谷歌大脑用强化学习为移动设备量身定做最好最快的CNN模型
▲点击上方 雷锋网 关注

文 | 杨晓凡
来自雷锋网(leiphone-sz)的报道

雷锋网 AI 科技评论按:卷积神经网络(CNN)被广泛用于图像分类、人脸识别、物体检测以及其他许多任务中。然而,为移动设备设计 CNN 模型是一个有挑战性的问题,因为移动模型需要又小又快,同时还要保持足够的准确率。虽然研究人员们已经花了非常多的时间精力在移动模型的设计和改进上,做出了 MobileNet 和 MobileNetV2 这样的成果,但是人工设计高效的模型始终是很有难度的,其中有许许多多的可能性需要考虑。
受到 AutoML 神经网络架构搜索研究的启发,谷歌大脑团队开始考虑能否通过 AutoML 的力量让移动设备的 CNN 模型设计也更进一步。在谷歌 AI 博客的新博文中,他们介绍了用 AutoML 的思路为移动设备找到更好的网络架构的研究成果。
雷锋网 AI 科技评论把博文编译如下:
在谷歌的论文《MnasNet: Platform-Aware Neural Architecture Search for Mobile》中,他们尝试了一种基于强化学习范式的自动神经网络架构搜索方法来设计移动模型。为了应对移动设备的运行速度限制,谷歌大脑的研究人员们专门显式地把运行速度信息也加入了搜索算法的主反馈函数中,这样搜索到的模型就是一个可以在运行速度和识别准确率之间取得良好平衡的模型。通过这样的方法,MnasNet 找到的模型要比目前顶级的人工设计的模型 MobileNetV2 快 1.5 倍,比 NASNet 快 2.4 倍,同时还保持了同样的 ImageNet 首位准确率。
以往的网络架构搜索方法中,模型的运行速度通常是借助另一种指标进行参考(比如考虑设备的每秒运算数目),而谷歌大脑此次的方法是通过在给定的上设备上运行模型,直接测量模型的运行时间长短;在这项研究中他们使用的就是自家的 Pixel 手机。通过这种方式,他们可以直接测量出模型在真实环境运行时的具体表现,尤其是,不同型号的移动设备有各自不同的软硬件属性,仅凭运算速度这一项指标无法概括全部情况;为了达到准确率和运行速度之间的最佳平衡,所需的模型架构也会有所不同。
谷歌大脑方法的总体流程主要由三个部分组成:一个基于 RNN 的控制器用于学习模型架构并进行采样,一个训练器用于构建模型并训练模型得到准确率,还有一个推理引擎,它会在真实的手机上通过 TensorFlow Lite 运行模型、测量模型的运行速度。他们把这个任务公式化为一个多目标优化问题,优化过程中得以兼顾高准确率和高运行速度;其中使用的强化学习算法带有一个自定义的反馈函数,可以在不断的探索中找到帕累托最优的解决方案(比如,不断提升模型的准确率,同时并不会让运行速度降低)。
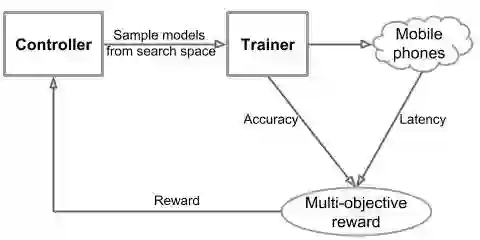
为移动设备自动搜索神经网络架构的总体流程图
对于网络架构搜索过程,为了在搜索的灵活性和搜索空间大小之间取得合适的平衡,谷歌大脑的研究人员们提出了一种新的因子分解层级化搜索空间,它的设计是把一整个卷积网络分解为一系列按顺序连接的模块,然后用一个层级化搜索空间来决定每一个模块中的层的结构。借助这样的做法,他们设计的搜索流程可以允许不同的层使用不同的操作和连接方式。同时,他们也强制要求同一个模块内的所有层都共享同一种结构,相比于普通的每一层独立搜索结构,这种做法也就把搜索空间显著减小了数个数量级。

图示为从新的因子分解层级化搜索空间中采样得到的一个 MnasNet 网络,整个网络架构中可以有多种不同的层
谷歌大脑的研究人员们在 ImageNet 图像分类和 COCO 物体检测任务中测试了这种方法的效果。实验中,这种方法找到的网络在典型的移动设备计算速度限制下达到了准确率的新高。下面图中就展示了 ImageNet 上的结果。
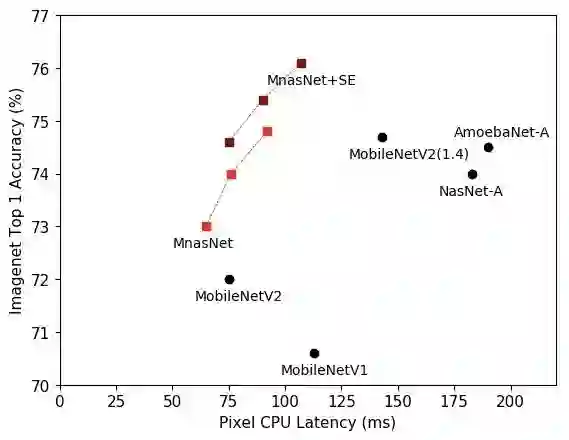
ImageNet 上的首位准确率与推理延迟对比。论文新方法找到的模型标记为 MnasNet
在 ImageNet 上,如果要达到同样的准确率,MnasNet 模型可以比目前顶级的人工设计的模型 MobileNetV2 快 1.5 倍,比 NASNet 快 2.4 倍,其中 NASNet 也是用网络架构搜索找到的。在采用了「压缩-激励」(squeeze-and-excitation)优化之后,谷歌新的 MnasNet + SE 的模型的首位准确率可以达到 76.1%,这已经达到了 ResNet-50 的水平,但却比 ResNet-50 的参数少了 19 倍,乘-加的计算操作数目也减少了 10 倍。在 COCO 上,谷歌的模型家族可以同时在准确率和运行速度上领先 MobileNet,它的准确率已经与 SSD300 模型相当,但所需计算量要少了 35 倍。
谷歌大脑的研究人员们很高兴看到自动搜索得到的模型可以在多个复杂的移动计算机视觉任务中取得顶级的成绩。未来他们计划在搜索空间中集成更多的操作和优化方法供选择,也尝试把它应用到语义分割等更多的移动计算机视觉任务中。
论文地址:https://arxiv.org/abs/1807.11626
via ai.googleblog.com,雷锋网AI 科技评论编译

关注雷锋网(leiphone-sz)回复 2 加读者群交个朋友


