解读吴恩达新书的全球第一帖 (上)

【进入王的机器公众号,在对话框回复 MLY 可下载更新到第 19 章的书】
在教完深度学习系列后,吴恩达 (之后称大神) 最近在继续完成他原来编写的《Machine Learning Yearning》一书 (翻译成机器学习秘籍)。该书现在只完成到第 19 章 (总共有 55 章),我读完目录总结出该书要讲的七个要点,如下:
学习策略 (1 - 4 章)
目标设定 (5 - 12 章)
误差分析 (13 - 19 章)
偏差方差 (20 - 32 章)
性能对比 (33 - 35 章)
数据修正 (36 - 43 章)
端对端学习 (44 - 55 章)
此外大神在《深度学习系列- 构建机器学习项目》中,也深入了讲解了书中上述描述的内容。我也上了他的课拿了证,综合课里和书中的内容,用自己的方式为大家通俗的解读大神的新书。

2018 年 4 月 25 日北京时间早上 7 点 59 分才收到此书的最新版,希望本帖是全世界解读《机器学习秘籍》一书的第一帖。

由于该书还未全部完成,因此解读分成两个部分,本帖旨在解读前三个要点,即学习策略,目标设定和误差分析。
首先强调整本书不是讲机器学习的算法,而是讲让在实践中做机器学习项目时采用的策略,简称学习策略 (learning strategy)。该策略包括如何应对以下几个问题:
用完机器学习后效果不好怎么办?
在项目之前如何设定有效的目标?
如何有效的进行误差分析?
如何有效的识别误差来源?
如何解决数据分布不匹配问题?
什么时候可以使用端对端学习?
本帖解决前三个问题。
1.1
深度学习的起飞
要点:深度学习的流行是因为现在有大量的数据和便宜的算力。
深度学习可以不严谨的认为就是神经网络,而神经网络早在 1969 年就被研究了,而 1986 年 Hinton 的反向传播算法的论文也有效的提升了训练网络的速度,但为什么近些年深度学习才全面起飞呢?原因有三点:
大数据:IoT 产生的图片,语音,文本等。
高算力:CPU 到 GPU 到 TPU。
强算法:数据增多了,算力便宜了,研究员才有能力来研究更强的算法。这是一个正循环过程。
摩根大通在《An Investor Guide to AI》报告里也提过类似观点:
It’s the availability of big data, computing power, and the advances in algorithms – which make AI easier, cheaper and faster to implement.
下图展示了四种模型的在数据量由小到大的表现。当数据量越来越大时,传统机器学习的表现会趋于平缓,喂它再多的数据也消化不了了。而深层神经网络对数据的非常饥渴,现在如果想要最先进 (state-of-the-art) 的表现,只有用“深度学习”加“大数据”!
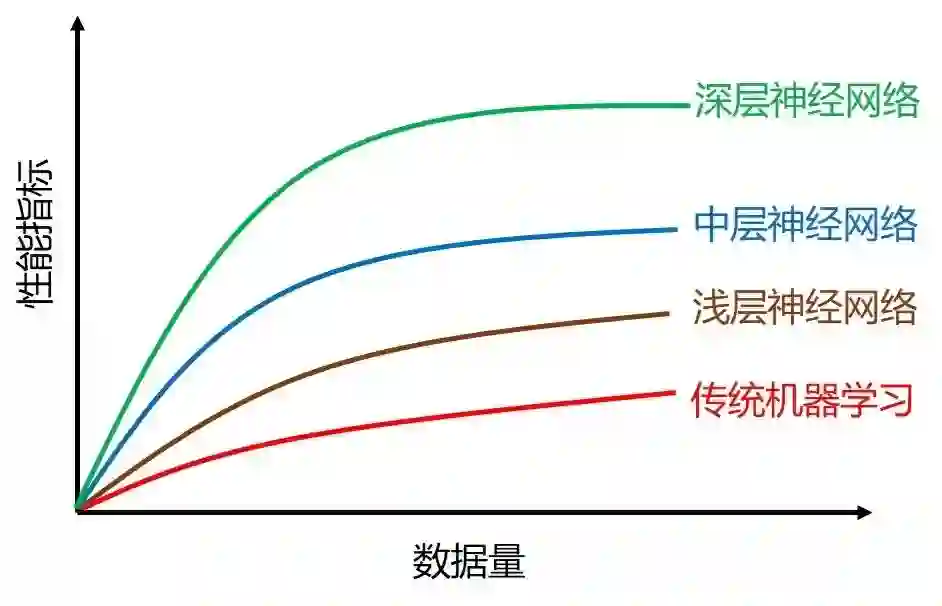
大神的图其实有些不准确,在 2000 年前数据不够多时,支撑向量机 (SVM) 的表现是稳定的压着神经网络的。更合理的图应该如下:
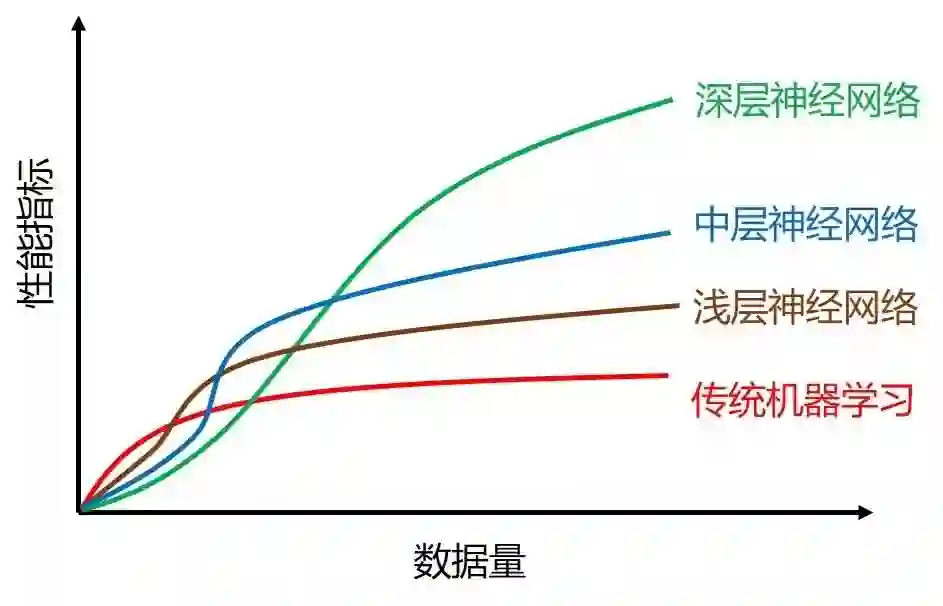
1.2
正交策略
要点:机器学习每次只调试一个参数,保持其它参数不变。这种每次只改变模型某一性能的策略叫做正交策略。
“正交性”是几何学中的术语,通俗理解正交 (orthogonalization) 就是垂直。用在计算技术中:
正交系统意味着各组件互相不依赖或解耦 (可以局部修正)
非正交系统意味着各组件互相依赖 (不能局部修正)
通常正交系统比非正交体统好,就像在线性代数中,正交向量比非正交向量好,如下图,你愿意用向量 a 和 b (正交) 还是用向量 c 和 d (非正交) 来表示 X?
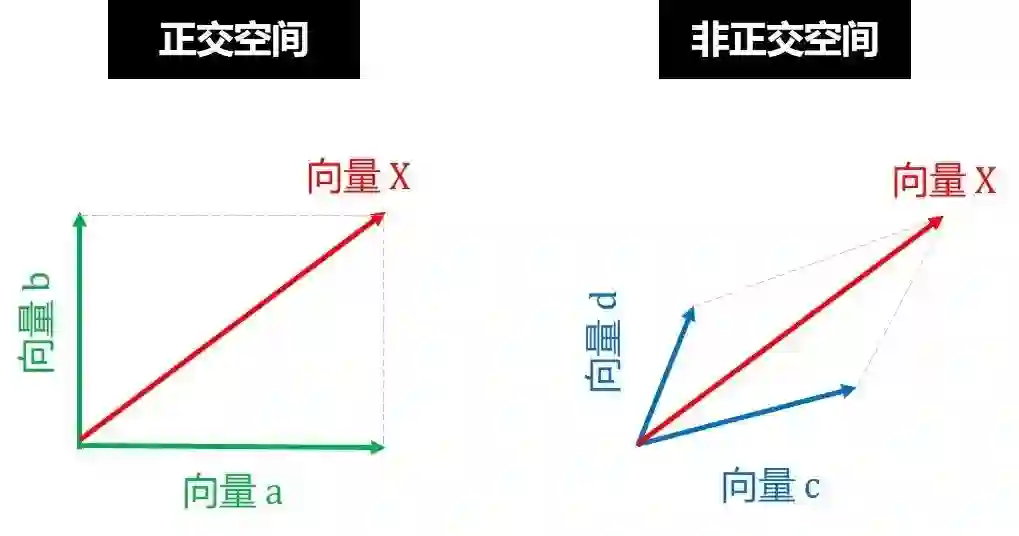
同理,你愿意将表现 X 归结于因素 a 和 b (正交) 还是归结于因素 c 和 d (非正交)?
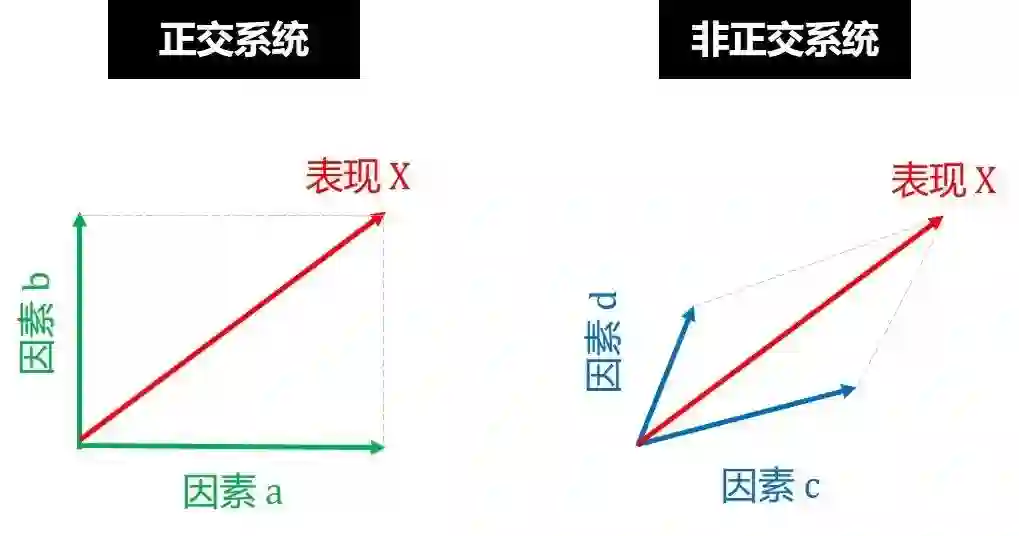
相信你的选择都是正交,因为只有正交,你调整一个组件不会影响到另一个组件。在神经网络模型中,以下四个命题是相互正交的:
模型在训练集上的表现
模型在开发集上的表现
模型在测试集上的表现
模型在真实环境的表现
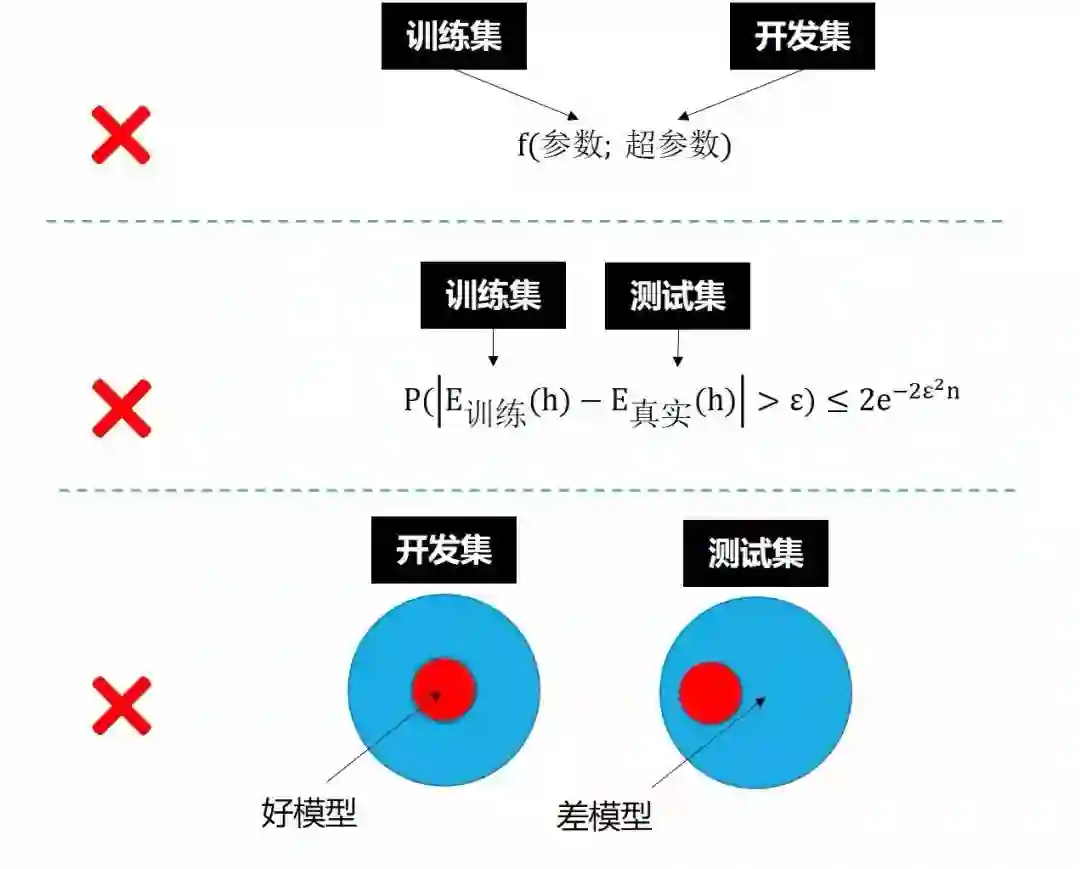
通常模型在训练集 (training set) 上训练,在开发集 (development set, dev set) 上调参,在测试集 (test set) 上评估,在真实环境中运用,因此模型的表现通常有以下关系
P训练集 > P开发集 > P测试集 > P真实环境
因此当模型在
P训练集 = 差
模型复杂度不够,用更深的神经网络
算法不够好,训练时间加长或者用 Adam
P训练集 = 好,看 P开发集
P开发集 = 差
过拟合训练集,用更大的训练集或使用正则化
P开发集 = 好,看 P测试集
P测试集 = 差
过拟合开发集,用更大的开发集
P测试集 = 好,看 P真实环境
P真实环境 = 差
数据分布不同,修改开发测试集
代价函数不合理,修改代价函数
P真实环境 = 好,恭喜你终于成功!
最后,我觉得其实麦肯锡的“MECE 原则”比“正交策略”更适合描述此问题。MECE, 全称 Mutually Exclusive Collectively Exhausive,中文是“相互独立,完全穷尽”。它是一种解决问题的方法,对于一个大问题能不重叠不遗漏的分成子问题。正交策略只点出“相互独立”的性质,而 MECE 原则还包括“完全穷尽”性质,处理问题格局更大一些。
机器学习中需要划分训练集 (用于训模),开发集 (用于调参) 和测试集 (用于评估)。为了更快更有效的开始项目,合理指定开发集测试集、选取单一指标、和迅速更换开发集测试集 (一旦出现问题) 是三大要点。接下来三小节会具体阐明。
2.1
数据划分
要点 1:划分训练-开发-测试,数据少可按传统的 60/20/20 划分,数据多可按的 98/1/1 划分。对开发集来说,具体百分比要看它是否能区分不同算法的指标 (比如精度)。
在大数据时代前,当样本数量不多 (小于一万) 的时候,通常将训练-开发-测试的比例设为 60/20/20;比如 10,000 个数据被随机分成 6,000 个用于训练,2,000 个用于开发,2,000 个用于测试。
在大数据来临时,当样本数量很多(百万级别) 的时候,通常将训练-开发-测试的比例设为 98/1/1;比如 1,000,000 个数据个数据被随机分成 980,000 个用于训练,10,000 个用于开发,10,000 个用于测试。
对开发集理数据数量的设定,应该遵循的准则是该数量能够检测不同算法或模型的区别,以便选择出更好的模型。比如模型 A 和 B 的精度是 90% 和 90.1%,两者差 0.1%。那么开发集
100 个数据不够,100×0.1% = 0.1 个数据,无法分辨 A 和 B 的差异
1,000 个数据也不够,1,000×0.1% = 1 个数据,较难分辨 A 和 B 的差异
10,000 个数据够了,10,000×0.1% = 10 个数据,容易分辨 A 和 B 的差异
对于测试集数据数量的设定,传统上是全部数据的 20% 到 30%;在大数据时代,我们不再用百分比,而是设定一个绝对数值,比如 1,000 到 10,000 个。
要点 2:训练集、开发集和测试集的数据要来自同一分布。
首先训练集和开发集的数据要来自同一分布,如果在 P 分布训练集上训练,又在 Q 分布开发集上调参,效果明显不会好。
其次训练集和测试集的数据要来自同一分布,要不然训练误差和真实误差 (通常认为是测试误差) 之间的霍夫丁不等式不成立,那么整个计算学习理论也站不住脚了。
最后开发集和测试集来源于同一分布。如果它们不来自同一分布,那么我们从开发集上选择的最佳模型往往在测试集上不会表现很好。举个例子,我们在开发集上找到最接近靶心的箭,但是测试集的靶心却远远偏离开发集的靶心,结果这支箭肯定无法射中测试集的靶心。
下图总结了上面所有内容。
2.2
指标选取
要点 1:单值评价指标有助于比较不同模型的优劣,快速选择最优模型。
大神举了个查准 (precision) 和查全 (recall) 的例子,如下表,A 比 B 全,B 比 A 准,那么该选哪个呢?你会发现当多个指标好坏不一致时,做决定不是那么容易。这时用 F1 分数将两者求调和平均,得知 A 比 B 高,选 A!

我来举个更实际也更接地气 (如果你是 NBA 球迷) 的例子。每年 NBA 会评选 MVP,都会看每个球员的各项统计,比如得分、篮板、助攻等。

光看各项统计很难决定 MVP 给谁,比如哈登得分和抢断最多,勒布朗最均衡,维斯布鲁克篮板助攻最多而且场均三双,如何做决定。用一个单值的效率指标 (Player Efficiency Rating, PER),PER 是 ESPN 专栏作家 John Hollinger 提出来的,计算公式如下

公式很复杂,我们也需要关注细节,只需了解这个 PER 将得分、篮板、助攻、盖帽、抢断和其他很多因素综合起来得到一个单值指标 (single metric)。这样看哈登的效率 29.87 最高,MVP 应该颁给他。
大神和我举的例子都说明了评估多项指标而决定时不容易,用简单平均或者复杂公式得出一个单值指标会有效快速的做出决定。
要点 2:有时把综合所有指标构成单值评价指标很困难,可以把某些性能作为优化指标 (Optimizing Metric) 找最优值;而某些性能作为满意指标 (Satisficing Metric)满足特定条件即可。
大神举了个精度和运行时间的例子,如下表,A 最快但精度最低,C 最慢但精度最高,B 则在中间。通常很难给一个函数来综合精度和运行时间,我们可以根据自身需求来选择模型。

如果
你 (一般人) 接受一定的运行时间 (100ms 之内) 来最大化精度,选 B
你 (土豪) 接受一定的运行时间 (2000ms 之内) 来最大化精度,选 C
你 (精度凡人) 接受一定的精度 (89% 以上) 来最小化运行时间,选 A
你 (精度狂人) 接受一定的精度 (99% 以上) 来最小化运行时间,选 C
接受的指标称为满意指标 (Satisficing Metric),而最大化或最小化的指标称为优化指标 (Optimizing Metric)。
继续刚才 NBA 选 MVP 的例子,有人会说效率高有什么用,带队赢球才是王道。没错,效率再高战绩倒数,你充其量就是个数据刷子 (参考 2010 年森林狼的凯文乐福)。考虑球队战绩后的表格如下,

把战绩当成满意指标,比如
所处球队 60 胜以上,效率最高的球员,只有哈登!
所处球队 50 胜以上,效率最高的球员,只有哈登!
所处球队 40 胜以上,效率最高的球员,是哈登 > 勒布朗 > 维斯布鲁克
所处球队 30 胜以上,效率最高的球员,可能还有别人,但是 30 胜能拿 MVP?
综上所述,今年 MVP 非我大火箭的大哈登所属!哇哈哈哈!
大神和我举的例子都说明了如果多项指标没有一个简单的函数来综合,选用满意指标来筛选,再用优化指标来排序。注意,满意指标可能不止一个,但是优化指标一定只有一个!
2.3
迭代实施
要点 1:开始新系统要快速进入迭代过程,先有各种思路,再用代码实现,再做试验看那些思路可行。该迭代过程越快,进度越快。
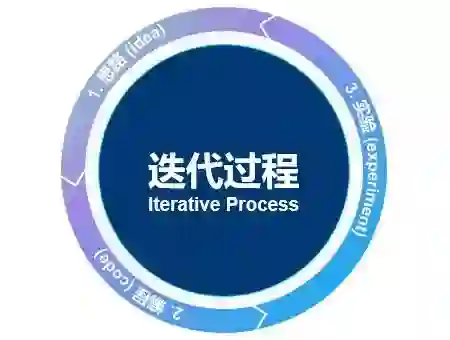
“想思路– 写代码– 做试验”是一个迭代过程,做试验需要对比哪个模型在开发集和测试集上的表现好,因此快速划分开发集和测试集,快速制定单值指标是非常重要的。
要点 2:当发现原先设定的开发集、测试集或指标没有指向正确的方向,赶快换!
大神给的建议,快速划分开发集和测试集,快速制定指标,赶快开始做项目,不要多想 (overthink),但是有时开发集、测试集和指标可能是不完美的,如果出现以下三种情况,大神建议赶快换它们。
情况一:开发集和测试集用的是网上高清图片,真实环境是手机拍的模糊图片。

解决方案:收集从手机拍的照片放入开发集和测试集。
情况二:模型在开发集的表现比在测试集的表现好,这是过拟合开发集的信号。有句话说得好,当你过度折磨数据,数据会投降。
解决方案:用一个大一点的开发集,或者换一个新的开发集。
情况三:两个猫分类器 A 和 B,精度分别是 97% 和 95%,但是 A 会错将色情图片分类成猫,而 B 不会这样。从进度角度来说,A 模型好,但从用户角度来说,一定是 B 模型好。
解决方案:改变之前单纯使用错误率作为评价标准,例如增加色情图片的权重,增加其被误分类的代价。代价函数改进如下:

当图片 i 是色情图片时,权重 i 放 10,当图片 i 是非色情图片时,权重 i 放 1。
深度学习研究人员都愿意编写程序实施想法,而很少愿意手动做误差分析。他们认为这是浪费时间,其实通过误差分析可以权衡具体问题、优先安排项目、指出新的方向,而用在上面的时间可以帮助你节省很多时间和人力。
3.1
人工分析
要点:人工错误分析能够避免花费大量的时间精力去做一些对提高模型性能收效甚微的工作,而专注解决影响模型正确率的主要问题。
对于一个猫分类器模型,我们发现该模型会将一些狗的图片错误分类成猫。在扩大狗的样本之前 (可能花数月),我们可以手动做一下分析,统计一下全部错误样例里面多少个是狗就可以了。
假设猫分类器模型的错误率是 10%,有 100 个误分类数据。
情况一:有 5 个样例是狗,即便它们全部分类正确,错误率也仅仅从 10% 减少到 9.5%,不值得去做。
10% - 5/100 = 9.5%
情况二:有 50 个样例是狗,如果它们全部分类正确,错误率却可以从 10% 减少到 5%,值得去做。
10% - 50/100 = 5%
3.2
并行分析
要点:并行分析统计误差类别,解决占百分比最大的问题。
误差分析还同时评估多个影响模型性能的因素,通过各自在错误样本中所占的比例来判断其重要性。例如,猫分类器模型中,可能有以下改进模型的因素:
把狗误以为猫的图片
把大型猫科动物 (比如狮子、豹子) 误以为猫的图片
模糊的图片
用表格来并行分析误分类图片,以单个错误分类样本为对象,分析每个样本错误分类的原因。

注意每张图片需要改进的因素不止一个,比如图片 3 是雨天拍的狮子,那么“猫科动物”和“模糊”一栏下都打钩了。因此最后一列的百分比加起来并不等于 100%。
通常来说,比例越大,影响越大,越应该花费时间和精力着重解决这一问题。这种误差分析让我们改进模型更加有针对性,从而提高效率。从上例来看,把精力放在改进“猫科动物”和“模糊”类图片比放在“狗”类图片,要明智的多。
3.3
标记修正
要点:在用深度学习时,在训练集上标记如果是随机标错,可忽略,如果是系统标错,要修正。在开发集和测试集上,用并行分析那一套。
监督式学习中,训练样本有时候会出现输出 y 标记错误的情况。下图红框的可爱的白狗狗被人工错误的标记成了猫。

如果这些标记
是随机标错 (比如不小心错误,或按错分类键) 的,那么深度学习算法对这种随机误差的鲁棒性是较强的,一般可以忽略无需修复。
是系统标错 (比如认为白色可爱的狗就是猫) 的,那么深度学习算法对这种系统误差的鲁棒性是较差的,需要修正标记。
在开发集上,用并行分析那一套,将“错误标记”作为一个可以改进误差的因素。如下图:

情况一:假设开发误差为 10%,即便它们全部分类正确,错误率也仅仅减少0.6%,有 94% 的别的误差更需要先解决。
6% ×10% = 0.6%
(10% - 0.6%) / 10% = 94%
情况二:假设你不停改进模型,直到开发误差为 2%,那么这个 0.6% 就占现在总误差的 30%了,值得投入精力来解决。
0.6% / 2% = 30%
在测试集上用上面同样的方法。大神在他的书里提了两条建议:
用同样过程对待开发集和测试集,保证它们里的数据在修正后还是来自同一分布
注意那种一开始标记错误的,而且也预测错误的数据。因为错错得对,因此也需要检查这类数据
3.4
大开发集
要点:当开发集大时,分成两个子集,一个用来分析误差,一个用来调参防止过拟合。
如果开发集很大,在分析误差时,可以将其分成两个子集 A 和 B。只看一个子集 A,做误差分析改进错误,因此 A 会慢慢被过拟合,这时用 B 来调超参数。
子集 A 称为鹰眼开发集 (Eyeball dev set),你只能用眼睛看这部分的数据来分析误差。
子集 B 称为黑箱开发集 (Blackbox dev set),你只能用这部分未知的数据来调参数。
问题一:为什么花功夫分鹰眼开发集和黑箱开发集?
回答:就是怕过拟合整个开发集。
问题二:这两个开发集的数据量应该多少?
回答:根据主要误差率和错分类个数决定。比如误差率 5%,而通常 50 到 100 个错分类数据可以让你很容易识别主要错误来源 (比如模糊,比如大型猫科动物),那么需要的鹰眼开发集大概包含 1,000 (50/5%) 到 2,000 (100/5%) 个数据。对于黑箱开发集,1,000 到 10,000 个数据都是合理的。
大神强调,如果开发集数目不是那么大,鹰眼开发集更重要些,这是不需要黑箱开发集,那么误差分析和调参都在它上面做。
回答本帖要解决的问题:
问:用完机器学习后效果不好怎么办?
答:用正交策略模型在训练集、开发集、测试集和真实环境上的表现,对症下药。
问:在项目之前如何设定有效的目标?
答:
数据多时按 98/1/1 来划分训练集、开发集和测试集;
快速制定开发集和测试集,保证它们同分布
选择单值评估指标 (用函数综合或满意和优化指标)
发现以上开发集、测试集和评估指标和项目期望的方向不一致时,赶快换它们
问:如何有效的进行误差分析?
答:
手动分析误差,并行找出可改进它的原因,根据其占比分配精力去做
根据错误标记的特性,或者占比,来决定修正或忽略
对大开发集,将其分成两个子集,一个用来误差分析,一个用来调参
最重要的是在做项目时记住下图:







