学界 | CoRL 2018最佳系统论文:如此鸡贼的机器手,确定不是人在控制?
作者:Dmitry Kalashnikov 等 来源:arXiv,机器之心
1 引言
与物体进行交互的操作是机器人技术中最大的开放问题之一:在开放的世界环境中智能地与以前没有见过的物体进行交互需要可以泛化的感知、基于视觉的闭环控制和灵巧的操作。强化学习为解决这一问题提供了一个很有前景的途径,目前强化学习方向上的工作能够掌握如击球 [1],开门 [2,3],或投掷 [4] 这样的单个技能。为了满足现实世界中对操作的泛化需求,我们将重点关注离策略算法的可扩展学习,并在具体抓取问题的背景下研究这个问题。虽然抓取限制了操作问题的范围,但它仍然保留了该问题中许多最大的挑战:一个抓取系统应该能够使用真实的感知技术可靠、有效地抓取之前没有见过的物体。因此,它是一个更大的机器人操作问题的缩影,为对泛化和多样化的物体进行交互提供了一个具有挑战性和实际可用的模型。
现有的很多机器人抓取工作都将任务分解为感知、规划和行动阶段:机器人首先感知场景并识别合适的抓取位置,然后规划到达这些位置的路径 [5,6,7,8]。这与人类和动物的抓取行为不同,人和动物的抓取行为是一个动态过程,在每个阶段都紧密交织着感知和控制行为 [9,10]。这种动态闭环的抓取很可能对不可预测的物体物理属性、有限的感知信息(例如,单目摄像机输入而非深度)和不精确动作的鲁棒性更强。为长期成功而训练的闭环抓取系统也可以执行智能的预抓取操作,例如推倒或重新调整物体的位置以更容易地抓取物体。然而,闭环抓取控制的一个主要挑战是,感知运动循环必须在视觉模式上封闭,而在新的环境设置下很难有效地利用标准最优控制方法。
更多演示:https://sites.google.com/view/qtopt
本文研究了离策略深度强化学习如何能够利用完全自监督的数据采集方法,获取闭环的动态视觉抓取策略,从而泛化到测试时没有见过的物体上。底层末端执行器的运动值是直接从摄像机观测的原始结果中预测出来的,整个系统在现实世界中使用抓取尝试进行训练。虽然深度强化学习的原理在几十年前就已经被大家知晓 [11,12],但将其应用到一个能够泛化到新物体上的实用机器人学习算法中,则需要一个稳定、可扩展的算法和大型数据集,以及仔细的系统设计。

图 1:实验设置了 7 个机器人,在自动的自监督情况下收集抓取片段。
我们实验中的实现做了非常简单的假设:观测结果来自于机器臂上方的单目 RGB 摄像机(见图 2),动作由末端执行器的笛卡尔运动和夹持器开闭命令组成。强化学习算法在成功抓起一个物体时得到二值奖励(正或负),而没有其它奖励形式。这一系列的假设使得这种方法可以大规模部署,让我们能够在 7 个真正的机器人组成的系统上收集到 580k 的抓取尝试数据。与文献 [13,14] 中的大多数强化学习任务不同,该任务的主要挑战不仅是需要最大化奖励,而且要有效地将该方法泛化到以前没有见过的物体上。这需要在训练过程中使用非常多样化的物体。
为了最大限度地利用这种多样化的数据集,我们提出了一种基于 Q-learning 的连续动作泛化的离策略训练方法,我们称之为 QT-Opt(通过优化实现 Q-function 的目标)。QT-Opt 不同于其它的连续动作 Q-learning 方法 [15,16],后者通常由于 actor-critic 的不稳定性而不稳定 [17,18],QT-Opt 不需要训练一个显式的 actor,而是使用对 critic 的随机优化来选择动作和目标值 [19,20]。我们的研究表明,即使完全采用离策略训练,也能超越基于先前研究的强基线,而通过适度的在线策略调优,可以将具有挑战性的、对之前没有见过物体的抓取成功率提高到 96%。

图 2:我们实验环境下的机器人单元的特写(左图)和大约 1000 个视觉和物理特征上不同的训练对象(右图)。每个单元(左)由一个 KUKA LBR IIWA 机器臂、具有两个手指的夹持器和一个放置在机器臂上方的 RGB 摄像机组成。
我们的实验从数量和质量上验证了该方法的有效性。本文提出的方法在一系列训练中没有见过的物体上获得了高成功率,本文的定性实验表明,这种高成功率是由于系统采用了各种策略,如果没有基于视觉的闭环控制,这些策略是不可行的:学习到的策略表现出纠正行为、重新抓取、探索运动以确定最佳的抓取方式、重新调整不可抓取物体的位置,以及其它只有在抓取作为一个动态的闭环过程时才可行的特性。
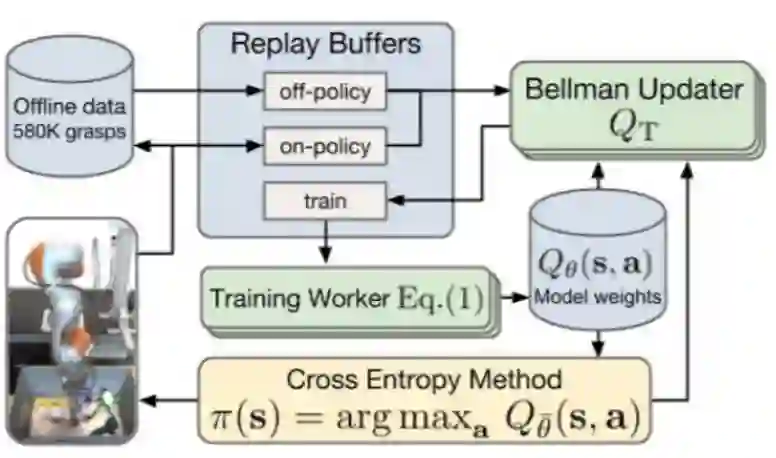
图 3:QT-Opt 的分布式强化学习的基本结构(参见 4.2 节)。该模型将从离线数据中加载「状态-动作-奖励」三元组,这些离线数据是从在线机器人集合中获得并存储下来的(参见第 5 小节)。
论文:QT-Opt: Scalable Deep Reinforcement Learning for Vision-Based Robotic Manipulation

论文地址:https://arxiv.org/pdf/1806.10293.pdf
摘要:在本文中,我们使用一种可扩展的强化学习方法研究了学习基于视觉的动态操作技能的问题。我们在抓取行为的背景下研究了这个问题,这是机器人操作中一个长期存在的挑战。
与选择一个抓取点,然后执行预期的抓取动作的静态学习行为不同,我们的方法实现了基于视觉的闭环控制,机器人根据最近的观测结果不断更新抓取策略,以优化长期的抓取成功率。为此,我们引入了 QT-Opt,这是一个可扩展的基于视觉的自监督增强学习框架,它可以利用 580k 的现实世界尝试抓取的数据来训练一个带有 1.2M 参数的深度神经网络 Q-function,从而执行闭环的真实世界的抓取行为,该方法可以以 96% 的成功率泛化到对没有见过的物体的抓取行为上。
除了获得了非常高的成功率,我们的方法还表现出与更标准的抓取系统相比截然不用的性质:在只使用机器臂上的摄像头基于视觉的 RGB 感知的情况下,我们的方法可以自动学习到在物体掉落后重新抓取物体的策略、对物体进行探测从而找到最有效的抓取方式、学习调整物体的位置并且对其它不能抓取的物体上进行预抓取操作、对动态的干扰和扰动作出响应。

表 1:测试物体抓取成功率的定量结果。将使用物体替换(test)和不使用物体替换(bin emptying)两种情况下的指标来评估策略,后者会显示前 10、20 和 30 次抓取中的成功率。我们的方法的变体使用了在线策略调优,它的失败率比先前测试集上的工作低了四倍多,但却使用了更少的抓取尝试进行训练。只使用离策略训练的变体也大大超过了先前方法的性能。

图 4:QT-Opt 策略中的八种抓取场景,展示了我们的方法发现的一些策略:预抓取操作(a,b),抓取调整(c,d),抓取动态物体和从干扰中恢复(e,f),在混乱场景中抓取物体(g,h)。



