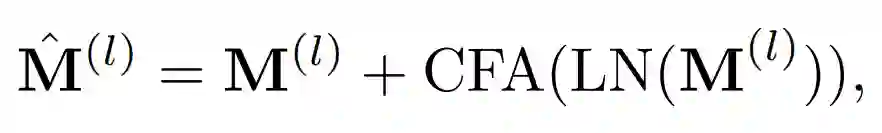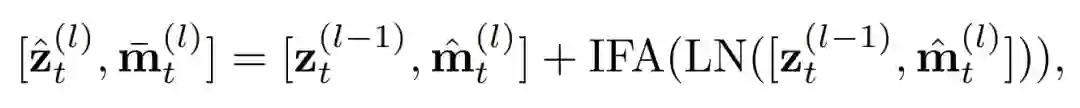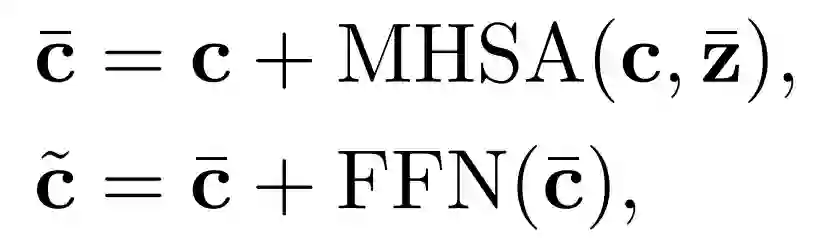对于这项工作,研究者们希望可以启发人们探索视频和文本的结合,并为视频大模型的设计和研究铺平道路。
如何将现有的图像 - 文本多模态大模型(例如 OpenAI CLIP)用于视频内容理解,是一个非常实用且具有前景的研究课题。它不仅可以充分挖掘图像大模型的潜力,还可以为视频大模型的设计和研究铺平道路。
在视频内容理解领域,为节省计算 / 数据开销,视频模型通常 「微调」图像预训练模型。而在图像领域, 最近流行的语言 - 图像预训练模型展现了卓越的泛化性,尤其是零样本迁移能力。那么人们不禁要问:能否有一种视频模型兼顾「微调」 的高效和 「语言 - 图像预训练」的全能?答案是可以!
为解决此问题,
来自微软的研究者提出了将语言 - 图像预训练模型拓展到通用视频识别的方法,在建模时序信息的同时,利用类别标签文本中的语义信息
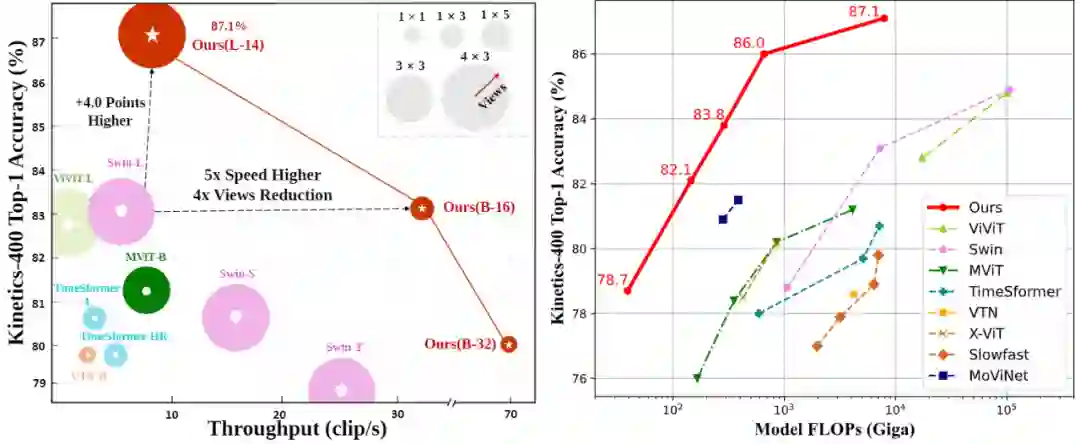
。该方法在 Kinetics-400/600 数据集上分别取得了 87.7% 和 88.3% 的 Top-1 分类准确率,
计算量仅为ViViT 和 Video Swin的十几分之一
,并且在 few-shot 和 zero-shot 评测上大幅领先其它方法。代码已开源。
![]()
-
论文链接:https://arxiv.org/pdf/2208.02816.pdf
-
代码链接:http://aka.ms/X-CLIP
![]()
图1:throughput 和 FLOPs 对比。
-
无需海量视频 - 文本数据
:直接将预训练的语言 - 图像模型在下游视频数据集微调,而非从零使用视频 - 文本预训练;
-
利用标签中的语义信息
:在视频识别任务中,抛弃了传统离散标签,充分利用每个类别标签中的语义信息并提升了性能;
-
方法简单、高效且通用
:无缝衔接至不同的语言 - 图像模型,可用于多种数据分布场景,如全样本、少样本和零样本。
至于视频分类的效果,与其他方法相比,X-CLIP 可用于零样本识别,即用户自定义候选标签,实现对视频内容更精准的描述:
![]()
![]()
![]()
最近,语言 - 图像预训练模型(Language-image pretrained models)在计算机视觉领域引起了极大关注。它使用更广泛的文本信息作为监督,打破了传统模型学习固定视觉概念的范式。受益于此,其展示出了强大的迁移能力和泛化能力,在全样本、少样本和零样本分类上取得了卓越的成绩。
现在是一个短视频爆发的时代,现实世界中丰富的概念更是难以被一个固定的封闭集所定义。于是,研究人员和从业人员也希望有一个泛化能力强大的视频模型,能在不同的数据分布场景和不同的概念环境中表现优异。这样的模型会助力于现实世界的许多应用,比如自动驾驶、视频标签、安防监控等。同样,由于视频的获取成本通常更加高昂,少样本和零样本的识别能力也被期待。
但是,如果直接模仿语言 - 图像预训练,使用视频 - 文本预训练会带来以下两个问题:
-
数据困境
:需要数以亿计的视频 - 文本数据,但是大量的数据是难以获得的;
-
计算困境
:视频的训练通常需要数倍于图像的计算资源,这些资源消耗通常无法承受。
有鉴于此,研究者考虑探索如何将预训练的语言 - 图像模型中的知识迁移到视频领域,而非从零预训练一个语言 - 视频模型。与图像相比,视频增加了时间的维度;与传统视频识别框架相比,研究者引入了文本信息。
-
如何在语言 - 图像预训练模型中建模视频的时序信息
?
-
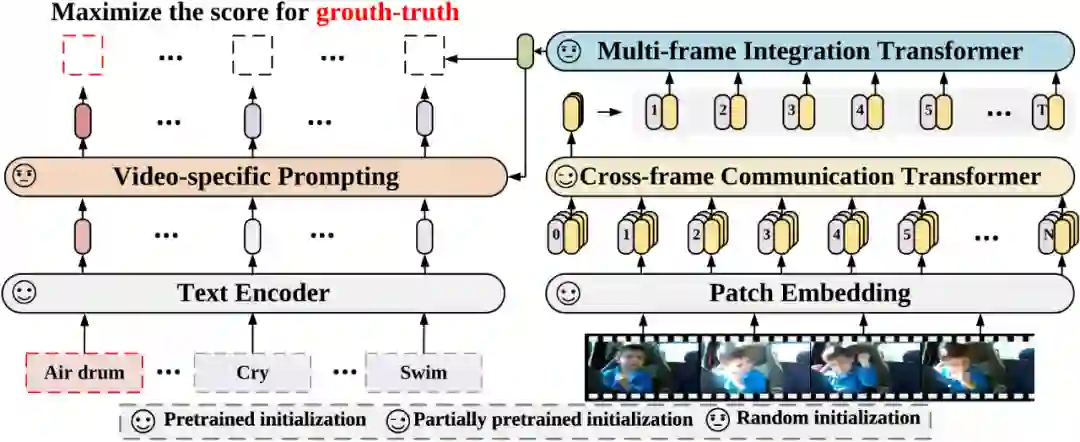
针对第一个问题,研究者提出了 Cross-frame Communication Transformer 和 Multi-frame Integration Transformer 模块,在预训练模型中引入时序信息;对于第二个问题,研究者提出了 Video-specific Prompting 机制,用于产生视频自适应的提示信息,充分地利用了类别标签中的文本信息。方法整体框架图如下图 5 所示。
![]()
建模时序信息:利用 message token 帧间通讯
![]()
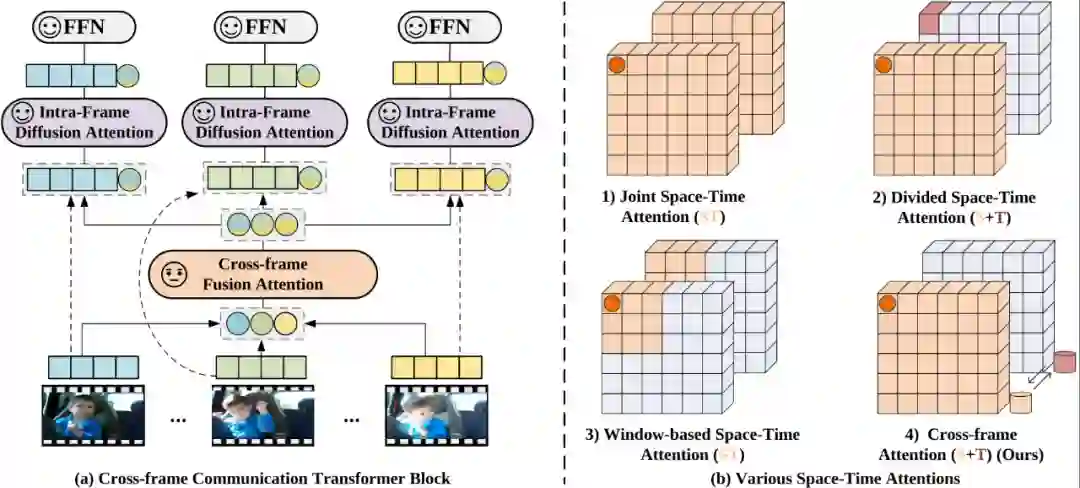
图 6(a) CCT Block (b)不同时空 attention 对比。
本文中,研究者提出了一种
简单高效的视频编码器
。该编码器由两部分组成,即 Cross-frame Communication Transformer(CCT)和 Multi-frame Integration Transformer(MIT)。为了避免联合时空建模的高计算量,整体上,CCT 采用各帧独立编码的计算方式。
具体地,对每一帧编码时,动态地生成各自的 message token(如图 6(a)中彩色的圆形部分),携带所在帧的信息,再通过 Cross-frame Fusion Attention 交换不同帧的 message token 携带的信息,弥补了时序信息的缺失。具体地,如图 6(a)所示,在 CCT 的每一个 block 中,我们在 cls token 上施加线性变化得到 message token,每帧的 message token 通过 Cross-frame Fusion Attention(CFA)交换信息,
![]()
随后,每一帧的 message token 再回归到所属帧。通过 Intra-frame Diffusion Attention,每一帧内的 spatial tokens 在建模空间信息的同时,吸收了来自 message token 的全局时序信息,
![]()
最后,每一帧的 spatial tokens 再经过 FFN 进一步编码信息。为了进一步提升性能,研究者在 CCT 产生的每帧的特征上,额外使用一层 Multi-frame Integration Transformer(MIT)(如图 5)聚合每一帧的信息,产生视频最终的表达。
Cross-frame Fusion Attention 和 MIT 是额外添加的模块并使用随机初始化。Intra-Frame Diffusion Attention 和 FFN 对应于预训练 Vision Transformer 中的 self-attention 和 FFN 部分。值得注意的是,因为帧数(message tokens 的数量)远小于 spatial tokens 的数量,所以 Cross-frame Fusion Attention 和一层 MIT 的计算量远小于 Intra-frame Diffusion Attention, 这样便以较小的计算代价建模了全局的时序信息。
针对第二个问题,
提示学习(Prompt learning)主张为下游任务设计一种模板,使用该模板可以帮助预训练模型回忆起自己预训练学到的知识
。比如, CLIP[4] 手动构造了 80 个模板,CoOp[5]主张构造可学习的模板。
研究者认为,人类在理解一张图片或视频时,自然地会从视觉内容中寻找有判别性的线索。例如有额外的提示信息「在水中」,那么「游泳」和「跑步」会变得更容易区分。但是,获取这样的提示信息是困难的,原因有二:
-
数据中通常只有类别标签,即「跑步」、「游泳」、「拳击」等名称,缺乏必要的上下文描述;
-
同一个类别下的视频共享相同的标签信息,但它们的关键视觉线索可能是不同。
为了缓解上述问题,研究者提出了从视觉表征中学习具有判别性的线索。具体地,他们提出了视频自适应的提示模块,根据视频内容的上下文,自适应地为每个类别生成合适的提示信息。每个视频的自适应提示模块由一个 cross-attention 和一个 FFN 组成。令文本特征当作 query,视频内容的编码当作 key 和 value,允许每个类别的文本从视频的上下文中提取有用的提示信息作为自己的补充。
![]()
最后,使用学习到的提示信息来丰富原本文本信息的表示,使得其具有更强的判别性。
研究者
在全样本(Fully-supervised)、少样本(few-shot)和零样本(zero-shot)上验证了方法的性能
。
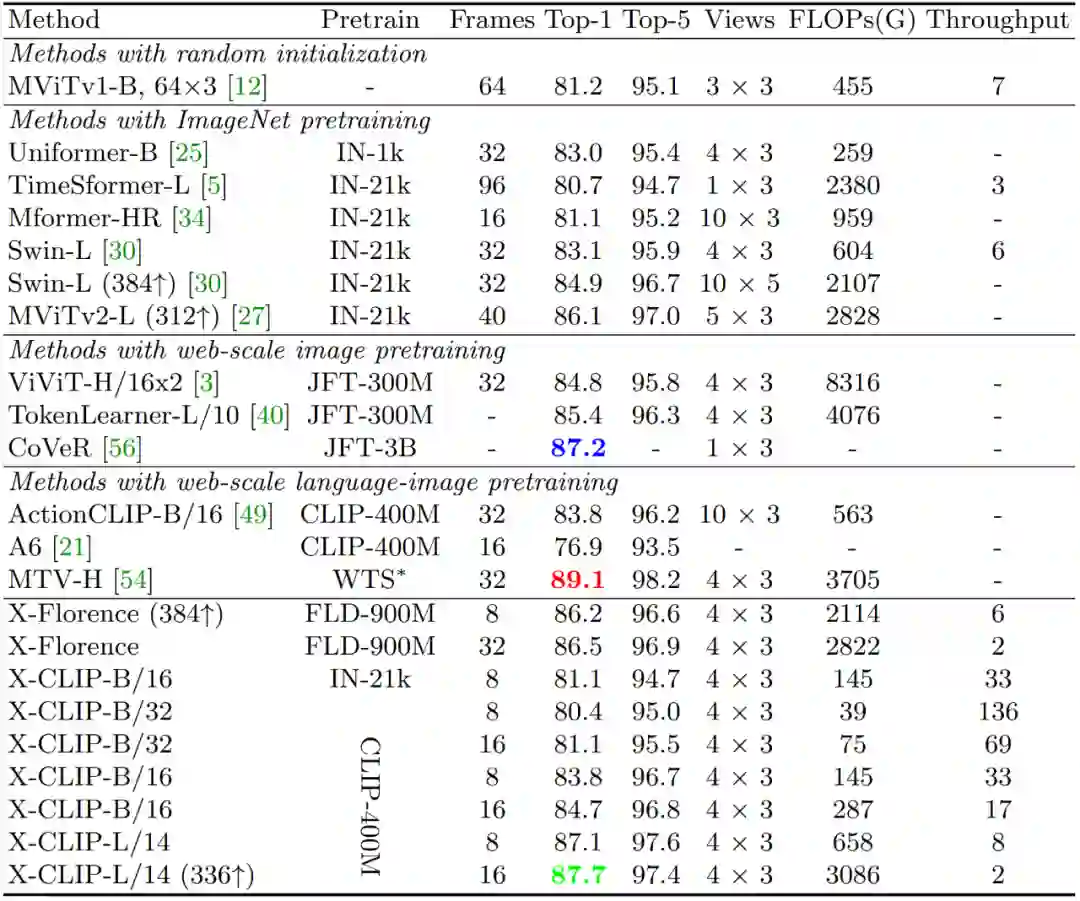
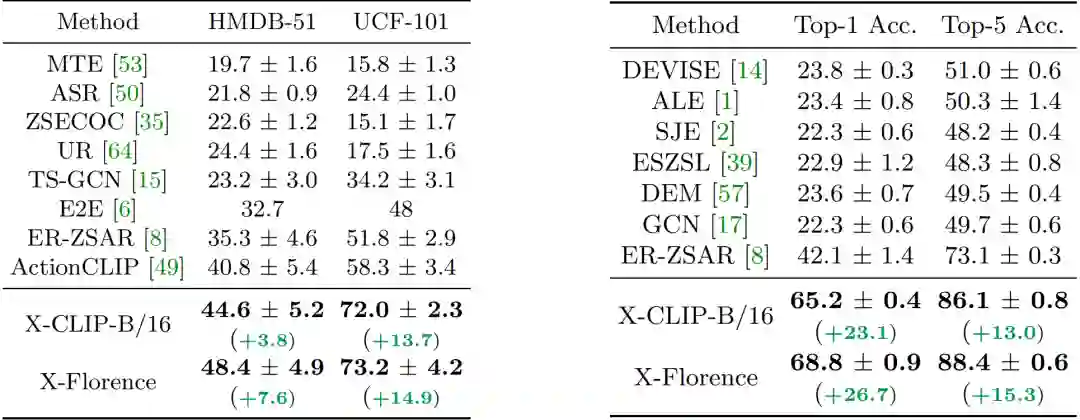
在 Kinetics-400 上的实验如下表 1 所示,可以看出
X-CLIP 在 FLOPs 更小的情况下领先于其它方法,这得益于提出的视频编码器的高效性
。当和其它使用互联网(Web)规模数据预训练的模型比较时,本文的方法依然有性能优势,这归功于该方法充分挖掘和利用了预训练语言 - 图像模型中的表达能力。
![]()
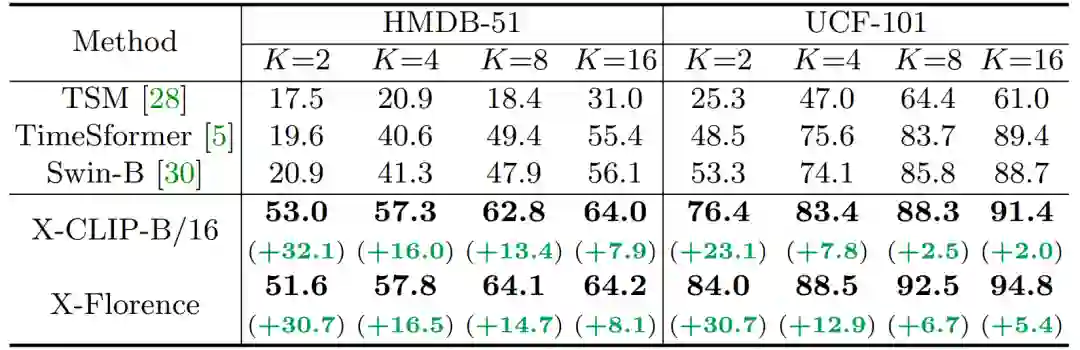
下表 2 展示了
少样本情况下的性能,和经典的使用离散标签监督的方法相比,使用文本信息可以大幅提升性能
。研究者在消融实验中证明了性能增益更多来自于文本的使用,而非更强的预训练模型。
![]()
下表 3 展示了
在零样本情况下,提出的方法依然有效
。这种显著的改进可以归因于所提出的视频 - 文本学习框架,该框架利用大规模的视觉 - 文本预训练和视频自适应的提示学习。
![]()
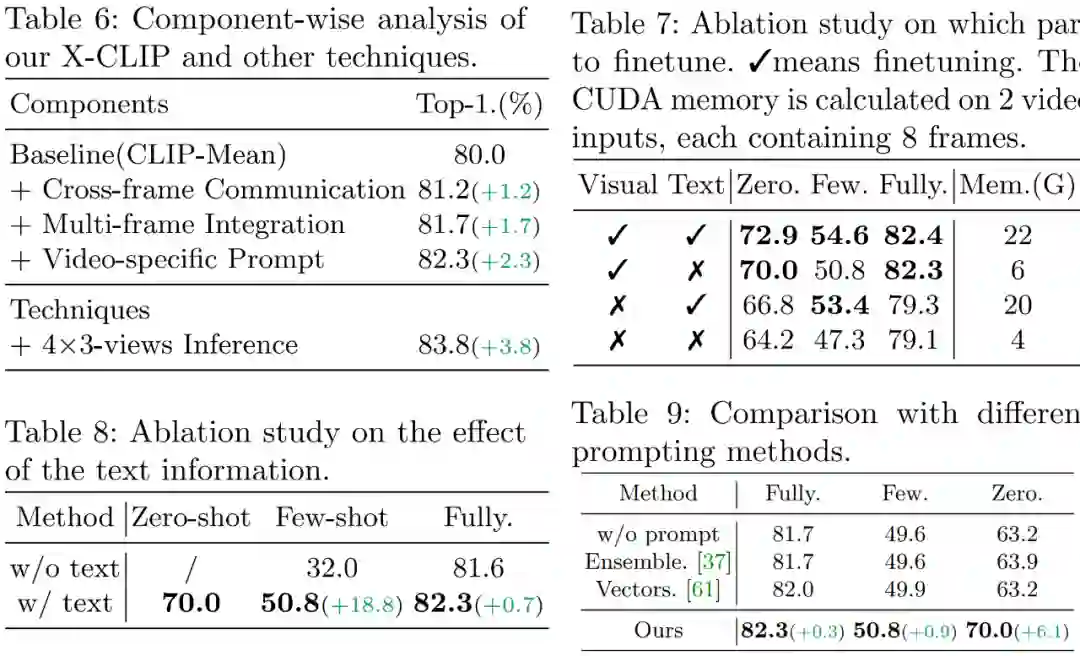
研究者在消融实验中展示了每个模块的作用,分析了文本信息的必要性,探索了不同数据分布下应该训练哪个分支,比较了不同的 prompts 方法。
![]()
据了解,这项工作入选 ECCV 2022 Oral 并非一帆风顺。虽然 pre-rebuttal 的评分不错,得到了两个 Accepts 和一个 Borderline,评审人的评价也很高。并且,研究者本来希望通过 rebuttal 让中立的评审人改分,争取 Oral。遗憾的是,接收列表出来的时候却发现这篇文章没有中。
研究者没有就此放弃,而是选择在与合著者商量后,向程序主席发邮件询问。结果皆大欢喜,程序主席回信并表示是由于脚本错误这篇文章被遗漏了。
于是,这篇文章最终被接收为 ECCV 2022 Oral。
[1] Arnab, A., Dehghani, M., Heigold, G., Sun, C., Luˇ ci´ c, M., Schmid, C.: Vivit: A video vision transformer. In: ICCV. 2021
[2] Bertasius, G., Wang, H., Torresani, L.: Is space-time attention all you need for video understanding? In: ICML, 2021
[3] Liu, Z., Ning, J., Cao, Y., Wei, Y., Zhang, Z., Lin, S., Hu, H.: Video swin transformer. In CVPR, 2022.
[4] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In ICML, 2021
[5] Zhou, K., Yang, J., Loy, C.C., Liu, Z.: Learning to prompt for vision-language models. arXiv preprint arXiv:2109.01134 (2021)
博世中国-自动驾驶多任务网络学习挑战赛
挑战赛围绕多任务学习命题,基于博世开源数据集,构建一个多任务学习神经网络模型,同时完成车道线检测和目标检测两个任务。
-
-
-
获奖选手受邀参加2022世界人工智能大会WAIC · AI开发者日举行的颁奖典礼
-
报名即可参与抽奖,博世吸尘器、面包机等超多礼物等你拿
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com