷,出血,体液丢失,肺癌,放疗后或手术改变,因此对CXR肺炎的诊断非常复杂。如果可以的话,比较患者在不同时间点的CXR以及与临床症状和病史的相关性有助于诊断。
为了提高诊断服务的效率和准确性,近十年来广泛使用了用于肺炎检测的计算机辅助诊断系统。在许多医学图像分析任务中,包括检测,分类和分割,使用深度学习方法的性能优于传统的机器学习方法。
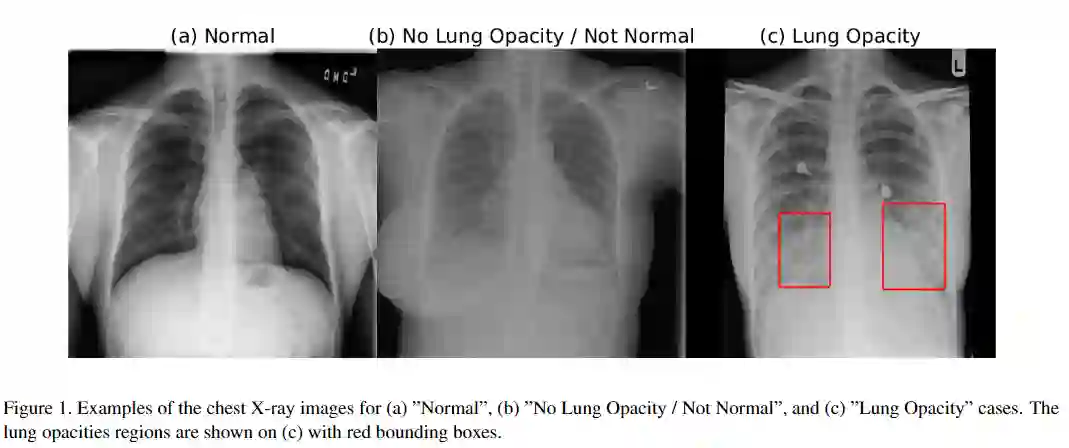
由美国国立卫生研究院临床中心公开提供了带有标签的胸部X射线图像和患者元数据的数据集。该数据库包含来自26684例独特患者的正视X射线图像。每幅图像都用相关放射学报告中的三个不同类别中的一个进行标记:“正常”,“无肺不透明/不正常”,“肺不透明”。
通常,肺部充满空气,当某人患有肺炎时,肺中的空气被其他物质所替代,即肺不透明症是指优先减弱X射线束的区域,因此在CXR上比应有的区域更不透明,这表明该区域的肺组织可能不健康。
“正常”类别包含健康患者的数据,未发现任何病理(包括但不限于肺炎,气胸,肺不张等)。“
“肺不透明”类别的图像显示肺部出现白色模糊云,并伴有肺炎,同时肺部混浊区域标有边界框。如果检测到一个以上的肺炎区域,则任何给定的患者都可以有多个框。肺部混浊有多种,有些与肺炎有关,有些与肺炎无关。
“无肺不透明/非正常”类别说明了在CXR肺不透明区域可见但未诊断出肺炎的患者的数据。图1显示了所有三个类别的CXR实例,这些类别标记有不健康患者的边界框。

评价指标
使用不同的交并比(IoU)阈值下的平均准确精度(mAP)来评估模型。阈值的范围从0.4到0.75,步长为0.05:(0.4、0.45、0.5、0.55、0.6、0.65、0.7、0.75)。
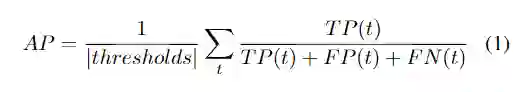
通常,机器学习竞赛中的解决方案大多数是基于大模型和多样化模型的融合、 test-time aug-mentation和pseudo labelling等方法实现的,但这些方法在现实应用中并不总是可行。
在测试时,我们通常希望最大程度地减少内存占用和推理时间。本文中提出了一个基于单个模型的解决方案,该模型集成了多个checkpoints。该模型使用了在ImageNet 上经过预训练的SE-ResNext101作为主干网络,整体网络框架使用的是 RetinaNet SSD 。
RetinaNet的框架整体是ResNet+FPN+FCN,它使用ResNet作为backbone来提取图像特征,然后从中抽取5层特征层来构建特征金字塔网络(FPN: feature pyramid network),最后接两个独立的全卷积网络(FCN: full convolution network)分别得到物体的类别信息和位置框信息。
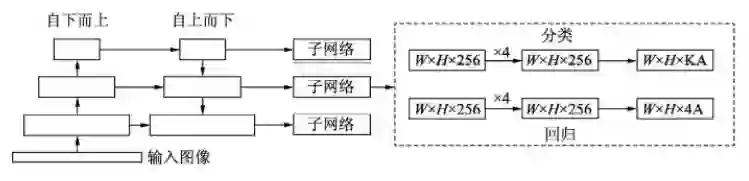
对于RetinaNet的网络结构,有以下5个细节:
(1)在Backbone部分,RetinaNet利用ResNet与FPN构建了一个多尺度特征的特征金字塔。
(2)RetinaNet使用了类似于Anchor的预选框,在每一个金字塔层,使用了9个大小不同的预选框。
(3)分类子网络:分类子网络为每一个预选框预测其类别,因此其输出特征大小为KA×W×H, A默认为9, K代表类别数。中间使用全卷积网络与ReLU激活函数,最后利用Sigmoid函数输出预测值。
(4)回归子网络:回归子网络与分类子网络平行,预测每一个预选框的偏移量,最终输出特征大小为4A×W×W。与当前主流工作不同的是,两个子网络没有权重的共享。
(5)Focal Loss:与OHEM等方法不同,Focal Loss在训练时作用到所有的预选框上。对于两个超参数,通常来讲,当γ增大时,α应当适当减小。实验中γ取2、α取0.25时效果最好。
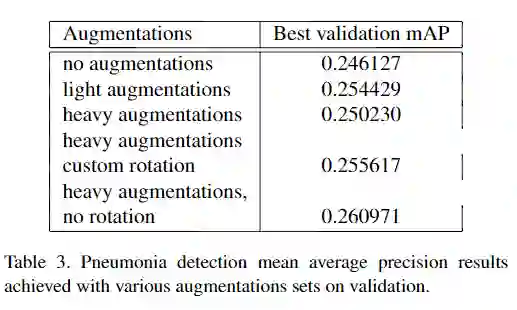
基础模型:采用RetinaNet,并做了以下几点改进:
1、带空目标框box的图像被添加到模型中,并有助于损失函数的计算和优化(原始的Pytorch RetinaNet实现忽略了没有目标框box的图像)。
2、小anchor的额外输出已添加到CNN网络当中,以便处理较小的目标框。
3、使用以下类别之一(“无肺不透明/不正常”,“正常”,“肺不透明”)对全局图像进行分类的额外输出添加到模型中。因此,总损失由该全局分类输出与回归损失和单个框分类损失合并而成。
4、在全局分类输出中添加了dropout ,以减少过度拟合。除了额外的正则化,它还有助于在同一epoch中实现最佳的分类和回归结果。
训练参数:
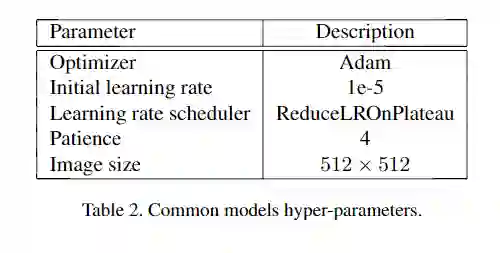
主干网络选取:
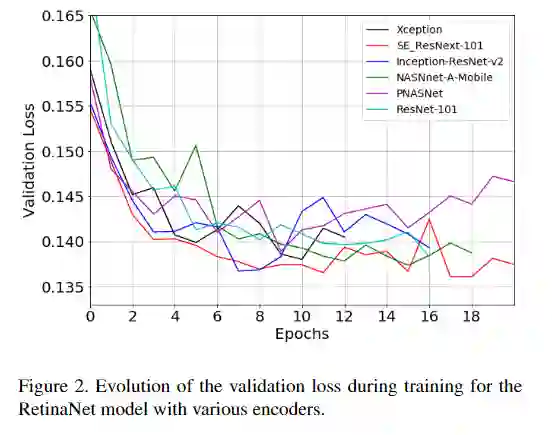
为了实现合理的快速实验和规范化,同时考虑了在精度与复杂度/参数数量和因此之间取得良好折衷的架构。图中显示了在RetinaNet SSD中使用的各种编码器训练期间的验证损失。SE-ResNext体系结构取得了该数据集的最佳性能,并且在准确性和复杂性之间取得了良好的折衷。
图像数据预处理与图像增强
原始图像按比例缩放为512×512像素分辨率,由于原始的挑战数据集不是很大,因此采用了以下图像增强来减少过拟合:轻微旋转(最多6度);移位,缩放,剪切;水平翻转;对于某些图像,模糊处理,添加噪声,进行伽玛值随机变化;有限提高亮度/伽玛增强量等。
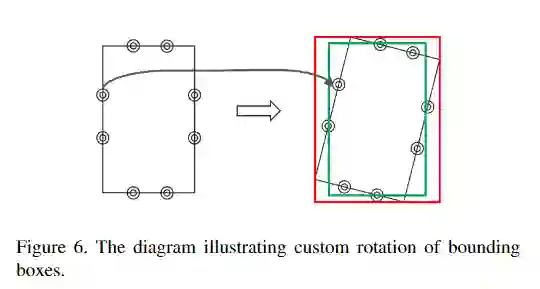
针对训练集和测试集标记方法不同的后处理方法
在训练和测试所提供数据集的标记过程方面有所不同。训练集由唯一的专家标记,而测试台由三名独立的放射线医师标记,他们的标记的交集用于标签真值。这样可以产生较小的标记边界框大小,尤其是在复杂情况下。
可以使用4倍的输出和/或多个检查点的预测来模拟此过程。使用20个百分位数代替锚点大小的平均输出,然后根据单个模型的80个百分位数和20个百分位数之间的差异按比例减少更多(以1.6的比例作为超参数进行了优化)。
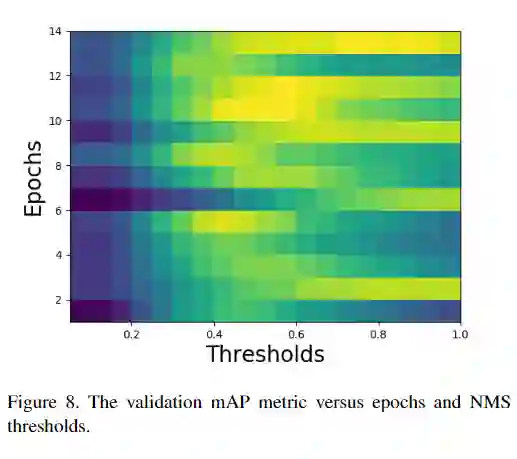
由于标记过程不同,训练和测试集的最大抑制(NMS)算法也有所不同。NMS阈值对mAP指标值产生了巨大影响。图8显示了针对不同训练时期和NMS阈值的验证mAP指标变化。验证集的最佳NMS阈值在各个时期之间存在显着差异,取决于模型,其最佳范围在0.45和1之间。
另一种方法是将测试集的预测的目标框box大小重新缩放为原始大小的87.5%,以反映测试和训练集标签过程之间的差异。选择87.5%的系数以使尺寸与以前的方法大致匹配。
结果优化
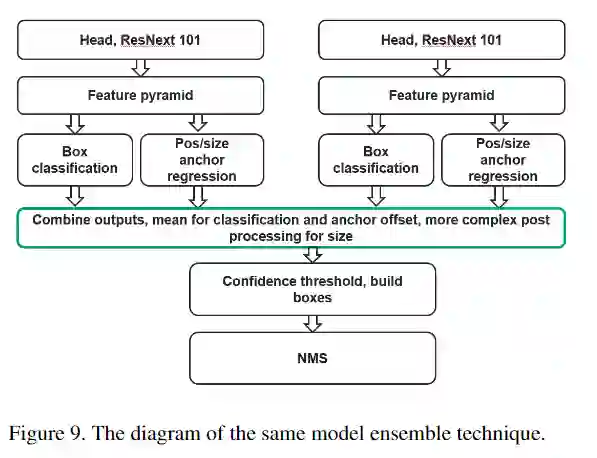
检测模型的结果可能在各个epoch之间发生显着变化,并且很大程度上取决于阈值。在应用NMS算法和优化阈值之前,将相同模型的4折交叉验证的输出合并。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

投稿、合作也欢迎联系:simiter@126.com

长按关注计算机视觉life
有用,点个赞