设计和实现一款轻量级的爬虫框架
说起爬虫,大家能够想起 Python 里赫赫有名的 Scrapy 框架, 在本文中我们参考这个设计思想使用 Java 语言来实现一款自己的爬虫框(lun)架(zi)。 我们从起点一步一步分析爬虫框架的诞生过程。
我把这个爬虫框架的源码放在 github(https://github.com/biezhi/elves) 上,里面有几个例子可以运行。

关于爬虫的一切
下面我们来介绍什么是爬虫?以及爬虫框架的设计和遇到的问题。
什么是爬虫?
“爬虫”不是一只生活在泥土里的小虫子,网络爬虫(web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览网络上内容的机器人。 爬虫访问网站的过程会消耗目标系统资源,很多网站不允许被爬虫抓取(这就是你遇到过的 robots.txt 文件, 这个文件可以要求机器人只对网站的一部分进行索引,或完全不作处理)。 因此在访问大量页面时,爬虫需要考虑到规划、负载,还需要讲“礼貌”(大兄弟,慢点)。
互联网上的页面极多,即使是最大的爬虫系统也无法做出完整的索引。因此在公元2000年之前的万维网出现初期,搜索引擎经常找不到多少相关结果。 现在的搜索引擎在这方面已经进步很多,能够即刻给出高质量结果。
网络爬虫会遇到的问题
既然有人想抓取,就会有人想防御。网络爬虫在运行的过程中会遇到一些阻碍,在业内称之为 反爬虫策略 我们来列出一些常见的。
访问频率限制
Header 头信息校验
动态页面生成
IP 地址限制
Cookie 限制(或称为登录限制)
验证码限制
等等…
这些是传统的反爬虫手段,当然未来也会更加先进,技术的革新永远会带动多个行业的发展,毕竟 AI 的时代已经到来, 爬虫和反爬虫的斗争一直持续进行。
爬虫框架要考虑什么
设计我们的框架
我们要设计一款爬虫框架,是基于 Scrapy 的设计思路来完成的,先来看看在没有爬虫框架的时候我们是如何抓取页面信息的。 一个常见的例子是使用 HttpClient 包或者 Jsoup 来处理,对于一个简单的小爬虫而言这足够了。
下面来演示一段没有爬虫框架的时候抓取页面的代码,这是我在网络上搜索的
public class Reptile {
public static void main(String[] args) {
//传入你所要爬取的页面地址
String url1 = "";
//创建输入流用于读取流
InputStream is = null;
//包装流,加快读取速度
BufferedReader br = null;
//用来保存读取页面的数据.
StringBuffer html = new StringBuffer();
//创建临时字符串用于保存每一次读的一行数据,然后html调用append方法写入temp;
String temp = "";
try {
//获取URL;
URL url2 = new URL(url1);
//打开流,准备开始读取数据;
is = url2.openStream();
//将流包装成字符流,调用br.readLine()可以提高读取效率,每次读取一行;
br= new BufferedReader(new InputStreamReader(is));
//读取数据,调用br.readLine()方法每次读取一行数据,并赋值给temp,如果没数据则值==null,跳出循环;
while ((temp = br.readLine()) != null) {
//将temp的值追加给html,这里注意的时String跟StringBuffere的区别前者不是可变的后者是可变的;
html.append(temp);
}
//接下来是关闭流,防止资源的浪费;
if(is != null) {
is.close();
is = null;
}
//通过Jsoup解析页面,生成一个document对象;
Document doc = Jsoup.parse(html.toString());
//通过class的名字得到(即XX),一个数组对象Elements里面有我们想要的数据,至于这个div的值呢你打开浏览器按下F12就知道了;
Elements elements = doc.getElementsByClass("XX");
for (Element element : elements) {
//打印出每一个节点的信息;你可以选择性的保留你想要的数据,一般都是获取个固定的索引;
System.out.println(element.text());
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
从如此丰富的注释中我感受到了作者的耐心,我们来分析一下这个爬虫在干什么?
1. 输入一个要爬取的URL地址
2. 通过 JDK 原生 API 发送网络请求获取页面信息(这里没有使用 HttpClient)
3. 使用 Jsoup 解析 DOM
4. 处理自己需要的数据
5. 将它们输出在控制台
大概就是这样的步骤,代码也非常简洁,我们设计框架的目的是将这些流程统一化,把通用的功能进行抽象,减少重复工作。 还有一些没考虑到的因素添加进去,那么设计爬虫框架要有哪些组成呢?
1. URL管理
2. 网页下载器
3. 爬虫调度器
4. 网页解析器
5. 数据处理器
分别来解释一下每个组成的作用是什么。
URL管理器
爬虫框架要处理很多的URL,我们需要设计一个队列存储所有要处理的URL,这种先进先出的数据结构非常符合这个需求。 将所有要下载的URL存储在待处理队列中,每次下载会取出一个,队列中就会少一个。我们知道有些URL的下载会有反爬虫策略, 所以针对这些请求需要做一些特殊的设置,进而可以对URL进行封装抽出 Request。
网页下载器
在前面的简单例子中可以看出,如果没有网页下载器,用户就要编写网络请求的处理代码,这无疑对每个URL都是相同的动作。 所以在框架设计中我们直接加入它就好了,至于使用什么库来进行下载都是可以的,你可以用 httpclient 也可以用 okhttp, 在本文中我们使用一个超轻量级的网络请求库 oh-my-request (没错,就是在下搞的)。 优秀的框架设计会将这个下载组件置为可替换,提供默认的即可。
爬虫调度器
调度器和我们在开发 web 应用中的控制器是一个类似的概念,它用于在下载器、解析器之间做流转处理。 解析器可以解析到更多的URL发送给调度器,调度器再次的传输给下载器,这样就会让各个组件有条不紊的进行工作。
网页解析器
我们知道当一个页面下载完成后就是一段 HTML 的 DOM 字符串表示,但还需要提取出真正需要的数据, 以前的做法是通过 String 的 API 或者正则表达式的方式在 DOM 中搜寻,这样是很麻烦的,框架 应该提供一种合理、常用、方便的方式来帮助用户完成提取数据这件事儿。常用的手段是通过 xpath 或者 css 选择器从 DOM 中进行提取,而且学习这项技能在几乎所有的爬虫框架中都是适用的。
数据处理器
普通的爬虫程序中是把 网页解析器 和 数据处理器 合在一起的,解析到数据后马上处理。 在一个标准化的爬虫程序中,他们应该是各司其职的,我们先通过解析器将需要的数据解析出来,可能是封装成对象。 然后传递给数据处理器,处理器接收到数据后可能是存储到数据库,也可能通过接口发送给老王。
基本特性
上面说了这么多,我们设计的爬虫框架有以下几个特性,没有做到大而全,可以称得上轻量迷你挺好用。
易于定制:很多站点的下载频率、浏览器要求是不同的,爬虫框架需要提供此处扩展配置
多线程下载:当CPU核数多的时候多线程下载可以更快完成任务
支持 XPath 和 CSS 选择器解析
架构图
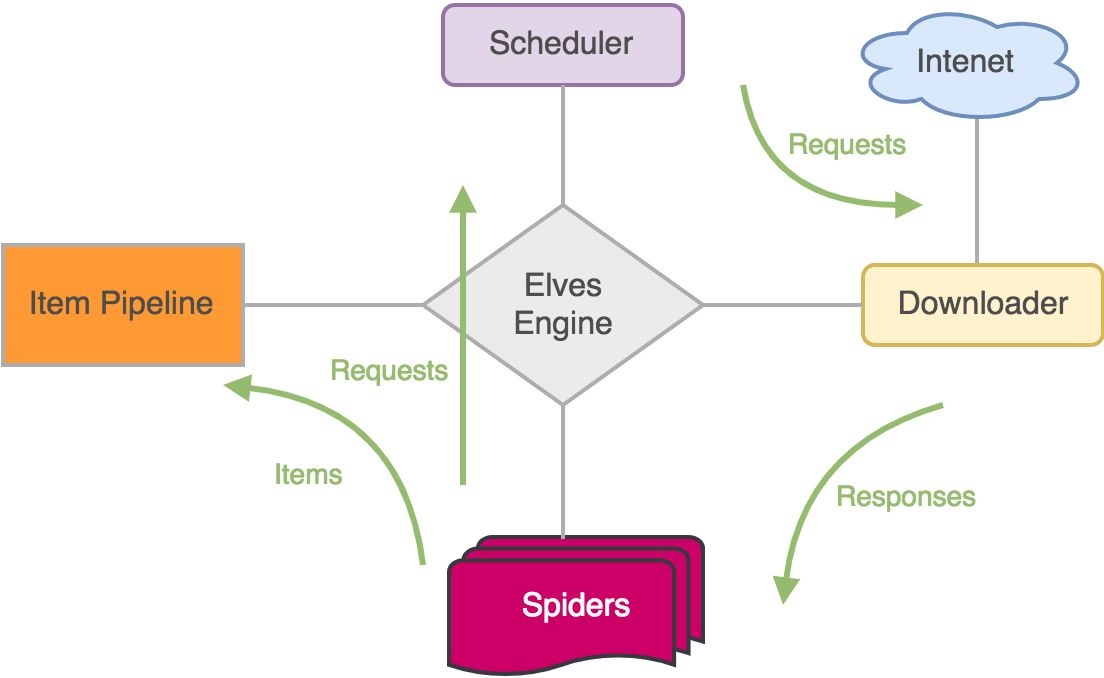
整个流程和 Scrapy 是一致的,但简化了一些操作
引擎(Engine): 用来处理整个系统的数据流处理, 触发事务(框架核心)
调度器(Scheduler): 用来接受引擎发过来的请求, 压入队列中, 并在引擎再次请求的时候返回. 可以想像成一个URL(抓取网页的网址或者说是链接)的优先队列, 由它来决定下一个要抓取的网址是什么, 同时去除重复的网址
下载器(Downloader): 用于下载网页内容, 并将网页内容返回给调度器
爬虫(Spiders): 爬虫是主要干活的, 用于从特定的网页中提取自己需要的信息, 即所谓的实体(Item)。 用户也可以从中提取出链接,让框架继续抓取下一个页面
项目管道(Pipeline): 负责处理爬虫从网页中抽取的实体,主要的功能是持久化实体、验证实体的有效性、清除不需要的信息。 当页面被爬虫解析后,将被发送到项目管道,并经过几个特定的次序处理数据。
执行流程图
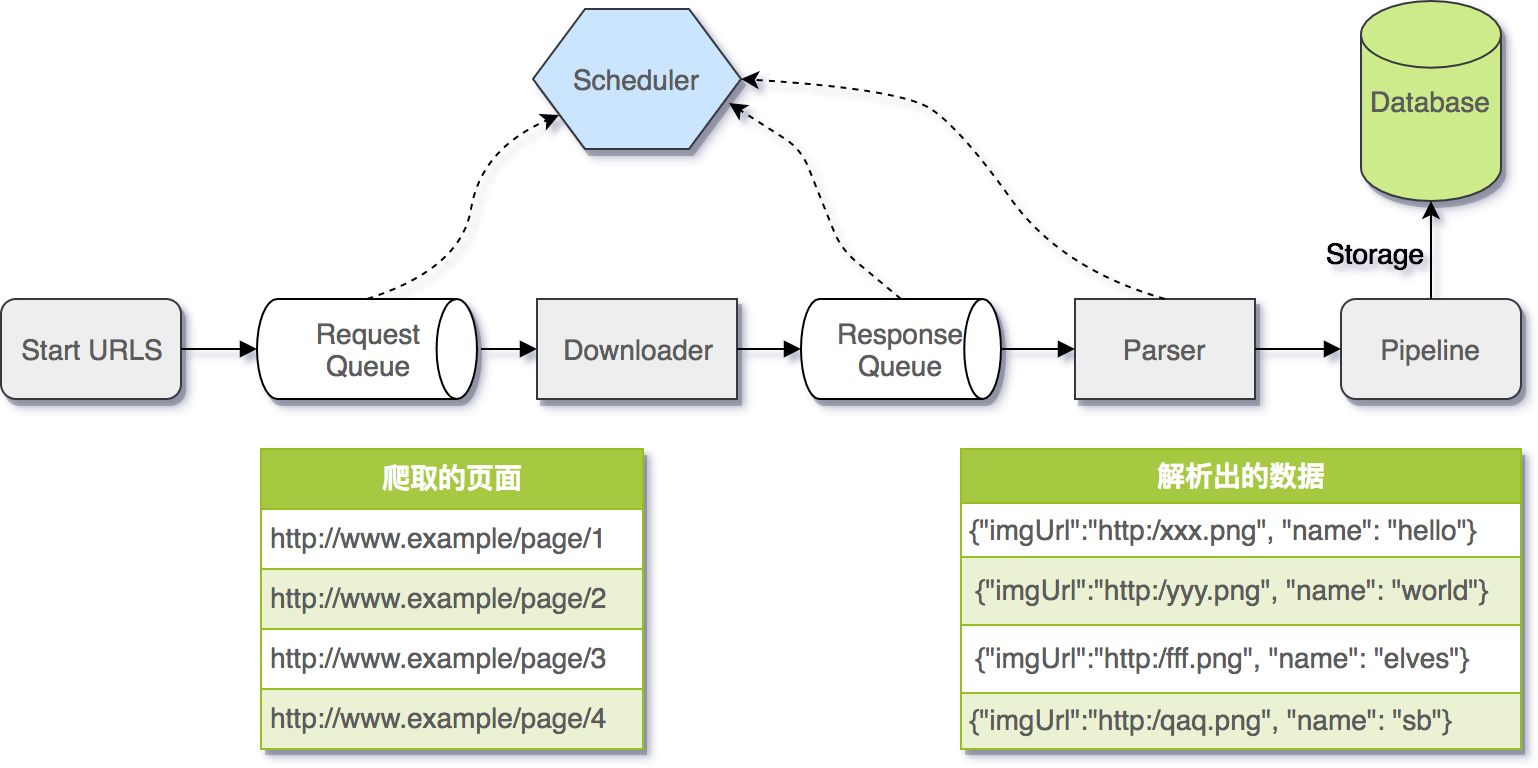
1. 首先,引擎从调度器中取出一个链接(URL)用于接下来的抓取
2. 引擎把URL封装成一个请求(Request)传给下载器,下载器把资源下载下来,并封装成应答包(Response)
3. 然后,爬虫解析Response
4. 若是解析出实体(Item),则交给实体管道进行进一步的处理。
5. 若是解析出的是链接(URL),则把URL交给Scheduler等待抓取
项目结构
该项目使用 Maven3、Java8 进行构建,代码结构如下:
.
└── elves
├── Elves.java
├── ElvesEngine.java
├── config
├── download
├── event
├── pipeline
├── request
├── response
├── scheduler
├── spider
└── utils
编码要点
前面设计思路明白之后,编程不过是顺手之作,至于写的如何考量的是程序员对编程语言的使用熟练度以及架构上的思考, 优秀的代码是经验和优化而来的,下面我们来看几个框架中的代码示例。
使用观察者模式的思想来实现基于事件驱动的功能
public enum ElvesEvent {
GLOBAL_STARTED,
SPIDER_STARTED
}
public class EventManager {
private static final Map<ElvesEvent, List<Consumer<Config>>> elvesEventConsumerMap = new HashMap<>();
// 注册事件
public static void registerEvent(ElvesEvent elvesEvent, Consumer<Config> consumer) {
List<Consumer<Config>> consumers = elvesEventConsumerMap.get(elvesEvent);
if (null == consumers) {
consumers = new ArrayList<>();
}
consumers.add(consumer);
elvesEventConsumerMap.put(elvesEvent, consumers);
}
// 执行事件
public static void fireEvent(ElvesEvent elvesEvent, Config config) {
Optional.ofNullable(elvesEventConsumerMap.get(elvesEvent)).ifPresent(consumers -> consumers.forEach(consumer -> consumer.accept(config)));
}
}
这段代码中使用一个 Map 来存储所有事件,提供两个方法:注册一个事件、执行某个事件。
阻塞队列存储请求响应
public class Scheduler {
private BlockingQueue<Request> pending = new LinkedBlockingQueue<>();
private BlockingQueue<Response> result = new LinkedBlockingQueue<>();
public void addRequest(Request request) {
try {
this.pending.put(request);
} catch (InterruptedException e) {
log.error("向调度器添加 Request 出错", e);
}
}
public void addResponse(Response response) {
try {
this.result.put(response);
} catch (InterruptedException e) {
log.error("向调度器添加 Response 出错", e);
}
}
public boolean hasRequest() {
return pending.size() > 0;
}
public Request nextRequest() {
try {
return pending.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Request 出错", e);
return null;
}
}
public boolean hasResponse() {
return result.size() > 0;
}
public Response nextResponse() {
try {
return result.take();
} catch (InterruptedException e) {
log.error("从调度器获取 Response 出错", e);
return null;
}
}
public void addRequests(List<Request> requests) {
requests.forEach(this::addRequest);
}
}
pending 存储等待处理的URL请求,result 存储下载成功的响应,调度器负责请求和响应的获取和添加流转。
举个栗子
设计好我们的爬虫框架后来试一下吧,这个例子我们来爬取豆瓣电影的标题。豆瓣电影中有很多分类,我们可以选择几个作为开始抓取的 URL。
public class DoubanSpider extends Spider {
public DoubanSpider(String name) {
super(name);
this.startUrls(
"https://movie.douban.com/tag/爱情",
"https://movie.douban.com/tag/喜剧",
"https://movie.douban.com/tag/动画",
"https://movie.douban.com/tag/动作",
"https://movie.douban.com/tag/史诗",
"https://movie.douban.com/tag/犯罪");
}
@Override
public void onStart(Config config) {
this.addPipeline((Pipeline<List<String>>) (item, request) -> log.info("保存到文件: {}", item));
}
public Result parse(Response response) {
Result<List<String>> result = new Result<>();
Elements elements = response.body().css("#content table .pl2 a");
List<String> titles = elements.stream().map(Element::text).collect(Collectors.toList());
result.setItem(titles);
// 获取下一页 URL
Elements nextEl = response.body().css("#content > div > div.article > div.paginator > span.next > a");
if (null != nextEl && nextEl.size() > 0) {
String nextPageUrl = nextEl.get(0).attr("href");
Request nextReq = this.makeRequest(nextPageUrl, this::parse);
result.addRequest(nextReq);
}
return result;
}
}
public static void main(String[] args) {
DoubanSpider doubanSpider = new DoubanSpider("豆瓣电影");
Elves.me(doubanSpider, Config.me()).start();
}
这段代码中在 onStart 方法是爬虫启动时的一个事件,会在启动该爬虫的时候执行,在这里我们设置了启动要抓取的URL列表。 然后添加了一个数据处理的 Pipeline,在这里处理管道中只进行了输出,你也可以存储。
在 parse 方法中做了两件事,首先解析当前抓取到的所有电影标题,将标题数据收集为 List 传递给 Pipeline; 其次根据当前页面继续抓取下一页,将下一页请求传递给调度器,由调度器转发给下载器。这里我们使用一个 Result 对象接收。
总结
设计一款爬虫框架的基本要点在文中已经阐述,要做的更好还有很多细节需要打磨,比如分布式、容错恢复、动态页面抓取等问题。 欢迎在 elves(https://github.com/biezhi/elves) 中提交你的意见。
参考文献
常见的反爬虫和应对方法:https://zhuanlan.zhihu.com/p/20520370
反爬虫思路与解决办法:http://bigsec.com/bigsec-news/anan-16825-Antireptile-zonghe
网络爬虫:https://zh.wikipedia.org/wiki/%E7%B6%B2%E8%B7%AF%E7%88%AC%E8%9F%B2
出处:https://blog.biezhi.me/2018/01/design-and-implement-a-crawler-framework.html
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢。
架构文摘
ID:ArchDigest
互联网应用架构丨架构技术丨大型网站丨大数据丨机器学习

更多精彩文章,请点击下方:阅读原文