以人为本的计算机视觉研究:WIDER Challenge 2019(人脸检测/行人检测/人物检索)
加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
作者 | 黄QQ
来源 | https://zhuanlan.zhihu.com/p/67236295
已获作者授权,请勿二次转载
前言
计算机视觉技术近几年在深度学习的加持下,进展飞速,也吸引了无数科研人员投身其中。万千科研大军涌向这个领域,虽然大家关注点大相径庭,但是终极目标却是一致的,无非就是希望技术能够为人服务,抑或解放生产力,抑或提高生活质量。既然科技是要为人服务的,那么这其中与“人”有关的研究就扮演了不可或缺的重要角色。与“人”相关的研究无论在学术界还是工业界,都是当之无愧的主角。
结合MMLab(包含港中文,南洋理工,悉尼三个实验室)在学术领域的多年积累,和商汤、亚马逊在工业界的遇到的实际问题,我们提炼出了几个与“人”有关的研究课题,举办了今年的WIDER Face and Person 竞赛。这个竞赛共包含了四个任务,分别是人脸检测(Face Detection),行人检测(Pedestrian Detection),基于头像的人物检索(Person Search by Portrait),基于自然语言的人物检索(Person Search by Language)。
这几个与“人”有关的课题的共同点是既有非常高的应用价值,同时又有非常大的挑战性。我们的目标是希望这个竞赛能够抛砖引玉,为相关课题的研究提供一个统一的检验平台,同时也作为一个研究员的交流集散中心,不同的想法可以在这里擦出更大的火花。
人脸检测(Face Detection)

WIDER Face人脸检测数据集是人脸检测领域中的标准数据集。WIDER Face数据集 [1] 于2016年由港中文商汤联合实验室搜集、标注并作为口头报告发布在当年的计算机视觉顶级会议CVPR上。在三年年多时间里,WIDER Face已成为人脸检测领域广泛使用的标准数据集。相比较于之前的人脸检测数据集,WIDER Face数据集在数据难度,图片和标注数量上都有一个数量级的提升。
现有的WIDER Face人脸检测数据集使用VOC竞赛的测试协议。为了鼓励算法实现更加准确的人脸定位,本次竞赛我们采用MS COCO竞赛的测试协议。与之前其他竞赛只侧重于准确率不同,我们今年加入了一个衡量算法速度的实验性子赛事。希望借此机会鼓励研究者开发更加实用的人脸检测算法。
行人检测(Pedestrian Detection)

行人检测是物体检测的重要分支,也是长期以来难以解决的问题。从重要性来讲,行人检测是行人追踪、自动驾驶、安防监控等任务的基础。虽然只有“人”这一单一类别,我们仍然面临很多挑战,比如检测的场景很多样,行人的姿态很复杂,目标可能被遮挡住等等。
在WIDER Pedestrian数据集中,我们主要关注安防监控和自动驾驶这两个重要的应用场景,并从这两个场景分别收集了数据,提供了大规模图片训练集。对于安防监控领域,由于摄像头可能出现在各个地方,拍摄的场景是较为多变和复杂的。另外,不同摄像头的角度(有些为平拍而有些为俯拍)差异较大,使得数据集中图片的视角较为多样。此外,还有行人检测中的常见问题,例如密集遮挡情况和小尺度目标较多等。对于自动驾驶领域,由于数据全部都是由行驶过程中的车载摄像头拍摄而成,这就导致了场景透视效果非常明显和行人尺度差异较大(从几个像素到几百像素)。另外,摄像头的画面非高清,使得行人的尺度不清晰。图片背景中也存在较多的人形物体,比如街边的广告牌和车窗反射的人影,易带来较多误检。此外,在两个场景中都存在一定量的夜间拍摄图片,给检测带来了更大难度。
在WIDER 2019中,我们提供了规模更大的数据集,将WIDER 2018中的11500张训练图片扩充至91500张,增加的数据全部来自自动驾驶场景。数据量到了这个级别后,我们可以脱离ImageNet预训练的模型,从随机初始化的参数来学习,从而给模型设计提供了更高的自由度。我们希望参赛者可以考虑两个场景的差异,提出更具针对性的模型。WIDER 2018中,很多参赛者并没有对两个场景做出区分,而是采用统一训练的方式[2]。另外,我们鼓励参赛者不使用model ensemble,而是尝试找到一些更具竞争力的单模型。
行人检测作为计算机视觉中传统而重要的任务,仍然存在许多有待解决的问题。我们希望看到更多创新、高效、鲁棒的算法,给行人检测带来更多活力。
基于头像的人物检索(Person Search by Portrait)

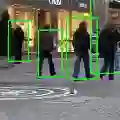
目前学术界和工业界与人物检索有关的研究,主要有人脸识别(Face Recognition)和行人重识别(Person Re-Identification)。虽然过去几年,这两个领域都有大量的论文产出,很多相关的技术也确实在实际生活中的得到了广泛应用。我们发现,虽然在学术上我们人为的将这两个问题给切割开,但是在一个更高的层次上看这两个问题,他们要做的其实是同一件事情,就是得到一个人的ID,只是利用的信息不一样而已(一个利用了人脸,一个利用了人的着装。虽然ReID没有限制只能利用着装,但是由于数据采集的设定--小范围内,短时间内,低分辨摄像头拍摄,使得绝大部分算法是基于着装特征来判断的)。在绝大部分的应用场景里,我们的目标其实也是得到人的ID,至于利用了什么信息去得到这个ID,其实并不需要严格的限制。人为的将可利用的信息限制在人脸或者着装上,其实会大大限制算法的可推广性。什么意思呢?大概就是下面这个图的意思:

在很多应用场景里,我们有的往往只是某个人的一张照片,然后我们希望能在一个非常大的库里面去找出这个人。就比如公安机关希望给一张犯人的画像,去整个城市的监控录像里把这个人搜出来。又比如影视行业希望能够在电影里把某个演员出现的画面全部检索出来。在这种场景下,很多时候并不能看到人的正脸,而同一个人的着装和所处的环境也会有非常大的差异,甚至年龄容貌都可能有变化。这个时候只用人脸或者着装显然是不够的。
为了深入探讨这个问题,我们以电影为素材,标注了一个人物检索的巨大数据集 -- Cast Search in Movies (CSM)。这个数据集目前有630部电影,3300多位演员,超过120万图片。基于CSM,我们设立了“基于头像的人物检索”任务。就是希望能给定一张演员的头像,去电影里面检索出他出现的所有画面。
这个问题显然更贴合实际场景,当然同时也有更大的挑战性。解决这个问题目前的思路目前大多是“人脸人体联合检索”,大致思路就是先用人脸去检索,然后把检索出来的结果当成正确的样本,再利用这些样本的着装特征去做第二次检索。这也是WIDER 2018大多数参赛队伍的方法[2]。在ECCV 18上我们也提出了基于标签传播的方法 [3],本质上也是人脸人体时序三种特征的联合使用,只不过可以建模成一个迭代的传播算法,更加高效优雅。当然,除了视觉特征和时序特征的使用,上下文信息的使用其实也是解决这个问题的一个关键点,比如利用人与人之间的关系,人与场景之间的关系 [4]。
总而言之,这是一个非常有意思的新坑,有非常多值得探讨的问题,非常欢迎各路高人一起来填坑!
基于自然语言的人物检索(Person Search by Language)

基于自然语言信息来检索大规模数据集中的行人图片是一项重要且具有挑战性的任务。在很多场景下,我们并不能得到可靠的待搜索对象的视觉信息。以安防为例,在得不到犯罪分子照片的情况下,我们只能根据目击证人描述的犯罪分子的外貌特征(自然语言)去在数据集中搜索对应的人。又或者在搜索引擎中,在不知道待搜索对象的确切信息的情况下,我们只能使用模糊的语言描述来作为搜索信息。这就需要我们的算法和模型在训练中能对自然语言和视觉这两种信息都能够进行恰当地处理,以求在只有自然语言作为检索信息的情况下,模型能够搜索到对应的行人图片。
在WIDER 2019 Person Search by Language挑战中,我们将采用CUHK-PEDES [5]数据集来作为训练集。相比用图片或视频作为搜索信息的传统person re-identification问题,person search by language这项任务更加具有挑战性,更加需要研究者同时对CV和NLP问题有着深刻的理解。我们欢迎各位同学踊跃参与和交流,为这个领域带来更多的活力和更深刻的思考。
** 重要信息 **
比赛的时间:2019年5月15日 - 2019年7月25日
我们提供了丰厚的现金和亚马逊服务器机时奖励给获胜队伍。同时参赛者也会有机会被邀请投稿到我们的ICCV同名Workshop。
关于比赛的更多信息可以关注我们的官网:http://wider-challenge.org/2019.html
Reference
[1] Y. Shuo, P. Luo, C.C. Loy, and X. Tang. "WIDER face: A face detection benchmark." In CVPR, 2016.
[2] C. C. Loy, D. Lin, W. Ouyang, Y. Xiong, S. Yang, Q. Huang, D. Zhou, W. Xia, Q. Li, P. Luo, et al. "WIDER face and pedestrian challenge 2018: Methods and results." arXiv:1902.06854, 2019. 2, 4, 5
[3] Q. Huang, W. Liu, and D. Lin. "Person search in videos with one portrait through visual and temporal links." In ECCV, 2018.
[4] Q. Huang, Y. Xiong, and D. Lin. "Unifying identification and context learning for person recognition." In CVPR, 2018.
[5] S. Li, T. Xiao, H. Li, B. Zhou, D. Yue, X. Wang. "Person search with natural language description." In CVPR, 2017.
*延伸阅读
刷新WIDER Face多项记录!创新奇智提出高性能精确人脸检测算法
最快人脸检测遇敌手!ZQCNN vs libfacedetection
CVPR2019 | 行人检测新思路:高级语义特征检测取得精度新突破
点击左下角“阅读原文”,即可申请加入极市目标跟踪、目标检测、工业检测、人脸方向、视觉竞赛等技术交流群,更有每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流,一起来让思想之光照的更远吧~

△长按关注极市平台
觉得有用麻烦给个好看啦~