混合云的多活架构指南

在之前的《如何正确选择多云架构?》一文中介绍了混合云(广义的多云)的诸多架构以及各自的优势,本篇会重点来介绍下混合云下的多活架构。
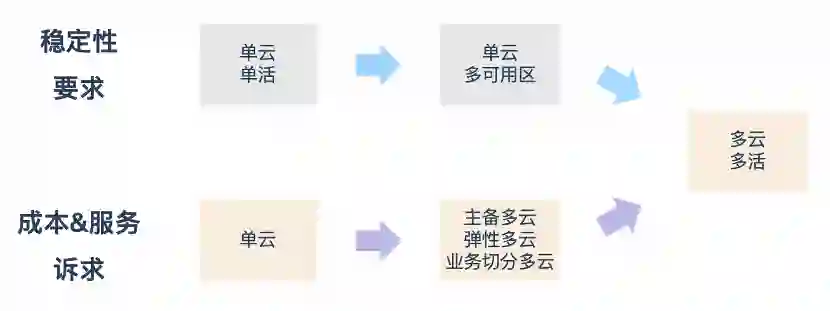
企业选择混合云的技术诉求中,主要因素还是稳定性和成本 & 服务,而对这两点的极致追求就是多活架构。
稳定性
业务探索阶段追求效率,技术上一般会选择单云单活的架构。随着业务的逐步发展,单活的架构无法满足业务稳定性的要求,技术人员开始进行服务多可用区的部署。这个也是行业内比较主流的做法。
随着云厂商的技术建设,稳定性越来越高,且同 region 的多可用区方案进一步降低了企业集中式故障的概率。但云厂商仍存在中心式服务,如 region 的网络汇聚、统一的结算系统等。
对于用户使用时间窗口特别集中的业务,对稳定性的要求更高。比如在线素养课就是在有限时间内老师和学生完成知识传授,如果在这段时间内云服务出现故障,学生的学业受到影响,学生和老师需要重新匹配时间才能完成学习计划。健康码、打车软件这些使用集中在早晚高峰的场景也是同理。对于 SLA 要求更高的业务,选择多云多活是必然的趋势。
成本 & 服务
企业上云后能享受到弹性、标准的云计算服务。但随着互联网红利不断消退,公司希望实现成本效益最大化,引入更多的供应商也是必选的手段之一。新的供应商,可以用来做数据灾备,或者用于峰值时的弹性计算,也或者按照不同业务进行切分。
但是,更彻底的方案还是不同云各自进行服务等量部署,做到真正的多活,随时可以做到流量和容量的调度。
多活架构的优势很明显,但背后面临的挑战也是巨大的。下面从稳定性、成本、效率几方面来推演下。
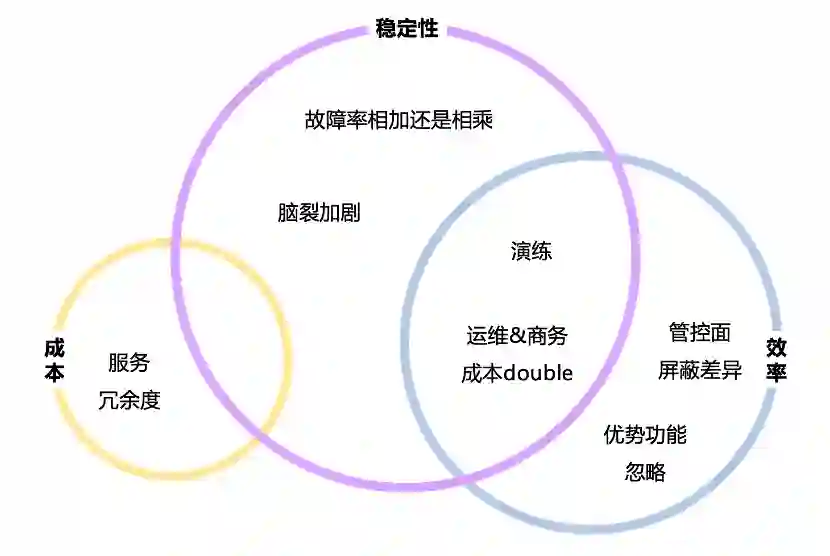
稳定性
多活架构是用来解决稳定性问题的,但若不能做到多云各自完整的闭环,彼此之间还有千丝万缕的调用依赖,故障率反而会增加。
假设企业使用两家云厂商,各自出现中心式严重故障的概率为 n 和 m,不论是网络还是容器还是计费等系统。假定这个值为 0.05%,则一年因云供应商导致的故障时间为 262.8 分钟。多活多云架构下理论的故障率为 n * m,千万分之几的故障率。考虑到多云之间的切换时效,故障时间可控制在十几甚至几分钟内。
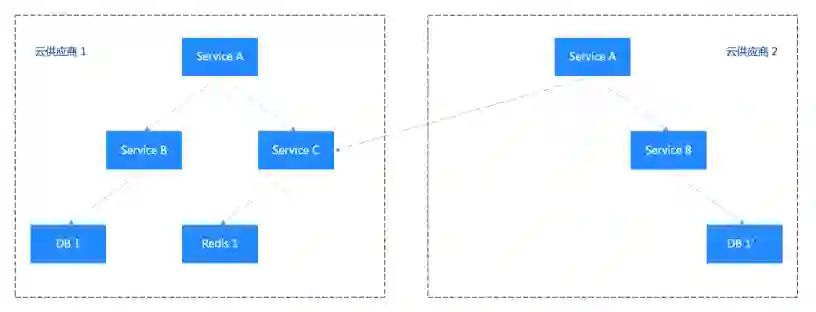
核心业务的调用链路一般是较复杂的树形,由根节点模块逐步发散。若其中存在一支调用链路,Service A 调用 Service B 和 Service C。其中 Service A、Service B 均为双云部署,Service C 仅部署在云厂商 1。那么当云厂商 1 出现严重故障时,核心业务受影响,无法提供服务。当云厂商 2 故障时,核心业务可以正常运行。这时的故障率为 max(n,m),取决于短板的云供应商。
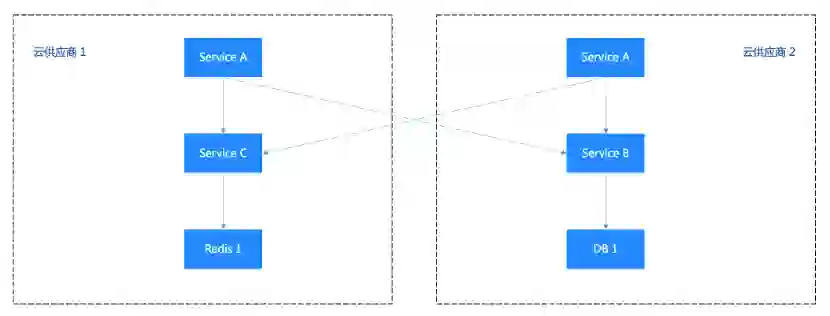
再极端一点,Service A 部署了双云,Service B 部署在云厂商 2、Service 1 部署在云厂商 1。那么不论哪个云出现故障,核心业务都受影响。此种部署架构下的故障率为 n + m,提升到 0.1%,被大大提高。
上面描述的场景并不是危言耸听,而是真正的客观现实。当模块较少时,如几十、几百的时候,通过研发自治加运维的 double check,在付出持续成本的情况尚可能避免这种异构的部署。可是一旦业务规模增加,模块数量达到上千后就不再是人工可以简单 check 的。各方向的研发和 SRE 负责人已经很难熟悉和管控每个模块的完整调用关系及部署情况。
除了部署异构导致的故障率加剧外,脑裂加剧也是一大隐患。多家云厂商中数据存储一般采用主从的方式进行同步,master 所在的主云故障后,需要将另一边云的数据存储提主。但是主云并不是完整挂掉,运维人员无法从控制台登陆,无法将 master 降为 slave。但用户南北流量或者定时任务还在持续请求,主云仍有可能还在处理写入流量。这时候从云的切主,就会导致不可避免的脑裂。脑裂无法简单的进行修复,需要业务研发 case by case 的进行修复,代价巨大。
成本
多云本质上是来解决成本问题的,但两边云稳定性做的不好,业务不得不加大冗余。极端情况下,两家供应商各自 100% 的容量,但常态下只承担 50% 的流量,带来巨大的成本浪费。
效率
效率包含研发效率和运维效率,效率的降低又会反作用于稳定性。
如果做不到多云的对等部署,不得不通过持续演练的方式来应对墒增,保证多云架构的有效性。一旦松懈了,很有可能导致花大精力做的架构升级,但在真正的单云故障面前不起任何作用。另外,在两次演练之间的窗口内,架构能否很好的应对单云故障也是存疑的。
每家云厂商提供的 IaaS、PaaS 能力看上去差异不大:计算无外乎是物理机、裸金属、虚拟机、serverless,网络无外乎是 EIP、LB、NAT、VPC 等实体。PaaS 是各种持久化、内存型存储存储、大数据离线、实时计算产品,但深入到产品特性后就会发现差异很大,管控面凹凸不齐。
多云管控面要作为胶水层,对上游抹平这些差异。这个对齐不仅仅是 API 的统一,也会有逻辑的封装。比如,一家云厂商的某项资源管控比较宽松,仅用一个 API 即可实现功能,但另一家因为产品策略的收紧,需要结合多个产品才能实现类似功能。运维平台就需要将这些包成事务,对外提供统一的能力。
管控面通过付出一定成本还是可以收敛的,但对于各家的优势功能,主要集中 PaaS 往往无法抹平。如特殊的数据存储方案、大数据实时方案,这时候就要去找寻其他的替代方案。
讲了这么多,该如何设计多云多活的方案。作业帮在线业务坚定地选择多活多云的策略,只有这样才能带来理想的稳定性和成本收益。
生活在云原生的时代,我们是幸运的。K8S 统一的北向接口,极大地抹平了多云部署的差异,让应用的交付和运行变的统一。
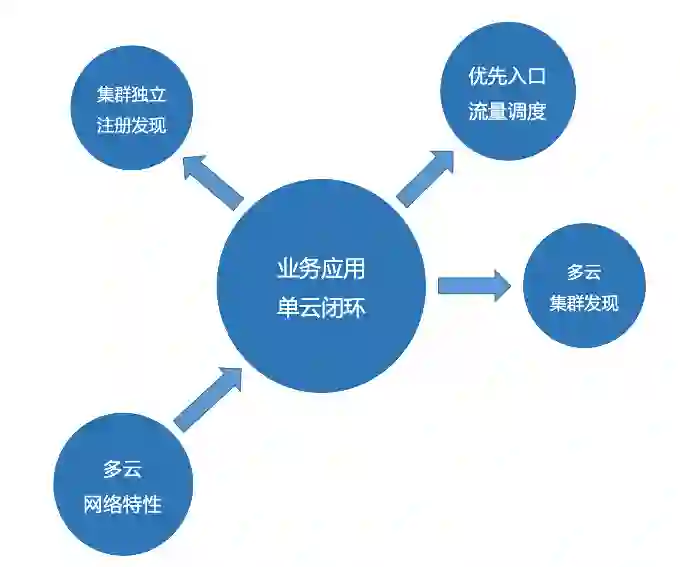
在架构拓扑方面,多云间的网络是介于单云多可用区和中心 - 边缘之间的一种状态,内网有一定可靠性,但并不能完全依赖。
基于此,应用应尽可能地减少多云间的网络通信。除了数据存储的同步和写主外,常态的应用间调用应该闭环在单云内部。所以并不需要做一套纳管各云应用的服务注册发现机制,仅需要单云内部独立注册发现即可。
当然不可否认,在某些场景下跨云调用还是有需求的。比如新扩一家云时,各业务节奏没法做到完整的步调一致,一定会有模块先部署,而它没有同步部署的依赖模块就需要路由回原集群。但这个也只需要集群间发现即可,不需要集群乘以服务把问题的复杂度提高。多云部署了全量服务,南北向流量就可以优先通过 DNS 进行调度。
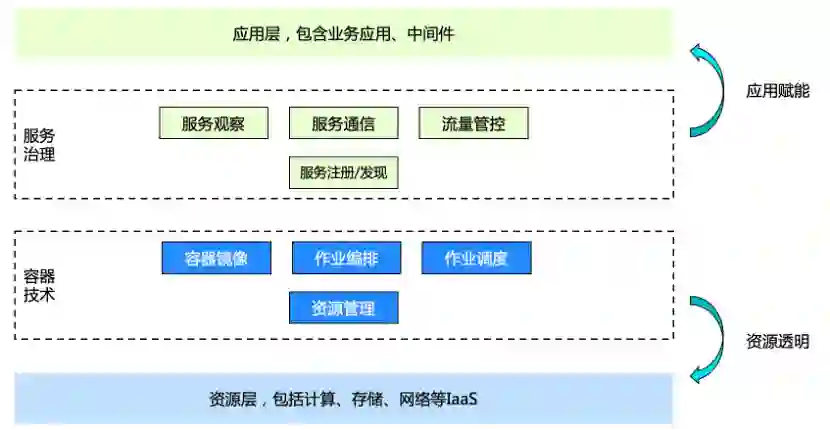
企业技术架构从大的层次来说,会分成两层:底下的一层是资源层,包括计算、存储、网络等 IaaS 资源;应用这个层面,有底下各种各样的 PaaS 组件,包括数据存储、消息队列、安全、大数据的等等,然后再往上一层是各种各样的业务中台,再往上的话就是具体的业务线。
以 docker 和 k8s 为代表的容器技术,通过容器镜像、作业编排、作业调度、资源管理实现了对上层应用的资源透明。上层应用想要跑得更快的话,其实还是需要一套服务治理的体系。整体的服务治理体系以注册发现为基石,包含观察、通信协议、流量管控等方面,这就是作业帮云原生架构的全貌。
下面介绍下作业帮各层多活建设的概要,后面每一个方向还会有单独的文章再进行详细介绍。
作业帮在实践中逐步摸索出一套“多云组网 +CPE 管控”的方案,实现在双云间甚至多云拓扑下的网络互通,以及诸多其他特性,如弹性 - 带宽快速扩缩、可观测性 - 跨云异常流量的分析、韧性 - 单节点单线路故障自动切换、可持续 - 新增云供应商的快速接入等。
单云架构下,SYS 团队运维繁多的机型已然负担较重了,多云架构带来的机型组合爆炸是一场运维灾难。只有根据应用场景制定机型规格,收敛到可控的主力机型,才能带来生产力的解放。这个还只是第一步,后面还需要通过场景套餐的方式来更标准的管理计算生命周期。
容器技术是抹平 IaaS 资源差异的核心,但这还远远不够。云原生带来的诸多优势,如在离线混部、Serverless 等,作业帮希望在每一个主力云厂商上都享受到。这就要求企业自身有一套标准,有一套容器中间件的可控能力。
服务部署应该对业务透明,这样混合云的调度才可能尽量减少对业务的扰动。作业帮除了混合云建设外,还在同步做容器化改造,且做了服务注册发现机制的替换。在这种难上加难的场景下,基础架构团队设计并落地了一套平稳过渡的方案。
除了同步 RPC 调用外,异步调用也面临同样的问题。
不论是日志、监控,还是链路追踪,技术人员都需要一套统一视角,减少混合云架构的影响。
这里的调度主要指的南北向,用户流量的调度。调度的单位一般是域名。
多云间流量如何精准分配,将误差控制在 1% 只内?单云故障后切流后如何让用户在 5 分钟内完成恢复?只靠 DNS 是远远不够。作业帮基于 CoreDNS 自研了一套 DoH 的解决方案。除了解决用户网络被劫持外,也成为多云流量调度的一大利器。
多云场景下,数据存储主要面临的还是经典的 CAP 问题,在出现数据分区的情况下,A 可用性和 C 一致性无法兼得,要么 AP,要么 CP。作业帮这块根据具体业务场景选择对应方案,除了主从架构外,也在实践单元化、MGR 等的方案。
多云架构在应用层面临两个需求。一是常态情况下应用间禁止跨云访问,这样才能有效防止墒增,不出现增量的跨云调用。另一个则是特殊情况下,如机房迁移、单云服务异常等,需要能够灵活调度多云间流量。
这两个需求是矛盾的,但又都是客观存在的。作业帮在这块使用“隔离区 + 互通区”的设计巧妙的解决了这个难题。
应用层的问题不只这一个,在线应用和大数据实时服务的耦合也十分棘手。
随着业务运营的精细化,对大数据实时查询的需求越来越多。在线服务会直接调用大数据实时引擎处理结果,但大数据实时服务还不像 MySQL、Redis、ES 等具有完备的多云能力,甚至很多就是单家云供应商提供的 PaaS 组件。这种情况下借鉴上述思路,实现单云服务和多云服务间的隔离。
一路走来,笔者对作业帮混合云多活架构的建设感受良多,其不单单是容器多集群的管理和流量调度,更是一整套贯穿资源和应用的企业架构整体解决方案。
混合云多活架构,需要 SYS、容器研发、中间件研发、SRE、DBA、DevOps、FinOps、安全等基础架构诸多方向精诚合作,需要所有业务研发部门鼎力支持,需要一个强有力的技术组织体系才能完成。
上述为作业帮混合云多活架构的综述,后续文章会逐渐为大家介绍多活架构中 IaaS、PaaS、SaaS 的技术细节以及迁移新云的 SOP,请大家持续关注。
作者介绍:
董晓聪,作业帮基础架构负责人、阿里云云原生方向 MVP、腾讯云云原生方向 TVP,主要负责作业帮架构研发、运维、DBA、安全等工作。曾在百度、滴滴等公司负责架构和技术管理工作,擅长业务中台、技术中台、研发中台的搭建和迭代。
吕亚霖,作业帮基础架构 - 架构研发团队负责人。负责技术中台和基础架构工作。在作业帮期间主导了云原生架构演进、推动实施容器化改造、服务治理、GO 微服务框架、DevOps 的落地实践。
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
10万 npm 用户账号信息被窃、日志中保存明文密码,GitHub安全问题何时休?
我们用了一个周末,将 370 万行代码迁移到了 TypeScript

点个在看少个 bug 👇
