【代替反向传播】终极算法作者提出另一种深度学习:离散优化

【AI WORLD 2017世界人工智能大会倒计时 6 天】
AI World 2017世界人工智能大会终极指南:嘉宾演讲与议程
即将于2017年11月8日在北京国家会议中心举办的AI World 2017世界人工智能大会上,我们邀请到微软全球资深副总裁,微软(亚洲)互联网工程院院长王永东发表演讲,他将介绍《未来AI的点定义》。此外,在计算机视觉这一领域,阿里巴巴副总裁、iDST副院长华先胜,旷视科技Face++首席科学家、旷视研究院院长孙剑博士,腾讯优图实验室杰出科学家贾佳亚教授,以及硅谷知名企业家、IEEE Fellow Chris Rowen等多位领袖将共论人脸识别等前沿技术。
抢票链接:http://www.huodongxing.com/event/2405852054900?td=4231978320026
大会官网:http://www.aiworld2017.com
新智元编译
作者:Abram L. Friesen and Pedro Domingos
编译:马文
【新智元导读】在 Hinton 的 Capsule 之后,越来越多的研究者开始探讨反向传播之外的方法。《终极算法》作者、华盛顿大学教授Pedro Domingos和同事Abram L. Friesen今天在arxiv发布的论文《Deep Learning as a Mixed Convexcombinatorial Optimization Problem》就提出了一种使用离散优化,而非反向传播的深度学习方法。
论文地址:https://arxiv.org/pdf/1710.11573.pdf

1986年,Hinton等人合著的论文《通过反向传播错误学习表征》(Learning representations by back-propagation errors),首次将反向传播算法引入多层神经网络训练,为大型复杂神经网络的应用奠定了基础。40年后,反向传播算法已经成为如今这一波人工智能爆炸的核心。
今天我们在AI领域所看到的进步,包括图像分类和语音识别,背后的主力都是反向传播。在反向传播中,标签(label)或“权重”(weight)被用于表示类似于大脑的神经层里的照片或声音,然后逐层对权重进行调整,直到网络能够以尽可能少的错误实现一个智能的功能。
但Hinton却表示,要想让神经网络变得智能,需要放弃反向传播。他在此前的一次采访中说:“我不认为这(反向传播)是大脑运作的方式,我们的大脑显然不需要对所有数据进行标注。”
现在,越来越多的研究者开始探讨反向传播之外的方法。《终极算法》(The Master Algorithms)作者、华盛顿大学教授Pedro Domingos和同事Abram L. Friesen今天在arxiv发布的论文《Deep Learning as a Mixed Convexcombinatorial Optimization Problem》就提出了一种使用离散优化,而非反向传播的深度学习方法。

摘要
随着神经网络变得更深、更广泛,具有hard-threshold激活的学习网络不管对于网络优化还是对于创建深度网络的大型集成系统都越来越重要。对于网络优化,可以大大减少时间和能量需求;对于创建网络的大型集成系统,这些系统可能具有不可微的组件,而且为了有效学习,必须避免梯度消失和梯度爆炸。但是,由于梯度下降不适用于硬阈值函数(hard-threshold function),因此不清楚如何学习它们。我们通过观察发现为hard-threshold隐藏单元设置target以最小化损失是一个离散优化(discrete optimization)问题,并且可以这样解决。离散优化的目标是找到一组target,以使得每个单元,包括输出,都有一个线性可分离的问题来解决。有了这些target,网络可以分解成单个的感知器(perceptron),然后可以用标准的凸方法(convex approaches)来学习。在此基础上,我们开发了一个递归mini-batch算法,用于学习深度hard-threshold网络,其中作为特例,包括一个straight-through estimator。实验证明,我们的算法与straight-through estimator相比,在一系列设置中都提高了分类的精确度,包括在ImageNet的AlexNet和ResNet-18。
最初的神经分类方法是学习具有hard-threshold激活的单层模型,例如感知器(Perceptron)。但是,很难将这些方法扩展到多层的模型,因为hard-threshold单元几乎处处都有零导数而且原点处不连续,不能通过梯度下降来训练。相反,研究社区转向具有soft activation 函数的多层网络,例如sigmoid,以及最近的ReLU,它们可以通过反向传播有效计算梯度。
这种方法取得了显著的成功,使研究人员能够训练数百层的网络,并学习在各种任务上比以往任何方法的精确度都要高得多的模型。但是,随着网络越来越广泛,使用hard-threshold激活来进行量化的趋势更显著,这样网络可以实现二进制或低精度的推断和训练,可以极大地减少现代深层网络所需要的能耗和计算时间。除了量化,hard-threshold单元的输出规模与输入规模无关(或不敏感),这可以缓解梯度消失和梯度爆炸的问题,并有助于避免在反向传播低精度训练中出现的一些病态问题。避免这些问题对于开发大型网络系统至关重要,这些系统可以用来执行更复杂的任务。
基于这些原因,我们对开发一种用于学习具有hard-threshold单元的深度神经网络的有效技术很感兴趣。在这项工作中,我们提出一个学习深度hard-threshold网络的框架,该框架源于hard-threshold单元输出离散值的观察结果,这表明组合优化可能为训练这些网络提供一种有原则性方法。通过为每个隐藏层激活指定一组离散目标(discrete targets),该网络可以分解为许多单独的感知器,每个感知器都可以很容易地接受它的输入和目标。因此,学习一个深度hard-threshold网络的难度在于设定目标,使每一个训练的感知器——包括输出单元——都有一个线性可分的问题来解决,进而达成目标。我们展示了证明这一方法可行的网络,可以利用混合凸组合优化框架学习。
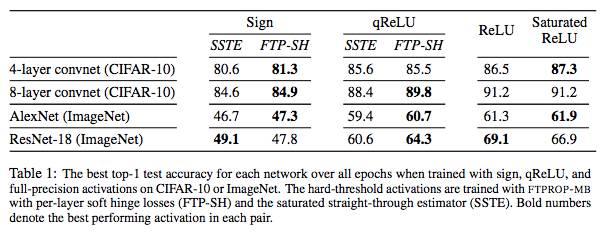
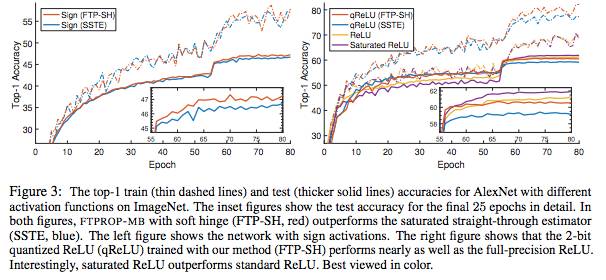
在此框架下,我们开发了一种递归算法,我们称之为 feasible target propagatio(FTPROP),用于学习deep hard-threshold network。由于这是一个离散优化问题,我们开发了基于每层损失函数设置目标的启发式方法。 FTPROP的mini-batch版本可以用来解释和证明 straight-through estimator(Hinton, 2012; Bengio et al., 2013),它可以被看作是FTPROP 的一个特例,对于每层损失函数和目标启发式具有特定的选择。最后,我们开发了一种新的损失函数,它可以改善deep hard-threshold network的学习。在实验中,我们证明与STE相比,FTPROP-MB提高了CIFAR-10和ImageNet的多个模型的分类精度(上图)。
更多研究方法和细节,请查阅原论文。
在这项工作中,我们提出了一种新型混合凸组合优化框架,用于学习具有hard-threshold单元的深层神经网络。组合优化用于为hard-threshold隐藏单元设置离散目标,使得每个单元仅有一个线性可分离的问题要解决。然后,网络分解成单个感知器,给定这些目标,可以用标准的凸方法学习。基于此,我们开发了一种用于学习深度hard-threshold网络的递归算法,我们称之为可行目标传播( feasible target propagation ,FTPROP),以及一个高效的mini-batch版本(FTPROP-MB)。我们证明了常用但不太合理的straight-through estimator(STE)是FTPROP-MB的特殊情况,这是由于在每个层使用饱和hinge loss和我们的目标启发式(target heuristic)引起的。最后,我们定义了soft hinge loss,并表明与STE相比,在每一层具有soft hinge loss的FTPROP-MB提高了CIFAR-10和ImageNet的多个模型的分类精度。
在未来的工作中,我们计划通过研究我们的框架、约束满足和可满足性之间的关系,开发新的目标启发式(target heuristic)和层损失函数。我们还打算进一步探索具有hard-threshold单元的深度网络的优势。特别是,虽然最近的研究展现出它们减少计算和能源需求的能力,但它们也需要减少被梯度消失和梯度爆炸影响,以及受到covariate shift和对抗样本的影响。
11月8日,欢迎来新智元世界人工智能大会,深入了解AI 技术进展和产业情况,马上抢票!

【AI WORLD 2017世界人工智能大会倒计时 6 天】点击图片查看嘉宾与日程。
抢票链接:http://www.huodongxing.com/event/2405852054900?td=4231978320026
AI WORLD 2017 世界人工智能大会购票二维码:



