在线教育场景下的学生退课行为预测,一直是机器学习(ML)与教育(EDU)交叉领域内较为火热的研究课题。
近年间,针对该方向的研究对象大多集中为大规模开放性在线课程(Massive Open Online Course, MOOC)的学生,通过收集 MOOC 平台上学生近期平台登录记录与相关网页埋点反馈数据,研究人员制作相关特征向量并结合机器学习模型算法,如Simple Logistic Regression、Gradient BoostingDecision Tree、Iterative Logistic Regression 等,对存在退课高风险的学生进行预测。
不同于针对MOOC平台学生的预测,当前研究领域对 K12 在线教育平台的学生退课预测还处于初期探索阶段。除此之外,在线 K12 教育平台的数据类型与 MOOC 平台数据相比存在更多模态,例如 K12 教育平台的学生在课前课后与平台顾问直接会产生沟通记录、课程进行过程中也会有相应的音视频记录等。因此,先前关于 MOOC平台的退课预测研究的方法与结论很难直接用于 K12 在线教育场景。
针对这些问题与特点,在2019年初,我们使用某K12在线教育1对1平台2018年秋冬季学期的学生历史行为数据,对K12在线场景的学生退课预测问题进行了探索与尝试,在研究的过程中我们从多种模态数据出发,共计挖掘了超过80种与学生退课行为相关的特征变量,并根据学生退费意愿的时效性假设提出了多种数据增强的算法,最终取得了单日预测AUC超过80%的结果。
基于该研究实践成果产出的论文发表于Educational Data Mining(EDM2020)学术会议,论文标题为"Identifying At-Risk K-12 Students in Multimodal Online Environments: A Machine Learning Approach"。
论文链接:https://arxiv.org/abs/2003.09670
对于退课学生预测问题的定义,我们参考了部分先前关于MOOC平台学生退课研究中所使用的定义方法,并在其基础上结合K12教育场景的特点对预测结果的预知性(multi-step ahead)要求进行了一定的修改,具体表现内容如下:给定单个学生s,
![]() ,与其在平台内所有活动的历史记录序列
,与其在平台内所有活动的历史记录序列
![]() ,
,
![]() ,
,![]() ,其中
,其中
![]() 表示学生s在
表示学生s在
![]() 时间点上的事件特征向量,
时间点上的事件特征向量,
![]() 和
和
![]() 分别表示学生s的历史活动特征向量集合与其按一定步长采样(24小时)所产生的时间点集合。相应的,我们定义
分别表示学生s的历史活动特征向量集合与其按一定步长采样(24小时)所产生的时间点集合。相应的,我们定义
![]() 表示学生s在平台上,
表示学生s在平台上,
![]() 时间点之前每个时间采样点j对应是否是退课的状态标签。另外,由于在真实场景下关于学生的退课预测的最终目的是通过提前干预挽回学生,因此模型的预测结果需要具有先决性:即令
时间点之前每个时间采样点j对应是否是退课的状态标签。另外,由于在真实场景下关于学生的退课预测的最终目的是通过提前干预挽回学生,因此模型的预测结果需要具有先决性:即令
![]() 表示提前预测的时间间隔长度,
表示提前预测的时间间隔长度,
![]() 表示在
表示在
![]() 时间后,模型给出关于学生退课概率的预测。
时间后,模型给出关于学生退课概率的预测。
针对在线K12学习平台退课行为的特点,我们从3个学生活动记录的方面出发:(1)课内行为、(2)课外行为与(3)动态行为,思考并制作了对应相关的特征,下面我们将对每个方向的特征进行相关说明:
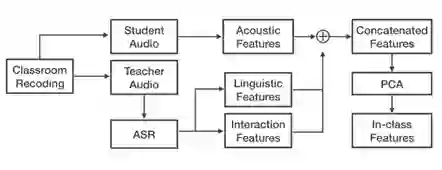
课内行为特征重点关注学生在线上课堂内的各种行为表现,通过观察学生的课内行为表现数据,例如说话次数、说话内容,我们可以分析得到学生对于该节课的参与程度从侧面反映出学生对于当前在线课程的满意情况。关于课内行为特征的提取流程如下:
![]()
(1)我们将课堂内老师与学生的语音数据从课堂录像中提取出来;(2)使用opensmile音频特征提取工作将课堂中的声学特征(Acoustic Features);(3)使用语音文本转录工具(ASR)将老师与学生课内对话转录成为文字;(4)使用课堂文本特征提取工具提取课堂内师生互动与语音行为相关特征;(5)将上述特征连接合并后使用PCA降维得到最终的低维课内特征向量;
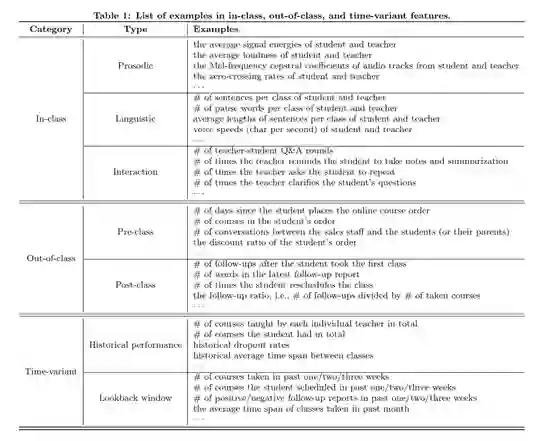
在线K12平台在记录学生上课过程的同时,在后台也会记录许多关于学生在课外过程中在平台上的各类活动,其中包括:学生在正式上课前咨询课程的记录、学生在课后与顾问老师交流的记录等;从这些记录中,我们共挖掘约40维相关特征,覆盖学生售前的沟通次数、学生在平台购买课程的体量等等,具体关于这些特征的详细信息我们已展示在后续表格中;
学生在课程进行中有部分行为事件存在较强的动态性,例如学生近期预约课程及销课的频率、学生历史预约课程与销课的频率、以及近期学生预约与销课评率变化情况等;针对这些行为特征的挖掘,我们可以了解关于学生近期对于课程参与度与满意程度的变化,从而更好地了解其近期对平台及学习效果整体的满意状态;关于这部分特征的详细信息我们与其他两类特征一同展示在以下表格中:
![]()
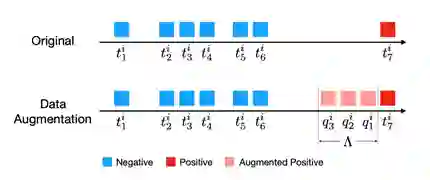
在传统方法中,针对学生退课研究的数据的打标方法主要根据退费时间进行标记,即只标记退费学生的退费当天作为正样本(Positive),剩余的所有的样本被标记为负样本(Negative);但是使用这种标注方法会使数据产生样本不平衡(data imbalance)的问题,同时由于只使用退课学生退费当天的样本作为正样本,会使模型缺失我们想要的预知性特点,即只能检测退费当天的学生。为了解决上述问题,我们提出了一种基于重采样(over sampling)改进的数据增强方法,具体做法如下图所示。
![]()
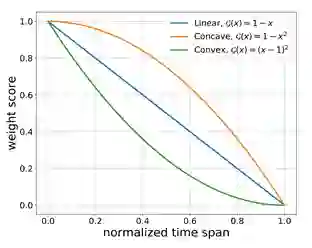
首先我们选定一个 作为扩展区间,我们将样本的正例扩展到 至 的区间;同时出于对于一般学生的退课影响近期性假设(Recency Effect),即我们认为越接近学生的退课点,学生的退课确定性越强。因此,为了强调这些接近退课时间点的样本的重要性,我们除了对正样本进行扩展还对这些扩展样本进行非平均重采样,即每个样本在重采样过程中出现的概率与其距离学生退课时间点的距离成反比:离退课时间点越近其对应重采样概率越高。在我们的实验中,我们尝试了3种不同的函数对该反比函数进行模拟:
![]()
在模型训练过程中我们使用5折交叉验证的方法对模型的参数进行选取,同时为了保证交叉训练过程中的准确性,我们在学生维度对训练数据进行划分,即属于某个学生的所有样本都将被整体划入训练或验证集,具体训练的详细流程如下:
![]()
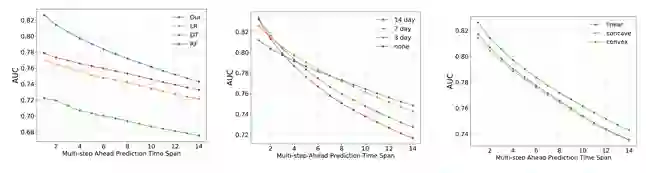
我们的实验共计使用了2018年8月至2019年2月期间在第三方K12线上1对1教学平台上进行学习的3922名学生的相关数据,其中634名学生选择了退课,平均每位学生的学习时间总长度为86天,因此在我们的数据集中共包含338428个观察样本作为我们最终的实验数据集。同时,为了同时验证模型的准确性与预见性,因此我们除了会对模型的预测结果进行当日预测结果检验,同时也会对模型在1~14天内的预测结果进行结果指标计算。在评价模型准确性的方面,我们使用AUC作为我们模型的比较指标,下面我们将逐项对模型结果进行分析:
![]()
我们分别从3个方面对模型的性能进行了分析:从图1看出我们提出的模型在1~14天的预测任务上与其他模型相比都能有更优结果;从图2看出我们的数据增强方法与不使用数据增强相比为模型带来了明显的提升,除此以外当我们将正例扩展区间定为7天时,其提升效果在1~14天的整体预测结果上最为明显;从图3我们可以看出,与linear与concave函数相比convex函数对应的数据增强方法对模型的提升更大;在下面的表格中,我们展示了不同特征对模型的性能的影响,从结果可以看出3个方面的特征都对模型有正面的作用,同时课外类特征>动态类特征>课内类特征;
![]()
除了对离线数据进行实验,我们还将该预测模型部署于线上并于2019年2月至2019年4月期间对该模型进行在线测试。我们使用模型在每日早间6点对在线平台内的所有处于正常上课的学生进行退课概率预测,将退课概率最高的30%学生列为重点关注对象。在隔天的退课学生名单中,我们发现平均约70%的退课学生都出现在前一天被预测的重点关注对象列表中。
[1] L. Zhang and H. Rangwala. Early identificationof at-risk students using iterative logistic regression. In InternationalConference on Artificial Intelligence in Education, pages 613–626. Springer,2018.
[2] F. D. Pereira, E. Oliveira, A. Cristea, D.Fernandes, L. Silva, G. Aguiar, A. Alamri, and M. Alshehri. Early dropoutprediction for programming courses supported by online judges. In InternationalConference on Artificial Intelligence in Education, pages 67–72. Springer,2019.
[3] L. Wood, S. Kiperman, R. C. Esch, A. J. Leroux,and S. D. Truscott. Predicting dropout using student-and school-level factors:An ecological perspective. School Psychology Quarterly, 32(1):35, 2017.
[4] W. Xing, X. Chen, J. Stein, and M.Marcinkowski. Temporal predication of dropouts in moocs: Reaching the lowhanging fruit through stacking generalization. Computers in Human Behavior,58:119–129, 2016.
[5] D. Yang, T. Sinha, D. Adamson, and C. P. Rośe. Turn on, tune in, drop out: Anticipating student dropouts in massive openonline courses. In Proceedings of the 2013 NIPS Data-driven education workshop,volume 11, page 14, 2013.
[6] J. A. Greene, C. A. Oswald, and J. Pomerantz.Predictors of retention and achievement in a massive open online course.American Educational Research Journal, 52(5):925–955, 2015.
[7] S. Lee and J. Y. Chung. The machinelearning-based dropout early warning system for improving the performance of dropoutprediction. Applied Sciences, 9(15):3093, 2019.
[8] M. Fei and D.-Y. Yeung. Temporal models forpredicting student dropout in massive open online courses. In 2015 IEEEInternational Conference on Data Mining Workshop (ICDMW), pages 256–263. IEEE,2015.
[9] C. A. Coleman, D. T. Seaton, and I. Chuang.Probabilistic use cases: Discovering behavioral patterns for predictingcertification. In Proceedings of the Second (2015) ACM Conference on Learning@Scale, pages 141–148. ACM, 2015.
[10] S. Crossley, L. Paquette, M. Dascalu, D. S.McNamara, and R. S. Baker. Combining click-stream data with nlp tools to betterunderstand mooc completion. In Proceedings of the Sixth InternationalConference on Learning Analytics & Knowledge, pages 6–14. ACM, 2016.
AI 科技评论希望能够招聘 科技编辑/记者
办公地点:北京/深圳
职务:以跟踪学术热点、人物专访为主
工作内容:
1、关注学术领域热点事件,并及时跟踪报道;
2、采访人工智能领域学者或研发人员;
3、参加各种人工智能学术会议,并做会议内容报道。
要求:
1、热爱人工智能学术研究内容,擅长与学者或企业工程人员打交道;
2、有一定的理工科背景,对人工智能技术有所了解者更佳;
3、英语能力强(工作内容涉及大量英文资料);
4、学习能力强,对人工智能前沿技术有一定的了解,并能够逐渐形成自己的观点。
感兴趣者,可将简历发送到邮箱:jiangbaoshang@yanxishe.com
击"阅读原文",直达“ICML 交流小组”了解更多会议信息。

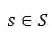 ,与其在平台内所有活动的历史记录序列
,与其在平台内所有活动的历史记录序列
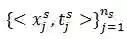 ,
,
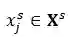 ,
,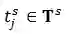 ,其中
,其中
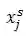 表示学生s在
表示学生s在
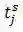 时间点上的事件特征向量,
时间点上的事件特征向量,
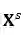 和
和
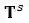 分别表示学生s的历史活动特征向量集合与其按一定步长采样(24小时)所产生的时间点集合。相应的,我们定义
分别表示学生s的历史活动特征向量集合与其按一定步长采样(24小时)所产生的时间点集合。相应的,我们定义
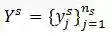 表示学生s在平台上,
表示学生s在平台上,
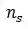 时间点之前每个时间采样点j对应是否是退课的状态标签。另外,由于在真实场景下关于学生的退课预测的最终目的是通过提前干预挽回学生,因此模型的预测结果需要具有先决性:即令
时间点之前每个时间采样点j对应是否是退课的状态标签。另外,由于在真实场景下关于学生的退课预测的最终目的是通过提前干预挽回学生,因此模型的预测结果需要具有先决性:即令
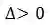 表示提前预测的时间间隔长度,
表示提前预测的时间间隔长度,
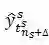 表示在
表示在
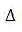 时间后,模型给出关于学生退课概率的预测。
时间后,模型给出关于学生退课概率的预测。