新书福利 |《数据挖掘与分析:概念与算法》

本书节选自:《数据挖掘与分析:概念与算法》的第一章。数据挖掘是从大规模数据中发现新颖、深刻、有趣的模式和具有描述性、可理解、能预测的模型的过程。本章首先讨论数据矩阵的基本性质。我们会强调数据的几何和代数描述以及概率解释。接下来讨论数据挖掘的主要任务,包括探索性数据分析、频繁模式挖掘、聚类和分类,从而为本书设定基本的脉络。
参与方式:阅读本文后,请在评论区分享你对文章所讲内容中肯的看法,根据评论质量和评论点赞数,前五名的用户可获得本书。活动时间截至9月24日晚8点(周日)。感谢图灵教育对活动的支持
1.1 数据矩阵
数据经常可以表示或者抽象为一个n × d 的数据矩阵,包含n 行d 列,其中各行代表数据集中的实体,而各列代表了实体中值得关注的特征或者属性。数据矩阵中的每一行记录了一个给定实体的属性观察值。n×d 的矩阵如下所示:

根据应用领域的不同,数据矩阵的行还可以被称作实体、实例、样本、记录、事务、对象、数据点、特征向量、元组,等等。同样,列可以被称作属性、性质、特征、维度、变量、域,等等。实例的数目n 被称作数据的大小,属性的数目d 被称作数据的维度。针对单个属性进行的分析,称作一元分析;针对两个属性进行的分析,称作二元分析;针对两个以上的属性进行的分析,称作多元分析。
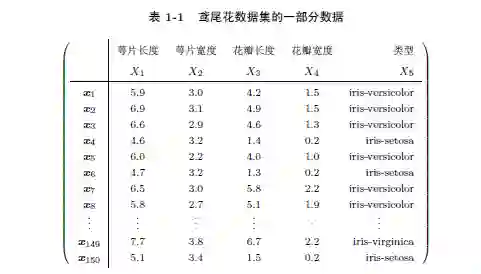
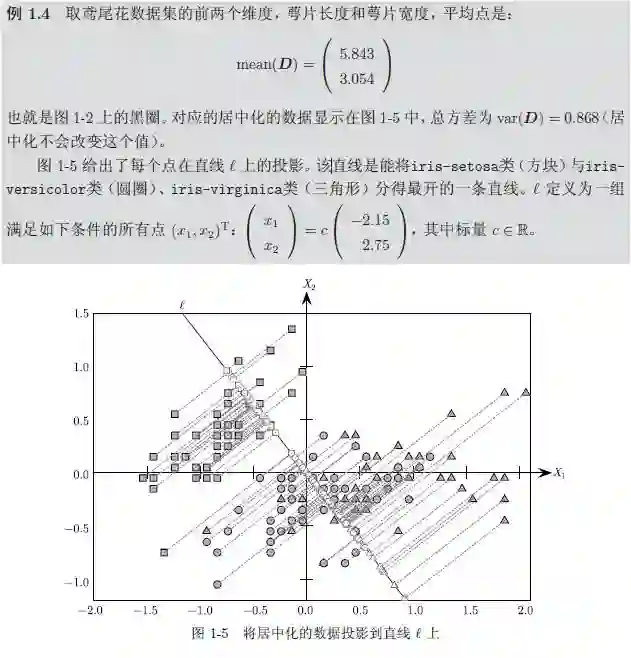
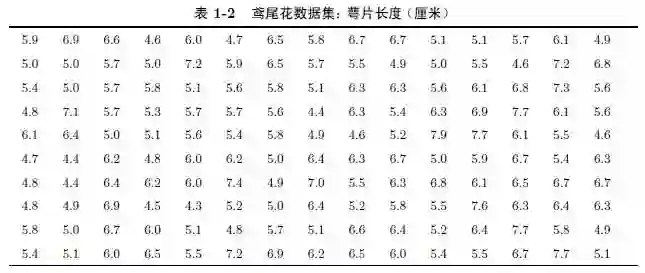
例1.1 表1-1 列举了鸢尾花(iris)数据集的一部分数据。完整的数据集是一个150×5 的矩阵。每一行代表一株鸢尾花,包含的属性有:萼片长度、萼片宽度、花瓣长度、花瓣宽度(以厘米计),以及该鸢尾花的类型。第一行是一个如下的五元组:
x₁ = (5:9,3:0,4:2,1:5,iris-versicolor)
并非所有的数据都是以矩阵的形式出现的。复杂一些的数据还可以以序列(例如DNA和蛋白质序列)、文本、时间序列、图像、音频、视频等形式出现,这些数据的分析需要专门的技术。然而,在大多数情况 下,即使原始数据不是一个数据矩阵,我们还是可以通过特征提取将原始数据转换为一个数据矩阵。例如,给定一个图像数据库,我们可以创建这样一个数据矩阵:每一行代表一幅图像,各列对应图像的特征,如颜色、纹理等。有些时候,某些特定的特征可能蕴含了特殊的语义,处理的时候需要特别对待。比如,时序和空间特征通常都要区别对待。值得指出的是,传统的数据分析假设各个实体或实例之间是相互独立的。但由于我们生活在一个互联的世界里面,这一假设并不总是成立。一个实例可能通过各种各样的关系与其他实例相关联,从而形成一个数据图:图的节点代表实例,图的边代表实例间的关联关系。
1.2 属性
属性根据它们所取的值主要可以分为两类。
1 . 数值型属性
数值型属性是在实数或者整数域内取值。例如,取值域为N 的属性Age(年龄),即是一个数值型属性,其中N 代表全体的自然数(即所有的非负整数);表1-1 中的花瓣长度同样也是一个数值型属性,其取值域为R+(代表全体正实数)。取值范围为有限或无限可数集合的数值属性又被称作离散型的;取值范围为任意实数的数值属性又被称作连续型的。作为离散型的特例,取值限于集合f0,1g 的属性又被称为二元属性。数值属性又可以进一步分成如下两类。
区间标度类:对于这一类属性,只有差值(加或减)有明确的意义。例如,属性温度(无论是摄氏温度还是华氏温度)就是属于区间标度型的。假设某一天是20±C,接下来一天是10±C,那么谈论温度降了10±C 是有意义的,却不能说第二天比第一天冷两倍。
比例标度类:对于这一类属性,不同值之间的差值和比例都是有意义的。例如,对于属性年龄,我们可以说一个20 岁 的人的年龄是另一个10 岁的人的年龄的两倍。
2 . 类别型属性
类别型属性的定义域是由一个定值符号集合定义的。例如,Sex(性别)和Education(教育水平)都是类别型属性,它们的定义域如下所示:
domain(Sex) ={M,Fg}domain(Education) = {HighSchool,BS,MS,PhD}
类别型属性也可分为两种类型。
名义类:这类属性的定义域是无序的,只有相等性比较才有意义。也就是说,我们只能判断两个不同实例的属性值是否相等。例如性别就是一个名义类的属性。表1-1 中的类别属性也是名义类的,其定义域domain(class) =firis-setosa,iris-versicolor,iris-virginicag。
次序类:这类属性的定义域是有序的,因此相等性比较(两个值是否相等)与不等性比较(一个值比另一个值大还是小)都是有意义的,尽管有的时候不能够量化不同值之间的差。例如,教育水平是一个次序类属性,因为它的定义域是按受教育水平递增排序的。
1.3 数据的几何和代数描述
若数据矩阵D 的d 个属性或者维度都是数值型的,则每一行都可以看作一个d 维空间的点:
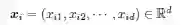
或者,每一行可以等价地看作一个d 维的列向量(所有向量都默认为列向量):
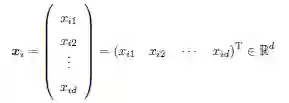
其中T 是矩阵转置算子。
d 维笛卡儿坐标空间是由d 个单位向量定义的,又被称作标准基,每个轴方向上一个。第j 个标准基向量ej 是一个d 维的单位向量,该向量的第j 个分量是1,其他分量是0。
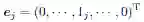
Rd 中的任何向量都可以由标准基向量的线性组合来表示。例如,每一个点xi 都可以用如下的线性组合来表示:
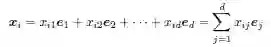
其中标量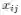
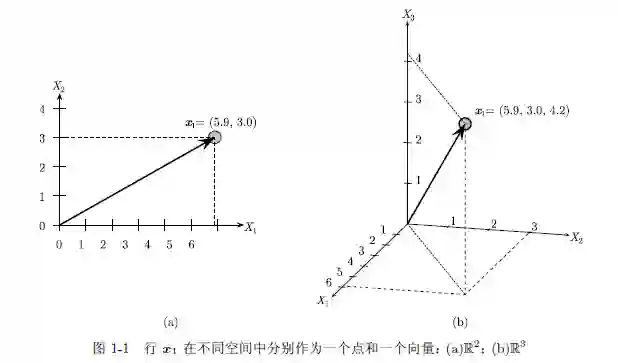
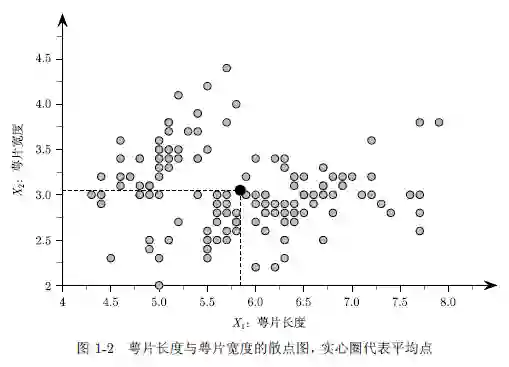
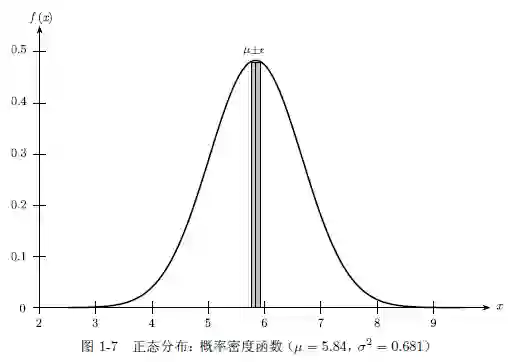
例1.2 考虑表1-1 中的鸢尾花数据。如果我们将所有数据映射到前两个属性,那么每一行都可以看作二维空间中的一个点或是向量。例如,五元组x₁=(5.9, 3.0, 4.2, 1.5,iris-versicolor)在前两个属性上的投影如图1-1a 所示。图1-2 给出了所有150 个数据点在由前两个属性构成的二维空间中的散点图。图1-1b 将x₁ 显示为三维空间中的一个点和向量,该三维空间将数据映射到前三个属性。(5.9,3.0,4.2)可以看作R³ 中标准基线性组合的系数:
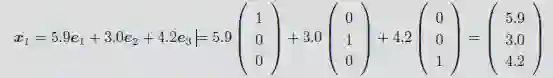
每一个数值型的列或属性还可以看成 n 维空间Rⁿ 中的一个向量:
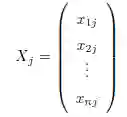
如果所有的属性都是数值型的,那么数据矩阵D 事实上是一个n × d 的矩阵,可记作D ∈ 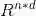
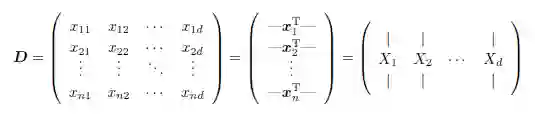
我们可以将整个数据集看成一个n × d 的矩阵,或是一组行向量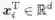

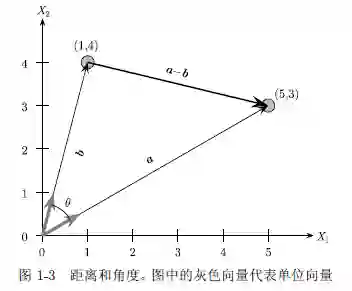
1.3.1 距离和角度
将数据实例和属性用向量来描述或者将整个数据集描述为一个矩阵,可以应用几何与代数的方法来辅助数据挖掘与分析任务。
假设a; b ∈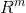
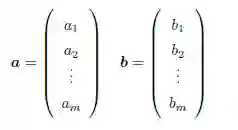
1 . 点乘
a 和b 的点乘定义为如下的标量值:
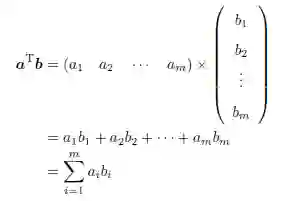
2 . 长度
向量a ∈
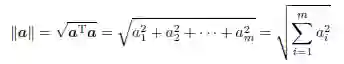
a 方向上的单位向量定义为:
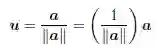
根据定义,单位向量的长度为‖u‖ = 1,它又可被称为正则化向量,在某些分析中可以代替向量a。
欧几里得范数Lp 是范数的特例,定义为:
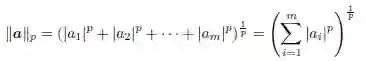
其中p ≠ 0。因此,欧几里得范数是p = 2 的Lp 范数。
3 . 距离
根据欧几里得范数,我们可以定义两个向量a 和b 之间的欧氏距离如下:
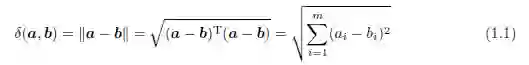
因此,向量a 的长度即是它到零向量0 的距离(零向量的所有元素都为0),亦即‖a‖ =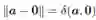
根据Lp 范数的定义,我们可以定义对应的Lp 距离函数如下:

若没有指明p 的具体值,如公式(1.1),则默认p = 2。
4 . 角度
两个向量a 和b 之间的最小角的余弦值,被称作余弦相似度,由如下公式定义:
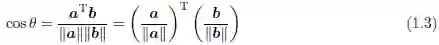
因此,向量a 和b 间角度的余弦可以通过a 和b 的单位向量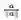
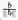
柯西-施瓦茨(Cauchy-Schwartz)不等式描述了对于
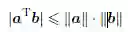
则根据柯西{施瓦茨不等式马上可以得到:
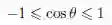
由于两个向量之间的最小角θ ∈ [0°; 180°] 且cos θ ∈ [-1; 1],余弦相似度取值范围为+1(对应0°角)到-1(对应180° 角,或是π 弧度)
5 . 正交性
我们说两个向量a 和b 是正交的,当且仅当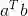

1.3.2 均值与总方差
1 . 均值
数据矩阵D 的均值(mean)由所有点的向量取平均值得到,如下所示:
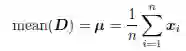
2 . 总方差
数据矩阵D 的总方差(total variance)由每个点到均值的均方距离得到:
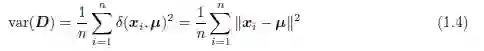
化简公式(1.4),可以得到:
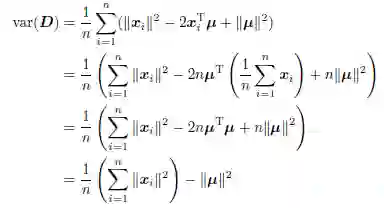
因此总方差即是所有数据点的长度平方的平均值减去均值(数据点的平均)长度的平方。
3 . 居中数据矩阵
通常我们需要将数据矩阵居中,以使得矩阵的均值和数据空间的原点相重合。居中数据矩阵可以通过将所有数据点减去均值得到:
其中zi = xi ¡ ¹ 代表与xi 对应的居中数据点,1 2 Rn 是所有元素都为1 的n 维向量。居中矩阵Z 的均值是0 2 Rd,因为原来的均值¹ 已经从所有的数据点减去了。
1.3.3 正交投影
在数据挖掘中我们经常需要将一个点或向量投影到另一个向量上。例如,在变换基向量之后获取一个新的点坐标。令a; b ∈ 为两个m 维的向量。向量b 在向量a 方向上的正交分解(orthogonal decomposition),可用下式表示(见图1-4):

其中
向量p 与向量a 是平行的,因此对于某个标量c,我们有p = ca。因此,r = b - p =b - ca。由于p 和r 是正交的,我们有:
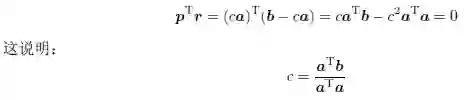
因此,b 在a 上的投影又可以表示为:

1.3.4 线性无关与维数
给定一个数据矩阵
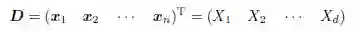
我们经常对各行(不同的点)或各列(不同的属性)的线性组合感兴趣。例如,不同的属性之间的线性组合可以产生新的属性,这一做法在特征提取及降维中起到了关键作用。在m 维的向量空间Rm 中给定任意一组向量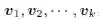
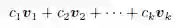
其中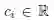

1 . 行空间和列空间
数据矩阵D 有几个有趣的向量空间,其中两个是D 的行空间与列空间。D 的列空间,用col(D)表示,是d 个属性
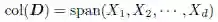
根据定义,col(D)是 的一个子空间。D 的行空间,用row(D)表示,是n 个点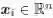
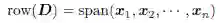
根据定义,row(D)是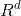
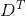
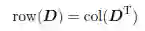
2 .线性无关
给定一组向量v1,... vk,若其中至少有一个向量可以由其他向量线性表出,则称它们是线性相关的。等价地,若有k 个标量c1,c2,..ck,其中至少有一个不为0 的情况下,可以使得
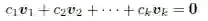
成立,则这k 个向量是线性相关的。
另一方面,这k 个向量是线性无关的,当且仅当

简而言之,给定一组向量,若其中任一向量都无法由该组中其他向量线性表示,则该组向量是线性无关的。
3 . 维数和秩
假设S 是Rm 的一个子空间。S 的基(basis)是指S 中一组线性无关的向量v1, ... , vk,这组向量生成S,即span(v1;... ; vk) = S。事实上,基是一个最小生成集。若基中的向量两两正交,则称该基是S 的正交基(orthogonal basis)。此外,若这些向量还是单位向量,则它们构成了S 的一个标准正交基(orthonormal basis)。例如,Rm 的标准基是一个由如下向量构成的标准正交基:
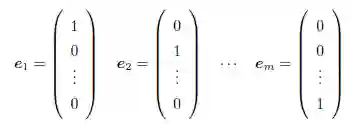
S 的任意两个基都必须有相同数目的向量,该数目称作S 的维数,表示为dim(S)。S 是
值得注意的是,任意数据矩阵的行空间和列空间的维数都是一样的,维数又可称为矩阵的秩。对于数据矩阵
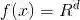
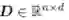
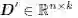

1.4 数据:概率观点
数据的概率观点假设每个数值型的属性X 都是一个随机变量(random variable),是由给一个实验(一个观察或测量的过程)的每个结果赋一个实数值的函数定义的。形式化定义如下:X 是一个函数X : O→R,其中O 作为X 的定义域,是实验所有可能结果的集合,又被称作样本空间(sample space);R 代表X 的值域,是实数的集合。如果实验结果是数值型的,且与随机变量X 的观测值相同,则X : O→ O 就是恒等函数:X(v) = v, v ∈ O。实验结果与随机变量取值之间的区别是很重要,在不同的情况下,我们可能会对观测值采用不同的处理方式,可参见例1.6。
若随机变量X 的取值是一组有限或可数无限值,则称作离散随机变量(discrete randomvairable);反之,则称作连续随机变量(continuous random vairable)。

概率质量函数
若X 是离散的,则X 的概率质量函数可定义为:
f(x) = P(X = x); x ∈ R
换句话说,函数f 给出了随机变量X 取值x 的概率P(X = x)。“概率质量函数”(probabilitymass function)这个名字直观地表达了概率聚集在X 的值域内的几个离散值上,其余值上的概率为0。f 必须要遵循概率的基本规则,即f 必须为非负:
f(x) ≥ 0
而且所有概率的和必须等于1,即:
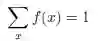

2 . 概率密度函数
若X 是连续的,则其取值范围是整个实数集合R。取任意特定值x 的概率是1 除以无穷多种可能,即对所有x ∈ R,P(X = x) = 0。然而,这并不意味着取值x 是不可能的,否则我们会得出所有取值都不可能的结论!其真正含义是概率质量在可能的取值范围上分布得如此细微,使得它只有在一个区间[a, b] 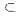
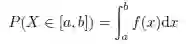
跟之前一样,概率密度函数f 必须满足概率的基本条件:
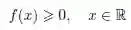
且
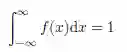
我们可以通过考虑在一段以x 为中点的很小的区间2ε > 0 上的概率密度来获得对密度函数f 的直观理解,即[x - ε; x + ε]:
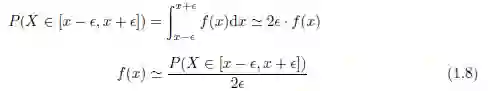
f(x) 给出在x 处的概率密度,等于概率质量与区间长度的比值,即每个单位距离上的概率质量。因此,需要特别注意P(X = x) ≠ f(x)。
尽管概率密度函数f(x) 不能确定概率P(X = x),但是它可用于计算一个值x₁ 相对另一个值x₂ 的概率,因为对于ε > 0,根据公式(1.8),我们有:
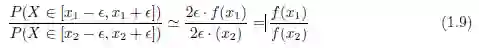
因此,若f(x₁) 比f(x₂) 大,则X 的值靠近x₁ 的概率要大于靠近x₂ 的概率,反之亦然。

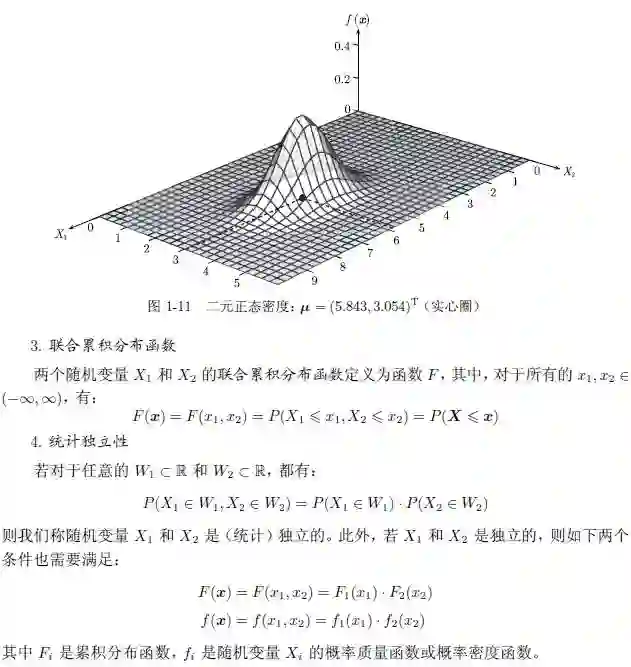
累积分布函数
对于任意的随机变量X,无论是离散的还是连续的,我们都可以定义累积分布函数(CDF)F : R → [0, 1],该函数给出了观察到的最大值为某个给定点x 的概率:
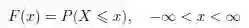
当X 为离散型时,F 可以表示如下:
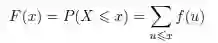
当X 为连续型时,F 可以表示如下:
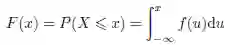

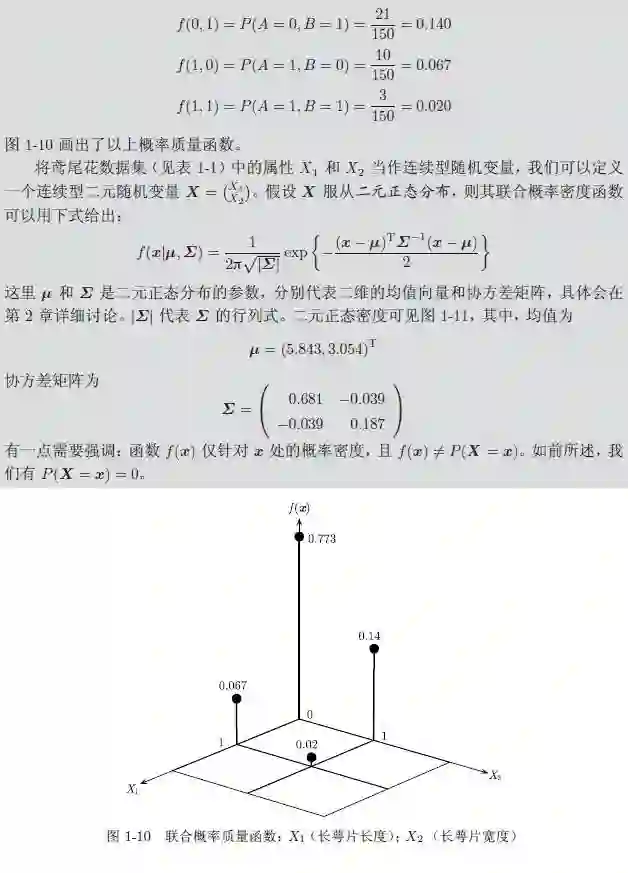
1.4.1 二元随机变量
对于一组属性X₁ 和X₂,除了将每个属性当作一个随机变量之外,我们还可以把它们当作一个二元随机变量进行成对的分析:
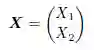

f 必须满足如下两个条件:
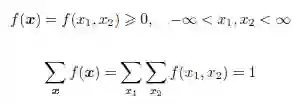
2 . 联合概率密度函数
若X₁ 和X₂ 同为连续型随机变量,则X 的联合概率密度函数如下所示:
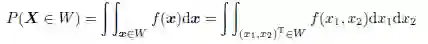
其中,W 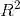
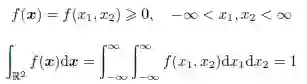

1.4.2 多元随机变量

若所有的Xj 都是连续的,则X 是联合连续的,其联合概率密度函数可以定义如下:

1.4.3 随机抽样和统计量
随机变量X 的概率质量函数或概率密度函数可能遵循某种已知的形式,也可能是未知的(数据分析中经常出现这种情况)。当概率函数未知的时候,根据所给数据的特点,假设其服从某种已知分布可能会有好处。然后,即使在这种假设情况之下,分布的参数依然是未知的。因此,通常需要根据数据来估计参数或者是整个分布。
在统计学中,总体(population)通常用于表示所研究的所有实体的集合。通常我们对整个总体的特定特征或是参数感兴趣(比如美国所有计算机专业学生的平均年龄)。然而,检视整个总体有时候不可行或代价太高。因此,我们通过对总体进行随机抽样、针对抽样到的样本计算合适的统计量来对参数进行推断,从而对总体的真实参数作出近似估计。
1 . 一元样本
给定一个随机变量X,对X 的大小为n 的随机抽样样本定义为一组n 的个独立同分布(independent and identically distributed,IID)的随机变量S1, S2; ... Sn,即所有Si 之间是相互独立的,它们的概率质量或概率密度函数与X 是一样的。
若将X 当作一个随机变量,则可以将X 的每一个观察xi(1 ≤ i ≤ n)本身当作一个恒等随机变量,并且每一个观察到的数据都可以假设为从X 中随机抽样到的一个样本。因此,所有的xi 都是互相独立的,并且与X 是同分布的。根据公式(1.11),它们的联合概率函数可以按下式给出:
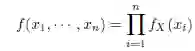
其中fX 是X 的概率质量函数或概率密度函数。
估计一个多元联合概率分布的参数通常比较困难而且很耗费计算资源。为了简化,一种常见的假设是d 个属性X1,X2, ... ;Xd 在统计上是独立的。然而,我们没有假设它们是同分布的,因为那几乎从不会发生。在这种属性独立假设下,公式(1.12) 可以重写为
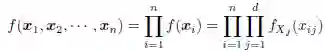
3 . 统计量

1.5 数据挖掘
数据挖掘是由一系列能够帮助人们从大量数据中获得洞见和知识的核心算法构成的。它是一门融合了数据库系统、统计学、机器学习和模式识别等领域的概念的交叉学科。事实上,数据挖掘是知识发现过程中的一环;知识发现往往还包括数据提取、数据清洗、数据融合、数据简化和特征构建等预处理过程,以及模式和模型解释,假设确认和生成等后处理过程。这样的知识发现和数据挖掘过程往往是高度迭代和交互的。
数据的代数、几何及概率的视角在数据挖掘中扮演着重要的角色。给定一个d 维空间中有n 个数据点的数据集,本书中涵盖的基本的分析和挖掘任务包括:探索性数据分析、频繁模式发现、数据聚类和分类模型。
1.5.1 探索性数据分析
探索性数据分析的目标是分别或者一起研究数据的数值型属性和类别型属性,希望以统计学提供的集中度、离散度等信息来提取数据样本的关键特征。除却关于数据点独立同分布的假设,将数据当作图的处理方式也很重要,在图中,节点表示数据点,加权边代表点之间的连接。从图中可以提取出很重要的拓扑属性,帮助我们理解网络和图的结构及模型。核方法为数据的独立逐点视角及处理数据间两两相似性的视角提供了联系。探索性数据分析和挖掘中的很多任务都可以通过核技巧(kernel trick)转化为核问题(kernel problem),即证明只用点对间的点乘操作就可以完成任务。此外,核方法还使得我们可以在包含“非线性”维度的高维空间中利用熟悉的线性代数和统计方法来进行非线性分析。只要两个抽象对象之间的成对相似度是可以衡量的,我们就可以用核方法来帮助挖掘复杂的数据。由于数据挖掘经常要处理包含成千上万属性和百万数据点的大数据集,探索分析的另一个目标是要进行数据约减。例如,特征选择和降维方法经常被用于选择最重要的维度,离散化方法经常被用于减少属性的可能取值,数据抽样方法可以用于减小数据规模,等等。
本书的第一部分以一元和多元数值型数据的基本统计分析开头(第2 章)。我们描述衡量数据集中度的均值(mean)、中位数(median)、众数(mode)等概念,然后讨论衡量数据离散度的极差(range)、方差(variance)、协方差(covariance)等。我们同时强调代数和概率的观点,并突出对各种度量方法的几何解释。我们尤其关注多元正态分布,因为它在分类和聚类中作为默认的参数模型被广泛使用。第3 章中,我们展示如何通过多元二项式和多项式分布对类别型数据进行建模。我们描述了如何用列联表(contingency table)分析法来测试 类别型属性间的关联性。
接着在第4 章,我们讨论如何分析图数据的拓扑结构,尤其是各种描述图中心度(graph centrality)的方式,比如封闭性(closeness)、中介性(betweenness)、声望(prestige)、PageRank,等等。我们同时还会研究真实世界网络的拓扑性质,例如小世界网络性质(small-world property,真实世界中的图节点间的平均路径长度很小)、群聚效应(clustering effect,节点间的内部群聚)、无标度性质(scale-free property,体现在节点度数按幂律分布)。我们描述了一些可以解释现实世界中图的性质的模型,例如Erdös{Rényi 随机图模型、Watts-Strogatz 模型以及Barabási-Albert 模型。
第5 章对核方法进行介绍,它们 提供了线性、非线性、图和复杂数据挖掘任务之间的内在关联。我们简要介绍了核函数背后的理论,其核心概念是一个正半定核(positive semide¯nite kernel)在某个高维特征空间里与一个点乘相对应;因此,只要我们能够计算对象实例的成对相似性核矩阵,就可以用我们熟悉的数值型分析方法来处理非线性的复杂对象分析。我们描述了对于数值型或向量型数据以及序列数据和图数据的不同核。
在第6 章,我们考虑高维空间的独特性(经常又被形象地形容为维数灾难,curse of dimensionality)。我们尤其研究了散射效应(scattering effect),即在高维空间中,数据点主要分布在空间表面和高维的角上,而空间的中心几乎是空的。我们展示了正交轴增殖(proliferation of orthogonal axes)和多元正态分布在高维空间中的行 为。最后,在第7 章我们描述了广泛使用的降维方法,例如主成分分析(principal component analysis,PCA)和奇异值分解(singular value decomposition,SVD)。PCA 找到一个能够体现数据最大方差的最优的k 维子空间。我们还展示了核PCA 方法可以用于找到使得方差最大的非线性方向。最后,我们讨论强大的SVD 方法,研究其几何特性及其与PCA 的关系。
1.5.2 频繁模式挖掘
频繁模式挖掘指从巨大又复杂的数据集中提取富含信息的有用模式。模式由重复出现的属性值的集合(项集)或者复杂的序列集合(考虑显式的先后位置或时序关系)或图的集合(考虑点之间的任意关系)构成。核心目标是发现在数据中隐藏的趋势和行为,以更好地理解数据点和属性之间的关系。
本书的第二部分以第8 章中介绍的频繁项集挖掘的高效算法开始。主要方法包括逐层的Apriori 算法、基于“垂直”交集的Eclat 算法、频繁模式树和基于投影的FPGrowth 方法。通常来讲,以上挖掘过程会产生太多难以解释的频繁模式。在第9 章我们论述概述挖掘出的 模式的方法,包括最大的(GenMax 算法)、闭合的(Charm 算法)和不可导出的项集。我们在第10 章讨论频繁序列挖掘的高效方法,包括逐层的GSP 方法、垂直SPADE 算法和基于投影的Pre¯xSpan 方法。还讨论了如何应用Ukkonen 的线性时间和空间的后缀树算法高效挖 掘连续子序列(或称为子串)。
第11 章讨论用于频繁子图挖掘的高效且流行的gSpan 算法。图挖掘包括两个关键步骤,即用于在模式枚举的过程中消除重复模式的图同构检测(graph isomorphism check)以及频率计算时进行的子图同构检测(subgraph isomorphism check)。对 集合和序列来说,可以在以上操作多项式时间内完成,然而,对于图来说,子图同构问题是NP 难的,因此除非P=NP,否则是找不到多项式时间算法的。gSpan 方法提出了一种新的规范化编码(canonical code)和一种进行子图扩张的系统化方法,使得其能够高效地进行重复检测并同时高效地进行多个子图同构检测。模式挖掘可能会产生非常多的输出结果,因此对挖掘出的模式进行评估是非常重要的。
第12 章讨论了评估频繁模式的策略以及能从中挖掘出的规则,强调了显著性检验(signi¯cance testing)的方法。
1.5.3 聚类
聚类是指将数据点划分为若干簇,并使得簇内的点尽可能相似,而簇间点尽可能区分开的任务。根据数据和所要的簇的特征,有不同的聚类方法,包括:基于代表的(representative-based)、层次式的(hierarchical)、基于密度的(density-based)、基于图的(graph-based)和谱聚类。
本书第三部分以基于代表的聚类方法开始(第13 章),包括K-means 和期望最大(EM)算法。K-means 是能够最小化数据点与其簇均值的方差的一种贪心算法,它进行的是硬聚类,即每个点只会赋给一个簇。我们也说明了核K-means 算法如何用于非线性簇。作为对K-means 算法的泛化,EM 将数据建模为正态分布的混合态,并通过最大化数据的似然(likelihood)找出簇参数(均值和方差矩阵)。该方法是一种软聚类方法, 即该算法给出每一个点属于每一个簇的概率。
在第14 章,我们考虑不同的聚合型层次聚类方法(agglomerative hierarchical clustering),从每个点所在的簇开始,先后合并成对的簇,直到找到所要数目的分簇。我们了解不同层次式方法采用的不同簇间邻近性度量。在某些数据集中,来自不同簇的点间的距离可能比同一簇间点的距离更近;这在簇形状为非凸的时候经常发生。
第15 章介绍了基于密度的聚类方法使用密度或连通性性质(connectedness property)来找出这样的 非凸簇。两种主要的方法是DBSCAN 和它的泛化版本DENCLUE,后者基于核密度估计。第16 章探讨图聚类方法,这些方法通常都基于对图数据的谱分析。图聚类可以被认为是图上的一个k 路割优化问题;不同的目标可以转换为不同图矩阵的谱分解,例如(正态)邻接矩阵、拉普拉斯(Laplacian)矩阵等从原始图数据或是从核矩阵中导出的矩阵。最后,由于有多种多样的聚类方法,我们要评估挖掘出的簇是否能够很好地捕捉到数据的自然组(natural group)。
第17 章讨论了不同的聚类验证和评估策略;这些策略生成内部和外部的度量,并将聚类结果与真实值(ground-truth)进行比较(若存在的话),或者比较两个不同的聚类。还讨论了有关聚类稳定性的方法,即聚类对数据扰动的敏感度和聚类趋势(即数据的可聚类性)。我们也介绍了选择参数k 的方法,这是一个通常由用户指定的簇的数目。
1.5.4 分类

1.6 补充阅读

本章完
关于本书
本书是专注于数据挖掘与分析的基本算法的入门图书,内容分为数据分析基础、频繁模式挖掘、聚类和分类四个部分,每一部分的各个章节兼顾基础知识和前沿话题,例如核方法、高维数据分析、复杂图和网络等。每一章最后均附有参考书目和习题。扫码查看本书的完整目录以及其他详细信息。

AI公开课
主题:让机器读懂你的意图——人体姿态估计入门
时间:9月26日晚8点
嘉宾:曾冠奇,便利蜂智能零售实验室团队负责人
内容:
人体姿态估计在新零售的应用点
人体姿态估计的整个知识结构树
人体姿态估计一个流派的论文、算法和代码解析
扫码报名

主题:深度学习中基础模型性能的思考和优化
时间:已结课(可看复播)
嘉宾:吴岸城 菱歌科技首席算法科学家
扫码学习:

主题:XGBoost模型原理及其在各大竞赛中的优异表现
时间:已结课(可看复播)
嘉宾:卿来云 中科院副教授
扫码学习:

主题:深度学习入门及如何转型AI领域
时间:已结课(可看复播)
嘉宾:覃秉丰 深度学习技术大咖
扫码学习:


☞ 点赞和分享是一种积极的学习态度


